
菜鸡的github链接:031802414
同时还有参考的网上大佬的代码链接:大佬
PSP表格如下:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 180 | 180 |
| Analysis | 需求分析 (包括学习新技术) | 3600 | 3000 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 90 | 90 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 90 | 120 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 30 | 60 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 4530 | 4050 |
1.计算模块接口的设计与实现过程
可以参考一下阮一峰大神的博客:tfidf
其中余弦相似度的计算公式是:
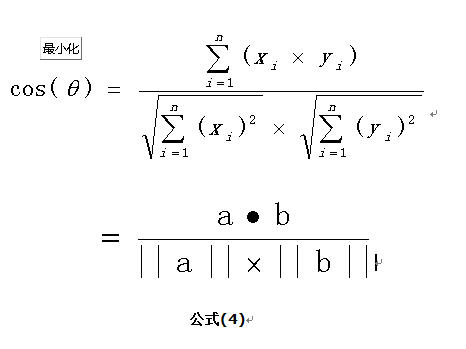
大致的流程如下:
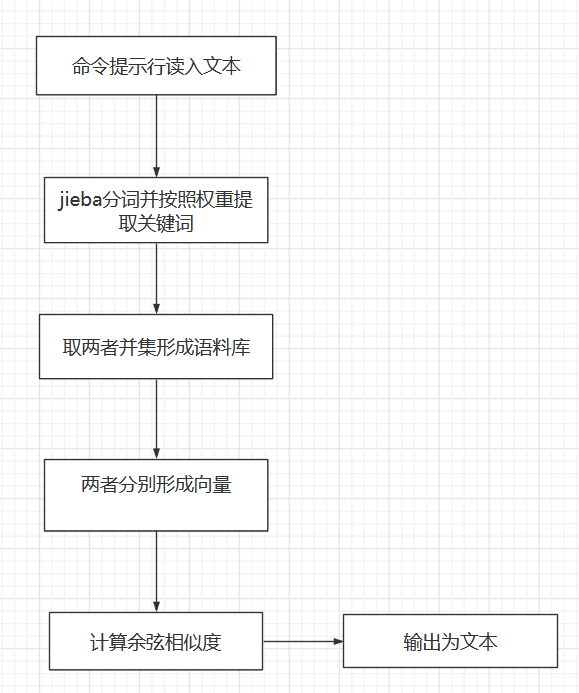
算法的主要思想以及执行的步骤
由于这个是参考网上找的大佬的代码,所以我对整个程序的封装大致延续了它的风格,
用一个类(CosineSimilarity)封装,接下来每一个步骤,为了增加程序的可读性和易用性,
基本一个步骤就是对应一个方法。其余的只是对他进行了文本输入输出的添加,还有就是对
余弦相似度的计算,原码是用了机器学习包,我是直接用了余弦相似度的公式进行计算。
大致如下
init
定义了一个对CosineSimilarity的构造,其中的两个参数只是进行两个对比的文本的传入。
extract_keyword
按照权重提取关键词。这部分主要是调用jieba库的函数方法进行操作,先用jieba.cut进行
分词,然后再用jieba.analyse按照权重提取关键字。在这里要按照权重提取关键字的原因主
要是如果语料库直接用所有分词结果,由于不能调用外部文件,停用词表也就不能引用,还有
一些其他原因,会导致该情况下长文本的检测准确率较低。面对百度编程,得知,关键词最好
不超过8%,所以对于topk我选择了12。
one_hot
这里主要是用到了onehot编码将文本向量化,对于onehot编码,其实可以不用理解。当然,
如果有兴趣的也可以参考下面这篇博客
calculate
这个方法里面主要是运用了文首的那个公式进行运算,原码中用的是机器学习,我觉得没必
要,就用自己的方法进行编写了(居然还比用机器学习跑得更快)
2.计算模块接口部分的性能改进
用了pycharm自带的profile进行分析(还好下了专业版)
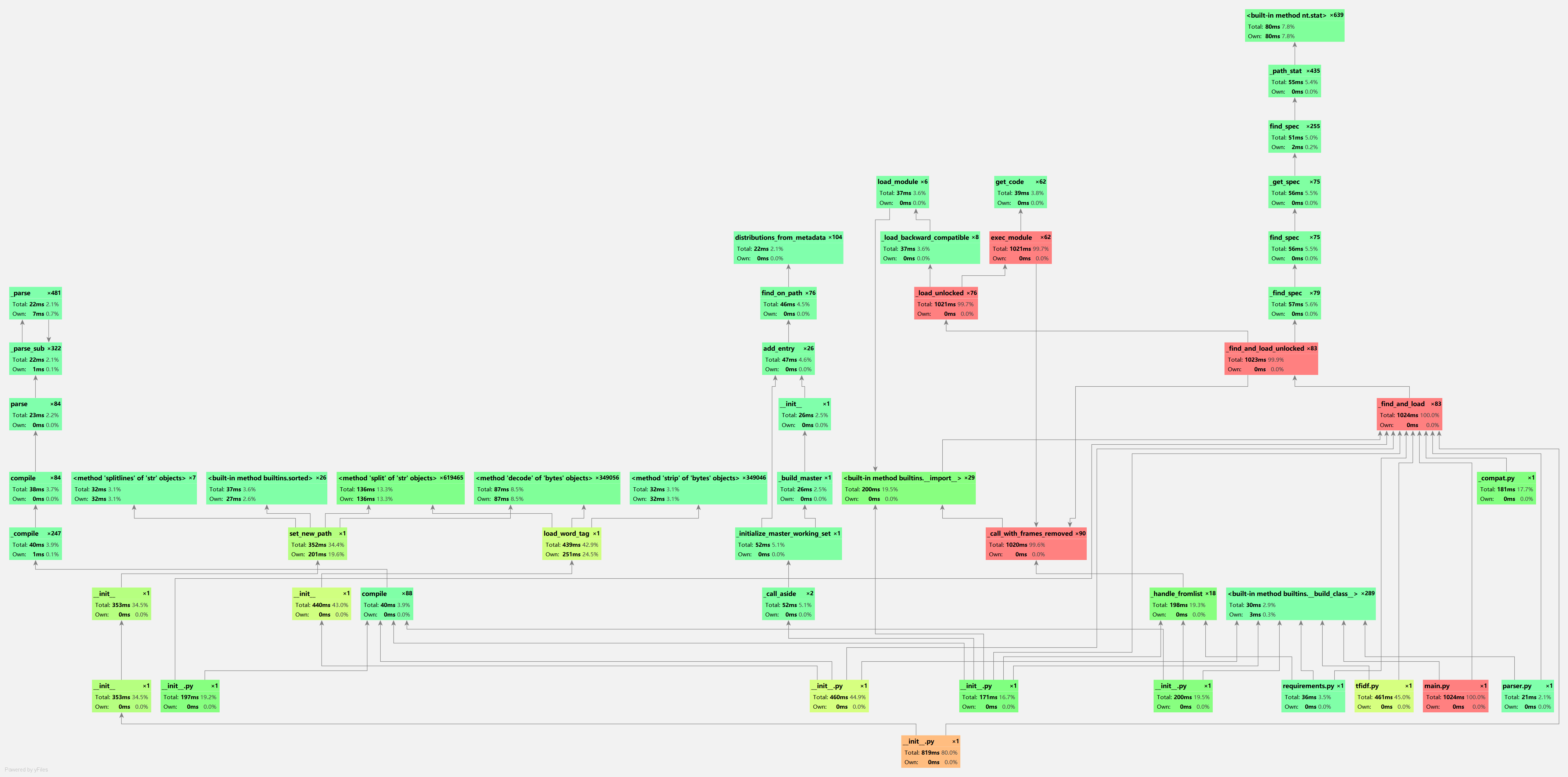

代码运行耗时为1024ms符合要求
耗时最多的就是jieba分词了...可能有更好的分词方法吧,但是我不配...所以我就对机器学习库中的
余弦相似度计算下手,舍弃机器学习库,将其换为上述的方法性能果然有所提升。
由3000+ms变为1000+ms
3.计算模块部分单元测试展示。
对于单元测试,我是一脸懵逼的,但还是硬着头皮地面向百度编程,得知了python自带的unittest可以
进行单元测试,就按照网上教程依葫芦画瓢,勉强算是完成了。

测试的代码如下:
import unittest
import csim
class MyTest(unittest.TestCase):
def test_add(self):
print("orig_0.8_add.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_add.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_del.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_dis_1.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_dis_3.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_dis_7.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_dis_10.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_dis_15.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_mix.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 与ori.txt的相似度是:")
with open("d:\\软工\\第一次软工作业\\orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("d:\\软工\\第一次软工作业\\orig_0.8_rep.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = csim.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.calculate(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
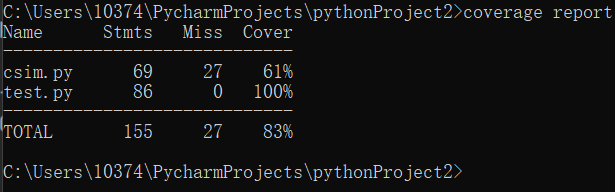
代码覆盖率如下:
4.计算模块部分异常说明
如果输入的文本为空,那么onehot编码后的向量将是零向量,这将导致开方后的分母为0,所以这时候,我设置输出“路径错误”
5.总结
刚开始看到题目真把我人都整傻了...我怀疑自己是不是比诸君少学了一年甚至两年,如何就疯狂在网上寻找教程以及代
码(大呼柯老板牛逼),刚开始不知好歹地想要刚学的java试试,然后...人生苦短,我用python,还好大一时候学的一丢丢
python还记得,起码能读懂代码,到这,我只想说:python牛逼。这段时间让我明白自己的卑微以及弱小,但是疯狂的递归式学
习也让我对这些以前让我觉得很牛逼的算法以及代码有所了解,好歹能大概写出一点样子来了。CSDN牛逼,以后我一定重新做人。

