13 拷贝控制
目录
- 0. 概述
- 1. 拷贝、赋值与销毁
- 2. 拷贝控制和资源管理:通过定义不同的拷贝操作,使自定义的类的行为看起来像一个值或指针
- 3. 交换操作:swap操作(标准库定义版本和类自定义版本)
- 4. 拷贝控制示例
- 5. 动态内存管理类:实现vector示例
- 6. 对象移动:新标准的一个最主要的特性是可以移动而非拷贝对象的能力
0. 概述
- 在这一章中,我们要介绍一些函数来控制类的行为:拷贝、赋值、移动、销毁
- 手段(特殊的成员函数)有:拷贝构造函数、移动构造函数、拷贝赋值运算符、移动赋值运算符、析构函数
- 以上这些都被称为拷贝控制。
| 特殊的成员函数 | 控制类的行为 |
|---|---|
| 拷贝和移动构造函数 | 用同类型的另一个对象初始化本对象时做什么(class a(b)) |
| 拷贝和移动赋值运算符 | 将一个对象赋予同类型的另一个对象时做什么(class a = b) |
| 析构函数 | 此类型对象销毁时做什么 |
-
拷贝控制操作:拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符、析构函数。
-
拷贝控制成员:拷贝构造函数、拷贝赋值运算符和析构函数
-
当定义一个类时,我们显式或隐式地指定在此类型的对象拷贝、移动、赋值和销毁时做什么。一个类通过定义五种特殊的成员函数来控制这些操作,包括:拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符和析构函数。
- 拷贝和移动构造函数定义了当用同类型的另一个对象初始化本对象时做什么。
- 拷贝和移动赋值运算符定义了将一个对象赋予同类型的另一个对象时做什么。
- 析构函数定义了当此类型对象销毁时做什么。
-
在定义任何c++类时,拷贝控制操作都是必要部分。对初学C++的程序员来说,必须定义对象拷贝、移动、赋值或销毁时做什么。如果我们不显式定义这些操作,编译器也会为我们定义,但编译器定义的版本的行为可能并非我们所想。
-
当类中没有声明构造函数时,编译器会在其需要时生成合成默认构造函数。当类中没有定义拷贝构造函数时,编译器生成合成拷贝构造函数。合成拷贝赋值运算符、合成析构函数与合成拷贝构造函数类似。当类中没有自定义拷贝控制成员,且每个非static数据成员都可以移动时,编译器才会合成移动构造函数或移动赋值运算符
-
通常,实现拷贝控制操作最困难的地方是首先认识到什么时候需要定义这些操作。
- 若一个类需要析构函数,则几乎肯定需要拷贝构造函数、拷贝赋值运算符;
- 若一个类需要拷贝构造函数,则几乎肯定需要拷贝赋值运算符;
- 若一个类需要拷贝赋值运算符,则几乎肯定需要拷贝构造函数;
- 若一个类定义任意一个拷贝控制,则应该定义所有的5个拷贝控制操作
-
多数类应该定义默认构造函数、拷贝构造函数和拷贝赋值运算符,无论是隐式地还是显式地
1. 拷贝、赋值与销毁
- 最基本的操作:拷贝构造函数、拷贝赋值运算符和析构函数,统称拷贝控制成员
1.1 拷贝构造函数:定义:T(const T& tmp):初始化列表{} 初始化:T a = b;
- 拷贝构造函数:
- 构造函数;
- 第一个参数是自身类类型的引用(最好是const且不要是explicit的);任何额外参数都有默认值;
- 拷贝初始化调用拷贝构造函数(用=定义对象时foo A=B),默认构造函数用在实例初始化时foo B;
- 默认合成拷贝构造函数浅拷贝,自定义拷贝构造函数深拷贝
- 如果一个构造函数的第一个参数是自身类类型的引用,且任何额外参数都有默认值,则此构造函数是拷贝构造函数:
class Foo{
Foo();//默认构造函数
Foo(const Foo&); //拷贝构造函数,参数最好是const且不要是explicit的,方便大家用
}
- 拷贝构造函数通常不是explicit,第一个参数几乎总是const,并且必须是一个引用类型
- 合成拷贝构造函数:编译器自己的定义
- 如果我们没有定义拷贝构造函数,编译器将会为我们定义一个合成的拷贝构造函数。
- 与合成默认构造函数不同,即使我们定义了其他构造函数,编译器也会为我们合成一个拷贝构造函数。
- 合成的拷贝构造函数会将其参数的成员逐个的拷贝到正在创建的对象中。
- 编译器从给定对象中依次将每个非static成员拷贝到正在创建的对象中。
- 每个成员的类型,决定了它如何拷贝:
- 内置类型的成员:直接进行内存拷贝
- 类类型的成员:调用其拷贝构造函数进行拷贝
- 数组:虽然不能直接拷贝数组,但是合成拷贝成员,会逐一的拷贝数组中的元素。
// Sales_data类的合成拷贝构造函数等价于:(用等价来说明编译器自己定义的合成构造函数)
class Sales_data
{
public:
//与合成的拷贝构造函数等价的拷贝构造函数的声明
Sales_data(const Sales_data&);
private:
string bookNo;
int units_sold = 0;
double revenue = 0;
};
//与Sales_data的合成的拷贝构造函数等价
Sales_data::Sales_data(const Sales_data &orig) :
bookNo(orig.bookNo), //使用string的拷贝构造函数
units_sold(orig.units_sold), //拷贝orig.units_sold
revenue(orig.revenue) //拷贝orig.revenue
{ } //空函数体
拷贝初始化
- 拷贝初始化 vs 直接初始化
- 直接初始化要求编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。
- 调用与圆括号参数最匹配的构造函数初始化
- T a(参数); 或 T a(b);
- 拷贝初始化要求编译器将右侧运算对象拷贝到正在创建的对象中,必要时可进行类型转换。
- 调用拷贝构造函数或移动构造函数初始化
- T a=b;
- 直接初始化要求编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。
string dots(10, 's'); //直接初始化
string s(dots); //直接初始化
string s2 = dots; //拷贝初始化
string null_book = "9-999-99999-9";//拷贝初始化
sring nines = string(100, '9');//拷贝初始化
- 使用拷贝初始化的场景(类似值传递)
- 使用=定义变量;
- 将实参传递给非引用形参;——这也解释了为什么拷贝构造函数的第一个参数必须是引用类型(具体原因在后文)
- 返回类型为非引用类型的函数返回对象;
- 花括号列表初始化数组元素或聚合类成员P266;
- 某些类类型会对其分配的对象进行拷贝初始化,如vector的insert和push进行拷贝初始化,emplace进行直接初始化
- 在函数调用过程中,具有非引用类型的参数要进行拷贝初始化。类似的,当一个函数具有非引用的返回类型时,返回值会被用来初始化调用方的结果。
拷贝构造函数的第一个参数必须是引用类型的原因
- 若第一个参数不是引用类型,函数调用时非引用类型的形参使用拷贝构造函数进行拷贝初始化(非引用就要传值,形参会对实参进行拷贝),而该形参的拷贝构造函数的第一个参数又是非引用类型,这个参数又需要调用它的拷贝构造函数,如此会无限循环
- 拷贝构造函数第一个参数不是引用类型,那就是传值,传值就是形参对实参的拷贝,从而导致调用形参的拷贝构造函数,又是传值,又调用形参的形参的拷贝构造函数,如此无限循环
// https://www.cnblogs.com/inception6-lxc/p/8994009.html
#include <iostream.h>
class CExample
{
int m_nTest;
public:
CExample(int x):m_nTest(x) //带参数构造函数
{
cout << "constructor with argument/n";
}
CExample(const CExample & ex) //拷贝构造函数
{
m_nTest = ex.m_nTest;
cout << "copy constructor/n";
}
CExample& operator = (const CExample &ex)//赋值运算符重载
{
cout << "assignment operator/n";
m_nTest = ex.m_nTest;
return *this;
}
void myTestFunc(CExample ex)
{
}
};
int main()
{
CExample aaa(2);
CExample bbb(3);
bbb = aaa;
CExample ccc = aaa;
bbb.myTestFunc(aaa);
return 0;
}
/*
输出结果:
constructor with argument // CExample aaa(2);
constructor with argument // CExample bbb(3);
assignment operator // bbb = aaa; bbb对象已经实例化,不需要构造,此时只是将aaa赋值给bbb,只会调用赋值函数
copy constructor // CExample ccc = aaa; ccc还没有实例化,因此调用的是拷贝构造函数,构造出ccc,而不是赋值函数
copy constructor // bbb.myTestFunc(aaa); 实际上是aaa作为参数传递给bbb.myTestFunc(CExample ex), 即CExample ex = aaa;和第四个一致的,所以还是拷贝构造函数,而不是赋值函数
*/
/*
通过这个例子, 我们来分析一下为什么拷贝构造函数的参数只能使用引用类型。
看第四个输出:
copy constructor // CExample ccc = aaa;
构造ccc,实质上是ccc.CExample(aaa); 我们假如拷贝构造函数参数不是引用类型的话,那么将使得 ccc.CExample(aaa)变成aaa传值给ccc.CExample(CExample ex),
即CExample ex = aaa,因为 ex 没有被初始化,所以 CExample ex = aaa 继续调用拷贝构造函数,
接下来的是构造ex,也就是 ex.CExample(aaa),必然又会有aaa传给ex.CExample(CExample ex), 即 CExample ex = aaa;那么又会触发拷贝构造函数,就导致永远的递归下去。
*/
- 这个例子就是想说明拷贝构造函数的参数使用引用类型不是为了减少一次内存拷贝,而是避免拷贝构造函数无限制的递归下去。
- 所以,拷贝构造函数是必须要带引用类型的参数的,而且这也是编译器强制性要求的。
- 注:C++的函数参数传递方式,可以是传值方式,也可以是传引用方式。
- 传值的本质是:形参是实参的一份复制。
- 传引用的本质是:形参和实参是同一个东西。
- 传值和传引用,对大多数常见类型都是适用的。指针、数组,它们都是数据类型的一种,因此指针作为函数参数传递时,也区分为传值和传引用两种方式。
- 拷贝初始化的限制
- 如果我们使用的初始化值要求通过一个explicit的构造函数来显式地进行类型转换,那么使用拷贝初始化还是直接初始化就不是无关紧要的了:

- 如果我们使用的初始化值要求通过一个explicit的构造函数来显式地进行类型转换,那么使用拷贝初始化还是直接初始化就不是无关紧要的了:
- 当传递一个实参或从函数返回一个值时,我们必须显式地使用一个explicit构造函数
- 虽然编译器可以略过拷贝/移动构造函数,但依然要求拷贝/移动构造函数必须存在且可访问。
string s = "1"; // 拷贝初始化,等价于string temp("1"); string s = temp; //使用拷贝构造函数
string s("1"); // "1":const char *,略过拷贝构造函数
1.2 拷贝赋值函数:定义:T& operator=(const T& left):初始化列表{...return *this} 初始化:T a; a = b;
- 拷贝赋值运算符:
- 拷贝构造函数是在用=定义时,拷贝赋值是在用=赋值时
- 拷贝赋值运算符通常执行拷贝构造函数和析构函数中也要做的工作
- 与类控制其对象如何初始化一样,类也可以控制其对象如何赋值:
Sales_data trans,accum;
trans = accum; //使用Sales_data的拷贝赋值运算符
- 当进行赋值时如A=B;调用的是A的拷贝赋值运算符,而B作为该拷贝赋值运算符函数的参数进行传递,此时A中成员可以用this指针访问
重载赋值运算符:我们自己定义
- 重载运算符本质上是函数,区别在于其名字由operator关键字后接要定义的运算符的符号组成。类似于任何其他函数,运算符函数也有一个返回类型和一个参数列表。
- 重载运算符的参数表示运算符的运算对象。某些运算符,包括赋值运算符,必须定义为成员函数。
- 如果一个运算符是一个成员函数,其左侧运算对象就绑定到隐式的this参数。
- 对于一个二元运算符,例如赋值运算符,其右侧运算对象作为显式参数传递。
- 重载赋值运算符的函数名:operator=
- 拷贝赋值运算符接受一个与其所在类型相同类型的引用参数
- 赋值运算符通常返回一个指向其左侧运算对象的引用
- 为了与内置类型的赋值保持一致,赋值运算符通常返回一个指向其左侧运算对象的引用。
- 另外,标准库通常要求保存在容器中的类型要具有赋值运算符,且其返回值是左侧运算对象的引用。
class Foo{
public:
Foo& operator=(const Foo&);//赋值运算符
};
合成拷贝赋值运算符:编译器自己定义
- 与拷贝构造函数一样,如果类未定义自己的拷贝赋值运算符,编译器会为它合成一个
- 通常情况下,合成的拷贝赋值运算符会将右侧对象的非static成员逐个赋予左侧对象的对应成员,这些赋值操作是由成员类型的拷贝赋值运算符来完成的
- 对于成员是类类型,则调用其赋值运算符。
- 对于成员是数组类型,则逐一赋值。
- 对于成员是内置类型,则直接赋值。
// 下面的代码等效于编译器定义的Sales_data的合成拷贝赋值运算符
Sales_data& Sales_data::operator=(const Sales_data &rhs)
{
bookNo = rhs.bookNo; //rhs是右侧对象
units_sold = rhs.units_sold;
revenue = rhs.revenue;
return *this; //返回此对象的引用
}
1.3 析构函数:对象被销毁时自动运行;定义:~T() {}
- 当类中出现了指向动态内存的普通指针类型的成员时才需要我们自己写析构函数来释放给指针所分配的动态内存来防止内存泄露,否则直接用编译器的合成析构函数就够了。
- 通常使用了动态内存的类,一般需要定义自己的析构函数,常在析构函数体内定义自己的delete指向动态内存的普通指针操作以及对象销毁时打印信息等操作;
- 其他与合成析构函数同的销毁操作体现在析构部分(隐式),意思是析构部分自动执行编译器能销毁的操作,其余用户自定义操作写在析构函数体内。
- 析构函数执行与构造函数相反的操作
- 构造函数初始化对象的非static数据成员,还可能做一些其他工作;
- 析构函数释放对象使用的资源,并销毁对象的非static数据成员。
自定义析构函数
- 析构函数由析构函数体和析构部分组成,但析构函数体自身并不直接销毁成员。成员是在析构函数体之后隐含的析构阶段中被销毁的。
- 在整个对象销毁过程中,析构函数体是作为成员销毁步骤之外的另一部分而进行的。
- 析构部分负责销毁对象,你要是想另外加点什么操作,就在析构函数体里面加(如在销毁时打印什么提示信息之类的)
- 析构函数是类的一个成员函数,名字是由波浪线加类名构成,没有返回值,也不接受参数
class Foo{
public:
~Foo();//析构函数,因为它不接受参数,所以不能被重载,一个类只有一个析构函数
}
- 由于析构函数不接受参数,因此它不能被重载。对一个给定类,只会有唯一一个析构函数。
- 析构函数完成的工作
- 在一个构造函数中:成员的初始化是在函数体执行之前完成的,且按照它们在类中出现的顺序进行初始化。
- 在一个析构函数中:首先执行函数体,然后销毁成员(成员按初始化顺序的逆序销毁)。
- 在一个析构函数中,不存在类似构造函数中初始化列表的东西来控制成员如何销毁,析构部分是隐式的。成员销毁时发生什么完全依赖于成员的类型。销毁类类型的成员需要执行成员自己的析构函数。内置类型没有析构函数,因此销毁内置类型成员什么也不需要做。
- 隐式销毁一个内置指针类型的成员不会delete它所指向的对象(普通指针没有析构函数)。
- 与普通指针不同,智能指针是类类型,所以具有析构函数。因此与普通指针不同,智能指针成员在析构阶段会被自动销毁。
- 什么时候会调用析构函数:无论何时一个对象被销毁,就会自动调用其析构函数
- 变量在离开其作用域时被销毁
- 当一个对象被销毁时,其成员被销毁
- 容器(无论是标准库容器还是数组)被销毁时,其元素被销毁
- 对于动态分配的对象,当对指向它的指针应用delete运算符时被销毁
- 对于临时对象,当创建它的完整表达式结束时被销毁
- 由于析构函数自动运行,我们的程序可以按需分配资源,无需担心何时释放这些资源。
{ //新作用域
//p和p2指向动态分配的对象
Sales_data *p = new Sales_data; //p是普通指针
auto p2 = make_shared<Sales_data>(); //p2是shared_ptr
Sales_data item(*p); //拷贝构造函数将*p拷贝到item中
vector<Sales_data> vec; //局部对象
vec.push_back(*p2); //拷贝p2指向的对象
delete p; //对p指向的对象执行析构函数
}
//退出局部作用域:对item、p2和vec调用析构函数;
//p2被销毁后,其对象引用计数递减,如果引用次数变为0,对象被释放
//销毁了vec会销毁它的元素
/*
当程序块结束时,vec、p2和item都离开了作用域,意味着这些对象上分别会执行vector、shared_ptr和Sales_data的析构函数。
vector的析构函数会销毁我们添加到vec的元素
shared_ptr的析构函数后递减p2指向的对象的引用次数,若引用次数为0,shared_ptr的析构函数会delete p2分配的Sales_data对象
Sales_data的析构函数会销毁其成员如bookNo。bookNo是string,销毁bookNo会调用string的析构函数,释放bookNo所用的内存.
上面的代码比较复杂,但是仔细看会发现,我们只要管自己new出来的p就好了,其他的析构都不用自己操心。你要是不用new的话,你什么也不用管
*/
- 当指向一个对象的引用或指针离开作用域时,析构函数不会执行。
- 代码理解调用几次析构函数
// 测试代码
Sales_data s(string("001"),10,5);
Sales_data s2(string("001"), 10, 5);
Sales_data *s1=&s;
fcn(s1,s2);
// 其中析构函数为:
// ~Sales_data() { cout << "这是在执行Sales_data的析构函数..." << endl; }
// 代码一:指针 调用3次
bool fcn(const Sales_data *trans,Sales_data accum){
Sales_data item1(*trans), item2(accum);
return item1.isbn()!=item2.isbn();
}
/*
输出结果:
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
*/
/*
调用三次析构函数:
函数结束时,局部变量item1和item2的生命期结束,被销毁,Sales_data的析构函数被调用
函数结束时,参数accum的生命期结束,被销毁,Sales_data的析构函数被调用
在函数结束时,trans的生命期也结束了,但它是Sales_data的指针,并不是它指向的Sales_data对象的生命期结束(只有delete指针时,指向的动态对象的生命期才结束)
*/
// 代码二:引用 调用3次
bool fcn(const Sales_data &trans, Sales_data accum) {
Sales_data item1(trans), item2(accum);
return item1.isbn() != item2.isbn();
}
/*
输出结果:
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
*/
// 代码三:调用4次
bool fcn(const Sales_data trans, Sales_data accum) {
Sales_data item1(trans), item2(accum);
return item1.isbn() != item2.isbn();
}
/*
输出结果:
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
这是在执行Sales_data的析构函数...
*/
合成析构函数:编译器自己定义
- 当一个类未定义自己的析构函数时,编译器会为它定义一个合成析构函数。
- 下面代码等价于该类的合成析构函数:
class Sales_data
{
public:
~Sales_data() {} //成员会被自动销毁,所以不需要做任何事情
//其他成员的定义,如前
}
何时需要自定义析构函数
- 注意注意,C++中唯一需要我们手动销毁的的是动态内存,如果在类中定义则需要我们自己在析构函数中用delete销毁,如果你定义的类中没有动态内存,那完全可以不用自己定义析构函数,直接用合成析构函数。但如果用智能指针自动管理动态内存,就万事大吉,销毁啥的都不用管了。
- 假设有一个数据需要共享,如果该数据只是保存在普通内存中,则在含有指向该数据内存的指针的某对象销毁时,该普通内存也会释放掉;但如果该共享数据保存在动态内存中,则在含有指向该数据内存的指针的某对象销毁时,如果没有在析构函数中自定义delete操作,该共享数据不会被释放。——共享数据和计数器一般保存在动态内存中
代码理解拷贝构造函数、拷贝赋值运算符以及析构函数何时执行
// Y类
class Y {
Y() { cout << "构造函数Y()" << endl; }
Y(const Y&) { cout << "拷贝构造函数Y(const Y&)" << endl; }
Y& operator=(const Y&rhs) { cout << "拷贝赋值运算符=(const Y&)" << endl; return *this; }
~Y() { cout << "析构函数~Y()" << endl; }
};
// 测试代码:
void f1(Y y){}
void f2(Y& y) {}
void testY() {
cout << "局部变量:" << endl;
Y y;
cout << endl;
//局部变量:
//构造函数Y()
cout << "非引用参数传递:" << endl;
f1(y);
cout << endl;
//非引用参数传递:
//拷贝构造函数Y(const Y&)
//析构函数~Y()
cout << "引用参数传递:" << endl;
f2(y);
cout << endl;
//引用参数传递:
cout << "动态分配:" << endl;
Y *py = new Y;
cout << endl;
//动态分配:
//构造函数Y()
cout << "添加到容器中:" << endl;
vector<Y>vy;
vy.push_back(y);
cout << endl;
//添加到容器中:
//拷贝构造函数Y(const Y&)
}
//程序结束;
//析构函数~Y()
//析构函数~Y()
//析构函数~Y()
// 程序结束后的三次Y的析构函数分别是tmp,vector中的元素和y
// 编译器可以略过对拷贝构造函数的调用。
1.4 三/五法则
- 前面介绍的三个函数:拷贝构造函数、拷贝赋值运算符、析构函数。如果你要自定义的话最好三个全都自定义了
- C++允许我们定义任意个数的这些函数,我们的建议是这三个作为整体一起定义或者不定义。
- “三法则”是针对较旧的 C++89 标准说的,“五法则”是针对较新的 C++11 标准说的;为了统一称呼,后来人们干把它叫做“C++ 三/五法则”:
- C++三法则:在 C++89旧标准下,有三个基本操作可以控制类的拷贝操作:拷贝构造函数、拷贝赋值运算符和析构函数。
- C++五法则:在C++11新标准下,一个类还可以定义一个移动构造函数和一个移动赋值运算符,这样共有五个特殊成员函数
- C++语言并不要求我们定义所有这些操作,可以只定义其中一个或两个,而不必定义所有。但是,这些操作通常应该被看做一个整体。通常,只需要其中一个操作,而不需要定义所有操作的情况是很少见的
- 基本准则1:需要析构函数的类,也需要拷贝和赋值操作
- 当我们决定一个类是否有必要定义它自己版本的拷贝控制成员时,一个基本原则是首先确定这个类是否需要一个析构函数。通常,对析构函数的需求要比对拷贝构造函数或赋值运算符的需求更为明显。
- 如果这个类需要一个析构函数,我们几乎可以肯定它也需要一个拷贝构造函数和一个拷贝赋值运算符,如何理解这句话:
- “如果需要析构函数”:说明类中必然出现了指针类型的成员(否则不需要我们写析构函数,默认合成析构函数就足够用了),而合成析构函数不会销毁,所以我们需要自己写析构函数来释放给指针所分配的内存来防止内存泄露(**当类中有和合成析构函数不能销毁的成员时就需要自定义析构函数)
- “一定需要拷贝构造函数和赋值操作符”,原因还是这样:类中出现了指针类型的成员。有指针类型的成员,我们必须防止浅拷贝问题,所以,一定需要拷贝构造函数和赋值操作符,这两个函数是防止浅拷贝问题所必须的
- 通常使用了动态内存的类,一般需要定义自己的析构函数
// 示例代码: https://blog.csdn.net/Tiramisu_zyp/article/details/46360283
// 如果我们为HasPtr定义一个析构函数,但使用合成版本的拷贝构造函数和拷贝赋值运算符:
class HasPtr{
public:
HasPtr(const string &s=string()):ps(new string(s)),i(0){} //带参数构造函数
~HasPtr(){delete ps;}
private:
string *ps;
int i;
}
//如果我们没有为我们的hasptr类定义拷贝和赋值操作将会有错误,例如:
HasPtr foo(HasPtr hp){
HasPtr ret = hp;
return ret; //ret和hp被销毁
}
/* f函数返回时,hp和ret都会被销毁,都会调用HasPtr的析构函数,都会delete ret和hp中的指针成员,但这两个指针指向的是同一个对象,于是它被释放了两次,导致错误*/
/*
在该示例中,当foo运行完毕后,hp和ret都会被销毁,在两个对象上都会调用HasPtr的析构函数,此析构函数会delete ret和hp中的指针成员,
但这两个对象包含相同的指针值(因为合成的拷贝构造函数和拷贝赋值运算符只是简单的拷贝指针成员,因此ret和hp中的指针成员指向相同的内存),
此代码会导致此指针值被delete两次,这显然是一个错误。
*/
- 因此,如果一个类需要自定义析构函数,几乎可以肯定它也需要自定义拷贝赋值运算符和拷贝构造函数。
- 基本准则2:需要拷贝操作的类也需要赋值操作,反之亦然.并且,一个类无论是需要一个拷贝构造函数还是需要一个拷贝赋值运算符,析构函数都不是必要的。
1.5 使用=default:显式要求编译器生成合成版本的拷贝控制成员
- 使用=default:可以将拷贝控制成员定义为=default来显式的要求编译器生成合成的版本
- 只能对具有合成版本的成员函数使用 =default(即,默认构造函数或拷贝控制成员)
class Sales_data{
public:
Sales_data() = default;
Sales_data(const Sales_data&) = default;
Sales_data& operator=(const Sales_data &);
~Sales_data() = default;
};
Sales_data & Sales_data::operator=(const Sales_data&) = default;
- 在类内使用=default,合成的函数是内联的;如果不希望是内联,可以在类外用=default(声明在类内,定义在类外)
- 当我们在类内使用=default修饰成员的时候,合成的函数将隐式地声明为内联。
- 如果不希望合成的成员是内联函数,应该只对成员的类外定义使用=default,如上面的拷贝赋值运算符。
1.6 使用=delete:阻止拷贝,用在当我们不想我们的类对象被拷贝或赋值时
- =delete:阻止拷贝,用在当我们不想我们的类对象被拷贝或赋值时:
- =delete 必须出现在函数第一次声明的时候,可以用于任何函数如拷贝构造函数和拷贝赋值运算符阻止拷贝和赋值,但不能用于析构函数
- 大多数类应该定义默认构造函数、拷贝构造函数和拷贝赋值运算符,无论是隐式地还是显式地。
- 但对某些类来说,这些操作没有合理的意义。在此情况下,定义类时必须采用某种机制阻止拷贝或赋值。例如,iostream类阻止了拷贝,以避免多个对象写入或读取相同的IO缓冲。如果我们不定义拷贝控制成员,编译器依然会为它生成合成的版本,因此这种不定义策略不能避免类的拷贝。
- 使用=delete定义删除的函数
- 我们可以通过将拷贝构造函数和拷贝赋值运算符定义为删除的函数来阻止拷贝。
- 删除的函数是这样一种函数:我们虽然声明了它们,但不能以任何方式使用它们。
- 在函数的参数列表后面加上 =delete 来指出我们希望将它定义为删除的
class Nocopy{
Nocopy() = default;//使用合成的默认构造函数
Nocopy(const Nocopy&)=delete;//阻止拷贝
Nocopy &operator=(const Nocopy&)=delete;//阻止赋值
~Nocopy() = default;//使用合成的析构函数
};
- 与=default 不同,=delete 必须出现在函数第一次声明的时候
- 与=default 不同,=delete可以使用在任何函数中(只能对编译器可以合成的默认构造函数或拷贝控制成员使用=default)
- =delete不能用在析构函数上
- 如果析构函数定义为删除的,那么就无法析构这个对象,编译器不允许创建这个类类型的变量或者创建该类的临时对象,因为无法销毁。
- 但是允许动态的分配这种类型的对象,但不能释放这些对象:
struct NoDtor{
NoDtor() = default;//使用合成的默认构造函数
~NoDtor() = delete;//不能销毁这个类型的对象
};
NoDtor nd;//错误,无法销毁,所以不能创建
NoDtor *p = new NoDtor();//正确:但不能delete p
delete p ;//错误,因为不能调用析构函数
- 合成的拷贝控制成员可能是删除的(即编译器可能将其定义为删除的)
- 如果一个类未定义拷贝控制成员或构造函数,编译器会定义默认的合成版本。对某些类来说,编译器将这些合成的成员定义为删除的函数:
- 如果类的某个成员的析构函数是删除的或者不可访问的,则类的合成析构函数被定义为删除的.
- 如果类的某个成员的拷贝构造函数是删除的或不可访问的,则类的合成拷贝构造函数被定义为删除的.如果类的某个成员的析构函数是删除的或不可访问的,则类合成的拷贝构造函数也被定义为删除的.
- 如果类的某个成员的拷贝赋值运算符是删除的或不可访问的,或是一个类有一个const的或引用成员,则类的合成拷贝赋值运算符被定义为删除的.
- 如果类的某个成员的析构函数是删除的或不可访问的,或是类有一个引用成员,它没有类内初始值,或是类有一个const成员,它没有类内初始值且其类型未显式定义默认构造函数,则该类的默认构造函数被定义为删除的
- 本质上,这些规则的含义是:如果一个类有数据成员不能默认构造、拷贝、复制或销毁,则对应的成员函数将被定义为删除的。
- 如果一个类未定义拷贝控制成员或构造函数,编译器会定义默认的合成版本。对某些类来说,编译器将这些合成的成员定义为删除的函数:
| =delete | 原因 |
|---|---|
| 合成默认构造函数 | 1、类成员的析构函数是删除(=delete)或不可访问(private)。 2、类中含有引用成员,该成员没有类内初始值。 3、类中含有const成员,该成员没有类内初始值,且其类型未显式定义默认构造函数。 |
| 合成拷贝构造函数 | 1、类成员的拷贝构造函数是删除或不可访问。 2、类成员的析构函数是删除或不可访问。 |
| 合成拷贝赋值运算符 | 1、类成员的拷贝赋值运算符是删除或不可访问。 2、类中含有const成员或引用成员。 |
| 合成析构函数 | 1、类成员的析构函数是删除或不可访问 |
- private拷贝控制:在新标准发布之前,类是通过将其拷贝构造函数和拷贝赋值运算符声明为private来阻止拷贝的。但阻止拷贝还是应该用=delete。以下面例子说明:
class PrivateCopy{
PrivateCopy(const PrivateCopy&);
PrivateCopy & operator=(const PrivateCopy&);
public:
PrivateCopy() = default;
~PrivateCopy() ;
};
// 由于拷贝构造函数和拷贝赋值运算符是private的,用户代码将不能拷贝这个类型的对象。
// 但是友元和成员函数仍旧可以拷贝对象。为了阻止友元和成员函数进行拷贝,将这些函数拷贝控制成员声明为private,但不定义他们。
- 注意:希望阻止拷贝的类应该使用=delete来定义他们自己的拷贝构造函数和拷贝赋值运算符,而不应该将他们声明为private
2. 拷贝控制和资源管理:通过定义不同的拷贝操作,使自定义的类的行为看起来像一个值或指针
- 通常,管理类外资源的类必须定义拷贝控制成员,这种类需要通过析构函数来释放对象所分配的资源。一旦一个类需要析构函数,那么它几乎肯定也需要一个拷贝构造函数和一个拷贝赋值运算符。
- 为了定义这些成员,我们首先必须确定此类型对象的拷贝语义。一般来说,有两种选择:通过定义不同的拷贝操作,使自定义的类的行为看起来像一个值或指针:
- 类的行为像一个值,意味着类有自己的状态。当我们拷贝一个像值的对象时,副本和原对象是完全独立的,改变副本不会改变原对象,反之亦然。
- 类的行为像一个指针,则类共享状态。当我们拷贝一个这种类的对象时,副本和原对象使用相同的底层数据,改变副本也会改变原对象,反之亦然。
- 标准库容器和string类的行为像一个值。
- shared_ptr类提供类似指针的行为。
- IO类型和unique_ptr不允许拷贝或赋值,因此它们的行为既不像值也不像指针。
- 接下来我们要实现一个类HasPtr,让它的行为像一个值;然后重新实现它,使其像一个指针:
- 我们的HasPtr有两个成员,一个int和一个string指针。
- 通常,类直接拷贝内置类型(不包括指针)成员;这些成员本身就是值,因此通常应该让它们的行为像值一样。
- 我们把重心放到string指针成员,它的行为决定了该类是像值还是像指针。
- 指针成员的拷贝决定类的行为像值或像指针。
2.1 定义行为像值的类:拷贝指针指向的对象;独立
- 为了提供类值的行为,对于类管理的资源,每个对象都应该拥有一份自己的拷贝。这意味着对于ps指向的string,每个HasPtr对象都必须有自己的拷贝
- 为了像值,每个string指针指向的那个string对象,都得有自己的一份拷贝
- 为了实现类值行为,HasPtr需要:
- 定义一个拷贝构造函数,完成string的拷贝,而不是拷贝指针
- 定义一个析构函数来释放string
- 定义一个拷贝赋值运算符来释放对象当前的string,并从右侧运算对象拷贝string
- 类值版本的HasPtr如下所示:
class HasPtr{
public:
HasPtr(const string &s=string()):ps(new string(s)),i(0){} //带参数构造函数,默认实参,列表初始化
HasPtr(const HasPtr &p):ps(new string(*p.ps)),i(p.i){} //拷贝构造函数
HasPtr& operator=(const HasPtr &); //拷贝赋值运算符
~HasPtr(){delete ps;} //析构函数
private:
string *ps;
int i;
}
- 类值拷贝赋值运算符
- 赋值:对象A=对象b
- 赋值运算符通常组合了析构函数和构造函数的操作。
- 类似析构函数, 赋值操作会销毁左侧运算对象的资源。
- 类似拷贝构造函数,赋值操作会从右侧运算对象拷贝数据。
- 这些操作是以正确的顺序执行的,即使将一个对象赋予它自身,也保证正确。而且,如果可能,我们编写的赋值运算符还应该是异常安全的。当异常发生时能将左侧运算对象置于一个有意义的状态。
- 当编写赋值运算符时,有两点需要记住:
- 如果将一个对象赋予它自身,赋值运算符必须能正确工作。
- 大多数赋值运算符组合了析构函数和拷贝构造函数的工作。
- 当编写一个赋值运算符时,为了保证一个对象能为它本身赋值,一个好的模式是:
- 先将右侧运算对象拷贝到一个局部临时对象中。
- 当拷贝完成后,销毁左侧运算对象的现有成员就是安全的了。
- 一旦左侧运算对象的资源被销毁,就只剩下将数据从临时对象拷贝到左侧运算对象的成员中了。
HasPtr& HasPtr::operator=(const HasPtr &rhs){
auto newp = new string(*rhs.ps);//拷贝底层string
delete ps;//释放旧内存
ps=newp;//从右侧运算对象拷贝数据到本对象
i=rhs.i;
return *this;//返回本对象
}
2.2 定义行为像指针的类(副本):拷贝指针本身;一体
- 定义行为像指针的类:拷贝指针本身。最好的方法是使用share_ptr管理类中的资源。但若想我们自己直接管理资源,则需使用引用计数。可将引用计数保存在动态内存中。
- **对于行为类似指针的类:
- 我们需要为其定义拷贝构造函数和拷贝赋值运算符**,来拷贝指针成员本身而不是它指向的对象如string。
- 我们的类仍然需要自己的析构函数来释放接受string参数的构造函数分配的内存。只有当最后一个指向string的HasPtr销毁时,它才可以释放string。
- 令一个类展现类似指针的行为的方法:
- 最好方法是使用shared_ptr来自动管理类中的资源。
- 但是,有时我们希望自己直接管理资源,此时可以使用自己设计的引用计数,而不是shared_ptr
- 假若我们有一个类的成员变量需要共享,希望在使用时保留,没有用到时就delete掉,那要怎么设计?参考
- 使用计数器记录有多少用户在共享该成员变量,并且需要把共享数据和计数器保存在动态内存中,以便某用户释放时,共享数据和计数器不被释放
- 假设我们有共享数据share_data,对象A,B,C有指向该share_data,如果我们只是在析构函数中单方面地释放关联的share_data,比如A不再需要share_data,并且单方面释放了share_data,那会造成一个问题:B和C还要用share_data呢,但A却把它释放了。因此只有当最后一个指向share_data的对象销毁时,share_data才可以释放。
- 引用计数可以解决这样的问题。它的思想是对share_data进行计数,当有对象指向它时,计数加一,当对象不再指向时就计数减一,当计数为0时,就释放share_data
引用计数/计数器的工作方式
- 除了初始化对象外,每个构造函数(拷贝构造函数除外):
- 还要创建一个计数器,用来记录有多少对象与正在创建的对象共享状态。
- 当我们创建一个对象时,只有一个对象共享状态,因此将计数器初始化为1。
- 拷贝构造函数:
- 不分配新的计数器,而是拷贝给定对象的数据成员,包括计数器。
- 拷贝构造函数递增共享的计数器,指出给定对象的状态又被一个新用户所共享。
- 析构函数:
- 递减计数器,指出共享状态的用户少了一个。如果计数器变为0,则析构函数释放状态。
- 拷贝赋值运算符:
- 递增右侧运算对象的计数器,递减左侧运算对象的计数器。
- 如果左侧运算对象的计数器变为0,意味着它的共享状态没有用户了,拷贝赋值运算符就必须销毁状态。
- 我们将计数器保存在动态内存中,当创建一个对象时,我们也分配一个新的计数器。当拷贝或赋值对象时,我们拷贝指向计数器的指针。使用这种方法,副本和原对象都会指向相同的计数器
自定义含有共享数据和计数器的类实例
class HasPtr {
public:
//构造函数动态分配新的string和新的计数器,将计数器置为1
HasPtr(const string &s = string()) :ps(new string(s)), i(0),use(new size_t(1)) {}
//拷贝构造函数拷贝所有三个数据成员,并递增计数器
HasPtr(const HasPtr &p) :ps(p.ps), i(p.i), use(p.use) { ++*use; }
//赋值运算符
HasPtr& operator=(const HasPtr &rhs) {
++*rhs.use;//递增右侧运算对象的引用计数
if (--*use == 0) { //递减本对象的引用计数,
delete ps; //如果计数为0,则释放本对象分配的成员
delete use;
}
ps = rhs.ps; //将数据从rhs拷贝到本对象
i = rhs.i;
use = rhs.use;
return *this; //返回本对象
}
//析构函数
~HasPtr() {
//如果引用计数变为0,则释放string内存,释放计数器内存
if (--*use == 0) {
delete ps;
delete use;
}
}
//打印use
void printUse() { cout << "use:" << *use << endl; }
private:
string *ps;
int i;
size_t *use;
};
// 测试代码:
HasPtr hp1("hello");
hp1.printUse(); //1
HasPtr hp2(hp1);
hp1.printUse(); //2
hp2.printUse(); //2
HasPtr hp3;
HasPtr hp4(hp3);
hp3.printUse(); //2
hp4.printUse(); //2
hp4 = hp1;//增加 hp1 的计数,减少hp4原计数器的计数,赋值操作后,hp4和hp1指向相同的内存,故hp3计数为1,其余计数为3
hp1.printUse(); //3
hp2.printUse(); //3
hp3.printUse(); //1
hp4.printUse(); //3
3. 交换操作:swap操作(标准库定义版本和类自定义版本)
- swap操作(标准库定义版本和类自定义版本),用于交换两个对象的值;定义了类特定的swap函数后,就可以利用它写出更简洁的赋值运算符
- 除了定义拷贝控制成员外,管理资源的类通常还会定义一个swap函数用于交换两个元素(需要进行一次拷贝和两次赋值),对于需要重排元素的算法尤其重要。
- 当作用域有using std::swap,如果一个类定义了自己的swap,那么算法将使用类的自定义版本。否则,算法将使用标准库定义的std::swap。
- 如果一个类的成员有自己类型特定的swap函数,显式调用std::swap就是错误的了。
- 如果存在类型特定的swap版本,其匹配程度会优于std中定义的版本
- 为什么要自定义自己的swap函数
// 如果仅仅使用标准库中的swap函数,那么这个函数,将使用如下的形式进行拷贝:
temp = v1;
v1 = v2;
v2 = v1;
// 比如我们来交换一下前面写的HasPtr(值拷贝版本):
HasPtr temp = v1;
v1 = v2;
v2 = temp;
// 这是很自然的一种写法,我们借助中间量temp来交换v1和v2。但是当v1和v2这两个对象非常大的时候,这种交换就非常的耗时,而且这两个对象,其实可以只交换他们的部分内容。因此有必要定义自己的swap函数,改为去交换指针更合算:
string *temp = v1.ps;
v1.ps = v2.ps;
v2.ps = temp;
- 在自己类中自定义swap函数:设法使swap交换指针而不是分配对象的新副本
//当交换两个HasPtr对象时,只需要交换他们内部的指针即可.
class HasPtr{
friend void swap(HasPtr &,HasPtr &);//友元函数,为了能访问private的数据成员
};
inline void swap(HasPtr &lhs,HasPtr &rhs){ //声明为内联函数
using std::swap;
swap(lhs.ps,rhs.ps);//内置类型没有特定版本的swap,对swap的调用会调用标准库函数std::swap来交换内部的指针
swap(lhs.i,rhs.i);//调用库函数交换内部的int成员
}
// 由于swap是为了优化代码,因此定义为了inline
// 注意using std::swap;这条语句.这个会让编译器选择一个最优的swap函数来调用
- 在赋值运算符中使用swap
- 定义swap的类通常用swap来定义它们的赋值运算符。这些运算符使用了一种名为拷贝并交换的技术。这种技术将左侧运算对象与右侧运算对象的一个副本进行交换。(在这个版本的赋值运算符中,参数并不是一个引用,因此rhs是右侧运算对象的一个副本)
- 我们定义了swap函数后,就可以利用它写出更简洁的赋值运算符:
//rhs是按值传递的,意味着HasPtr的拷贝构造函数
//将右侧运算对象中的string拷贝到rhs
HasPtr& HasPtr::operator=(HasPtr rhs){
//交换左侧运算对象和局部变量rhs的内容
swap(*this,rhs); //rhs现在指向本对象曾经使用的内存
return *this; //rhs被销毁,从而delete了rhs中的指针
}
lhs = a;
/*
这样就调用了赋值运算符:
(1)a是通过值传递的方式给赋值运算符的,也就是a拷贝了一个副本rhs
(2)在函数体中调用swap函数交换了二者的数据成员,交换的是指针哦,调用后this指向原来rhs的内存,现在rhs指向原来的this内存
(3)return语句执行后,rhs作为局部对象被销毁,HasPtr的析构函数将执行。
内存被释放,这个被释放的内存就是原来this指向的内存,也就是调用赋值运算符语句中的lhs
- 使用拷贝和交换的赋值运算符自动就是异常安全的,且能正确处理自赋值
4. 拷贝控制示例
- 虽然通常来说,分配资源的类更需要拷贝控制,但资源管理并不是一个类需要定义自己的拷贝控制成员的唯一原因。一些类也需要拷贝控制成员的帮助来进行簿记工作或其他操作
- 当类需要分配资源、簿记工作(类似于邮件处理应用中的Message和Folder)等操作时,通常需要拷贝控制。
- 示例代码【两个类相互调用】
- 我们将建立两个类用于邮件处理,两个类命名为Message和Folder,分别表示邮件消息和消息目录。每个Message对象可以出现在多个Folder中,但是任意给定的Message的内容只有一个副本,这样的话,一条Message的内容改变,则我们从任意Folder来浏览它时看到的都是更新的内容
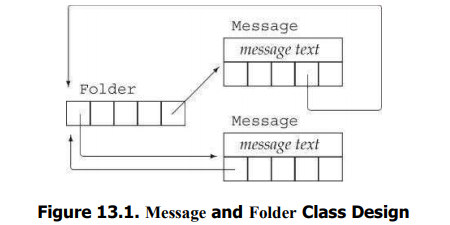
- 设计:
- 为了记录Message位于哪些Folder中,每个Message保存一个它所在Folder的指针的set集合;每个Folder也保存一个它包含的Message的指针的set集合
- Message类提供save和remove操作,用来向一个给定的Folder中添加或删除一条Message
- 当拷贝Message时,不仅要拷贝Message内容,还要让副本也出现在跟原对象一样的Folder中
- 同样的,销毁一个Message时,我们也要从包含此消息的所有Folder中删除指向此Message的指针。
- 赋值时,左侧Message内容当然会被右侧代替,我们还得更新Folder集合,从原来包含左侧Message的Folder中删除它,并将它添加到包含右侧Message的Folder中。
- Folder类也需要类似的拷贝控制成员,来添加或删除它保存的Message
- 拷贝赋值运算符通常执行拷贝构造函数和析构函数中也要做的工作。这种情况下,公共的工作应该放在private的工具函数中完成。
- 我们将建立两个类用于邮件处理,两个类命名为Message和Folder,分别表示邮件消息和消息目录。每个Message对象可以出现在多个Folder中,但是任意给定的Message的内容只有一个副本,这样的话,一条Message的内容改变,则我们从任意Folder来浏览它时看到的都是更新的内容
- Message类:
// Message.h文件
#ifndef __MESSAGE__
#define __MESSAGE__
#include<iostream>
#include<set>
#include<string>
#include"Folder.h"
using namespace std;
class Message {
friend class Folder;
public:
explicit Message(const string &str="") :contents(str){}
//拷贝控制成员,用来管理指向本Message的指针
Message(const Message&);//拷贝构造函数
Message& operator=(const Message&);//拷贝赋值运算符
~Message();//(显式合成)析构函数
//从给定Folder集合中添加/删除本Message
void save(Folder&);
void remove(Folder&);
void addFldr(Folder *f) {
folders.insert(f);
}
private:
string contents; //实际消息文本
set<Folder*>folders; //包含本Message的Folder
//拷贝构造函数、拷贝赋值运算符和析构函数所使用的工具函数
//将本Message添加到指向参数的Folder中
void add_to_Folders(const Message&);
//从folders中的每个Folder中删除Message
void remove_from_Folders();
};
#endif
// Message.cpp文件
#include"Folder.h"
#include"Message.h"
//除拷贝控制成员外,Message类只有两个公共成员:save本Message存放在给定Folder中;remove删除本Message
void Message::save(Folder &f) {
folders.insert(&f);//将给定Folder添加到我们的Folder列表中
f.addMsg(this); //将本Message添加到f的Message集合中
}
void Message::remove(Folder &f) {
folders.erase(&f);//将给定Folder从我们的Folder列表中移除
f.remMsg(this); //将本Message从f的Message集合中移除
}
//工具函数
//将本Message添加到指向m的Folder中
void Message::add_to_Folders(const Message&m) {
for (auto f : m.folders) {
f->addMsg(this);
}
}
//拷贝构造函数
Message::Message(const Message&m) :
contents(m.contents), folders(m.folders) {
add_to_Folders(m);
}
//当一个Message被销毁时,我们必须从指向此Message的Folder中删除它,把这个操作也抽象成一个函数
//从对应的Folder中删除本Message
void Message::remove_from_Folders() {
for (auto f : folders)
f->remMsg(this);
}
//析构函数:
Message::~Message() {
remove_from_Folders();
}
//拷贝赋值运算符
//我们先从左侧运算对象的folders中删除此Message的指针,
//然后再将指针添加到右侧运算对象的folders中,
//从而实现了自赋值的正确处理
Message& Message::operator=(const Message&rhs) {
//通过先删除指针再插入它们来处理自赋值情况
remove_from_Folders(); //更新已有Folder
contents = rhs.contents; //从rhs拷贝消息内容
folders = rhs.folders; //从rhs拷贝Folder指针
add_to_Folders(rhs); //将本Message添加到那些Folder中
return *this;
}
//Message的swap函数
void swap(Message &lhs, Message &rhs)
{
using std::swap; //在本例中严格来说并需要,但这是一个好习惯
//将每个消息的指针从其所在的Folder中删除
for(auto f : lhs.folders)
{
f->remMsg(&lhs);
}
for(auto f : rhs.folders)
{
f->remMsg(&rhs);
}
//交换contents和Folder指针set,调用的都是标准库函数
swap(lhs.folders, rhs.folders); //使用swap(set&, set&)
swap(lhs.contents, rhs.contents); //swap(string&,string&)
//将每个Message的指针添加到新Folder中
for(auto f : lhs.folders)
{
f->addMsg(&lhs);
}
for(auto f : rhs.folders)
{
f->addMsg(&rhs);
}
}
- Folder类:
// Folder.h文件
#ifndef __FOLDER__
#define __FOLDER__
#include<iostream>
#include<set>
#include<string>
using namespace std;
class Message;
class Folder {
public:
Folder() {}
Folder(const Folder &f) :message(f.message) { add_to_message(f); }
Folder& operator=(const Folder&f) {
remove_from_message();
message = f.message;
add_to_message(f);
return *this;
}
~Folder() {
remove_from_message();
}
void addMsg(Message *m) {
message.insert(m);
}
void remMsg(Message *m) {
message.erase(m);
}
void printMsg();
private:
set<Message*>message;
void add_to_message(const Folder &f);
void remove_from_message();
};
#endif
// Folder.cpp文件
#include"Folder.h"
#include"Message.h"
void Folder::add_to_message(const Folder &f) {
for (auto msg : f.message) {
msg->addFldr(this);
}
}
void Folder::remove_from_message() {
while (!message.empty()) {
(*message.begin())->remove(*this);
}
}
void Folder::printMsg() {
for (auto m : message) {
cout << "message.contents: " << (*m).contents << endl;
}
}
- 测试函数:
Message m1("hello,m1");
Folder f1,f2,f3,f4;
m1.save(f1);
m1.save(f3);
Message m2("hello,m2");
m2.save(f1);
m2.save(f2);
m2.save(f4);
Message m3("hello,m3");
m3.save(f2);
m3.save(f3);
m3.save(f4);
cout << "f1:" << endl;
f1.printMsg();
cout << "f2:" << endl;
f2.printMsg();
cout << "f3:" << endl;
f3.printMsg();
cout << "f4:" << endl;
f4.printMsg();
m1.remove(f1);
m2.remove(f2);
m3.remove(f3);
cout << "f1:" << endl;
f1.printMsg();
cout << "f2:" << endl;
f2.printMsg();
cout << "f3:" << endl;
f3.printMsg();
cout << "f4:" << endl;
f4.printMsg();
/*
输出结果:
f1:
message.contents: hello,m2
message.contents: hello,m1
f2:
message.contents: hello,m3
message.contents: hello,m2
f3:
message.contents: hello,m3
message.contents: hello,m1
f4:
message.contents: hello,m3
message.contents: hello,m2
f1:
message.contents: hello,m2
f2:
message.contents: hello,m3
f3:
message.contents: hello,m1
f4:
message.contents: hello,m3
message.contents: hello,m2
*/
5. 动态内存管理类:实现vector示例
- 当类需要在运行时分配可变大小的内存空间时,通常使用标准库容器保存其数据。
若类需要自己进行内存分配,则必须定义自己的拷贝控制成员来管理所分配的内存。 - StrVec类的设计:主要参照vector
来。 - 我们实现标准库vector类的一个简化版本,即不使用模板,只用于string。
- vector类将其元素保存在连续内存中。为了获得可接受的性能,vector预先分配足够的内存来保存可能需要的更多元素。vector的每个添加元素的成员函数会检查是否有空间容纳更多的元素。如果有,成员函数会在下一个可用位置构造一个新对象。如果没有可用空间,vector就会重新分配空间:它获得新的空间,将已有元素移动到新空间中,释放旧空间,并添加新元素。
- 我们将使用allocator来获得原始内存,由于它分配的内存是未构造的,我们将需要在添加新元素是用allocator的construct成员在原始内存中创建对象;同样的,我们在删除元素时就使用destroy成员来销毁函数。
- 内存管理类需要包括以下几个基本操作的正确性
- (1)添加元素:判断管理的空间大小是否能够添加新元素,如不够,则使用allocator分配内存,并将旧数据移动到新内存,然后释放旧内存,并更新内存首指针、第一个可用内存指针、尾指针位置。
- (2)对象拷贝:使用allocator的allocate分配内存,相关的uninitialized_copy拷贝元素到新的位置,并更新内存首指针、第一个可用内存指针、尾指针位置。
- (3)内存释放:使用allocator的destroy销毁内存,并使用deallocate执行内存回收操作
- 注意:静态对象必须首先在类外进行初始化操作。
- 每个StrVec有三个指针成员指向其元素所使用的内存:
- elements,指向首元素
- first_free,尾后元素
- cap,指向分配的内存末尾之后的位置

- StrVec还有一个名为alloc的静态成员,其类型为allocator
。alloc成员会分配StrVec使用的内存。我们的类还有4个工具函数: - alloc_n_copy会分配内存,并拷贝一个给定范围内的元素
- free会销毁构造的元素并释放内存
- chk_n_alloc保证StrVec至少有容纳一个新元素的空间,如果空间不够的话,它会调用reallocate来分配更多内存
- reallocate在内存用完时为StrVec分配新内存
- reallocate成员函数
- 移动构造函数
- 通过使用标准库引入的两种机制,我们就可以避免string的拷贝。有一些标准库类,包括string,都定义了所谓的“移动构造函数”,移动构造函数通常是将资源从给定对象“移动”而不是拷贝到正在创建的对象。
- std::move
- 标准库函数move,定义在utility头文件中。关于move,我们需要了解两个关键点,首先,当reallocate在新内存中构造string时,它必须调用move来表示希望使用string的移动构造函数。如果它漏掉了move调用,将会使用string的拷贝构造函数。其次,我们通常不为move提供一个using声明,当我们使用move时,直接调用std::move而不是move
- 移动构造函数
- StrVec代码 参考1 参考2 参考3
#ifndef STRVEC_H
#define STRVEC_H
#include<iostream>
#include<memory>
#include <string>
using namespace std;
class StrVec
{
public:
//默认构造函数(隐式)初始化alloc,(显式)初始化element,first_free和cap,表明没有元素
//allocator成员进行默认初始化
StrVec():elements(nullptr),first_free(nullptr),cap(nullptr) {};//默认构造函数
StrVec(const StrVec&);//拷贝构造函数
StrVec &operator=(const StrVec&);//拷贝赋值运算符
~StrVec();//析构函数
void push_back(const string&);//拷贝元素
size_t size() const { return first_free - elements; } //常量函数,指不会改变成员变量的值的函数
size_t capacity() const { return cap - elements; }
string *begin() const { return elements; }
string *end() const { return first_free; }
//…
private:
//设置为static很巧妙,只初始化一次,且在对象分配前就初始化,所有对象共用一个
static allocator<string> alloc; //分配元素
//被添加元素的函数使用
void chk_n_alloc() {
if (size() == capacity())
reallocate();
}
//工具函数,被拷贝构造函数、赋值运算符和析构函数所使用
//类似容器,pair是用来生成特定类型的模板。map的value_type就是一个pair
pair<string*, string*> alloc_n_copy(const string*,const string*);
void free();//销毁元素并释放内存
void reallocate();//获得更多内存并拷贝已有元素
string * elements;//指向数组首元素的指针
string * first_free;//指向数组第一个空闲元素的指针
string * cap;//指向数组尾后位置的指针
};
//添加对象函数
void StrVec::push_back(const string&s) {
chk_n_alloc(); //先查看当前是否还有空间容纳新元素,若没有则重新分配新空间
//在first_free位置构造元素
alloc.construct(first_free++,s);
//先使用在原first_free处插入s,而后将first_free后移一个元素位置,依旧指向尾后
}
//当我们拷贝或赋值StrVec时,必须分配独立的内存,并从原StrVec对象拷贝元素至新对象,此时可能会调用alloc_n_copy成员
//分配足够的内存来保存给定范围的元素,并将这些元素拷贝到新分配的内存中
//此函数返回一个指针的pair,两个指针分别指向新空间的开始位置和拷贝的尾后的位置
pair<string*, string*> StrVec::alloc_n_copy(const string*b, const string*e) {
//分配正好的空间保存给定范围中的元素
auto data = alloc.allocate(e-b);
//初始化并返回一个pair,该pair由data和uninitialized_copy返回的指向最后一个构造元素之后的位置构成
return (data, uninitialized_copy(b, e, data));
}
void StrVec::free() {
//注意不能传递给deallocate一个空指针,如果element为0,则函数不需执行
if (elements) {
//destroy是逆序销毁旧元素
for (auto ptr = first_free;ptr != elements;/*空*/) {
alloc.destroy(--ptr);
//destroy函数是对p指向的元素进行析构,因此先p减一使得p指向最后一个元素,而不是尾后
}
alloc.deallocate(elements, cap-elements);
//调用deallocate来释放本StrVec对象分配的空间
}
}
//在实现了alloc_n_copy和free函数后,类的拷贝控制成员实现就相对简单
//拷贝构造函数
StrVec::StrVec(const StrVec&s) {
//调用alloc_n_copy分配空间以容纳与s中一样多的元素
auto newdata = alloc_n_copy(s.begin(), s.end());//使用begin和end将底层返回的element和first_free隐藏了
elements = newdata.first;
first_free = cap = newdata.second;
}
//析构函数
StrVec::~StrVec() {
free();
}
//拷贝赋值运算符
StrVec & StrVec::operator=(const StrVec&rhs) {
//调用alloc_n_copy分配内存,大小与rhs中内存占用空间一样多
auto data = alloc_n_copy(rhs.begin(), rhs.end());
free();
elements = data.first;
first_free = cap = data.second;
return *this;
}
/*
在实现reallocate函数时,我们需要做的是移动而不是拷贝元素
{
在设计reallocate函数时,我们思考一下函数的工作
1. 为一个新的,更大的string数组分配内存
2. 在内存空间的前一部分构造对象,保存现有元素
3. 销毁原空间中的元素,并释放这块内存
但是,为一个StrVec重新分配内存空间会引起从旧内存空间到新内存空间逐个拷贝string
string由类值行为,当拷贝一个string时,新string和旧string时相互独立的。
如果是reallocate拷贝StrVec中的string,则拷贝之后,我们就要立即销毁原空间
}
在重新分配内存空间时,我们如果能避免分配和释放string的额外开销,StrVec的性能会提高不少
{
使用移动构造函数和std::move避免string拷贝
移动构造函数通常是将资源从给定对象“移动”而不是拷贝到正在创建的对象,同时保证移动后的string仍然保持一个有效的、可析构的状态。对于string可以想象为每个string都有一个指向char数组的指针,而移动构造函数进行了指针的拷贝,而不是分配空间然后拷贝字符。
move标准库函数,定义在utility头文件中。
当reallocate在新内存中构造string时,它必须调用move来表示希望使用string的移动构造函数。
如果漏掉了move的调用,将会使用string的拷贝构造函数,调用时直接调用std::move
}
*/
//为一个新的更大的string数组分配内存
//在内存空间的前一部分构造对象,保存现有元素
//销毁原内存空间中的元素,并释放这块内存
void StrVec::reallocate() {
//我们重新分配时,为新空间分配当前空间的两倍
auto newcapacity = size() ? 2 * size() : 1;
//分配新内存
auto newdata = alloc.allocate(newcapacity); //返回的是指向第一个元素的位置的指针
//将数据从旧内存移动到新内存
auto dest = newdata;//指向新数组中下一个空闲位置
auto elem = elements;//指向旧数组中下一个元素
for (size_t i = 0;i != size();++i) {
alloc.construct(dest++,std::move(*elem++));
//在新分配的空间,从dest开始,每个元素进行创建,由move表示希望不是元素的拷贝而是移动
}
free();//一旦我们移动完元素就释放旧内存空间
//更新我们的数据结构,执行新元素
elements = newdata;
first_free = dest;
cap = elements + newcapacity;
//alloc_n_copy返回的是一个pair。其first成员指向第一个构造的元素,second指向最后一个元素尾后
//由于函数分配的空间恰好是容纳给定的元素,因此cap和first_free指向相同的位置
}
#endif
// 测试代码:
void printSize(StrVec &s) {
cout << "size(): " << s.size() << endl;
cout << "capacity(): " << s.capacity() << endl;
cout << endl;
}
void testStrVec() {
StrVec s;
printSize(s);
for (int i = 0;i <10;i++) {
s.push_back(to_string(i));
printSize(s);
}
for (auto beg = s.begin();beg != s.end();beg++) {
cout << *beg<<" ";
}
}
int main() {
testStrVec();
system("pause");
return 0;
}
/*
输出结果:从输出结果可以看出,当进行push_back操作时,若没有空间添加新元素,则将分配当前大小两倍的内存空间
size(): 0
capacity(): 0
size(): 1
capacity(): 1
size(): 2
capacity(): 2
size(): 3
capacity(): 4
size(): 4
capacity(): 4
size(): 5
capacity(): 8
size(): 6
capacity(): 8
size(): 7
capacity(): 8
size(): 8
capacity(): 8
size(): 9
capacity(): 16
size(): 10
capacity(): 16
0 1 2 3 4 5 6 7 8 9
*/
6. 对象移动:新标准的一个最主要的特性是可以移动而非拷贝对象的能力
- 新标准的一个最主要的特性是可以移动而非拷贝对象的能力。在某些情况下,当拷贝一个对象之后,被拷贝的对象马上就不使用了,此时可以换成另外一种方式:将被拷贝对象的内容移动到拷贝对象里面,从而可以消除拷贝的消耗来提升程序的性能*
- 引入移动对象的原因:
- 原因1:新标准的一个最主要的特性是可以移动而非拷贝对象的能力。在某些情况下,对象拷贝后就立即被销毁了,此时移动而非拷贝对象会大幅度提升性能。
- 在某些情况下,当拷贝一个对象之后,被拷贝的对象马上就不使用了,此时可以换成另外一种方式:将被拷贝对象的内容移动到拷贝对象里面,从而可以消除拷贝的消耗来提升程序的性能*
- 在上面设计StrVec类时,在重新分配内存的过程中,从旧内存将元素拷贝到新内存是不必要的,更好的方式是移动元素
- 原因2:有些类型是不能被拷贝的,例如IO类和unique_ptr,这些类都包含不能被共享的资源(如指针或IO缓冲)。在旧标准中我们无法在容器中保存它们,因为它们无法被拷贝,就不存在赋值之类的操作,但引入了移动操作后,我们就可以用容器保存它们。这些类型的对象不能拷贝但可以移动。
- 原因1:新标准的一个最主要的特性是可以移动而非拷贝对象的能力。在某些情况下,对象拷贝后就立即被销毁了,此时移动而非拷贝对象会大幅度提升性能。
- 标准库容器、string和shared_ptr类既支持移动也支持拷贝。IO类和unique_ptr类可以移动但不能拷贝。
6.1 右值引用:使用&&获取
- 为了支持移动操作,新标准引入了一种新的引用类型:右值引用。
右值引用 vs 左值引用
- 所谓右值引用就是必须绑定到右值的引用。我们通过&&而不是&来获得右值引用。
- &&获取右值引用
- &获取常规引用或者说左值引用
- 右值引用有一个重要的性质:只能绑定到一个将要销毁的对象。因此我们可以自由地将一个右值引用的资源“移动”到另一个对象中。
- 左值和右值是表达式的属性:
- 左值表达式表示一个对象的身份,右值表达式表示对象的值。
- 左值有持久的状态,右值只能是字面常量或表达式求值过程中创建的临时对象。
- 总结:左值表身份右值表值
- 对于常规引用(左值引用),我们不能将其绑定到要求转换的表达式、字面常量或是返回右值的表达式。右值引用有着完全相反的绑定特性:我们可以将一个右值引用绑定到这类表达式上,但不能将一个右值引用直接绑定到一个左值上。
int i=42;
int &r=i; //正确:r引用i
int &&rr=i; //错误:不能将一个右值引用绑定到一个左值上
int &r2=i*42;//错误:i*42是一个右值
const int &r3=i*42;//正确:我们可以将一个const的引用绑定到一个右值上
int &&rr2=i*42; //正确:将rr2绑定到乘法结果上
- 要记住哪些表达式返回右值,哪些返回左值,以便正确绑定:
|返回类型|表达式|
|:---|:---|
|左值|返回左值引用的函数、赋值、下标、解引用、前置递增递减运算符|
|右值|返回非引用类型的函数、算术、关系、位运算符、后置递增递减运算符| - 左值引用就可以绑定到类型为左值的表达式;右值引用以及const左值引用可以绑定到类型为右值的表达式
- 非const左值引用可以绑定赋值、下标、解引用、前置递增/递减、返回左值引用的函数;
- const左值引用和右值引用可以绑定算术、关系、位、后置递增/递减、要求转换的表达式、字面常量、返回右值的表达式
- 记住:左值持久,右值短暂——右值是临时的,是即将销毁的,左值长期存在
- 左值有持久状态
- 右值要么是字面常量(const),要么是在表达式求值过程中创建的临时对象
- 右值引用只能绑定到临时对象:
- 引用的对象将被销毁
- 该对象没有其他用户
- 这两个特性意味着:使用右值引用的代码可以自由地接管所引用的对象的资源。
- 变量本身是左值:
- 变量表达式都是左值,变量是持久的,直至离开作用域时才被销毁;
- 不能将一个右值引用直接绑定到一个变量上,即使这个变量是右值引用类型也不行
int &&rr1 = 42;//正确
int &&rr2 = rr1;//错误,表达式rr1为变量是左值
标准库函数move函数:将左值转换为对应的右值引用类型
- 标准库函数move函数:std::move,定义在头文件
- 将左值转换为(对应的)右值引用(类型)。
- 移后源对象(使用std::move后的对象)可以被销毁或赋值,但不能使用其值。
int a = 12;
int &&b = std::move(a) //move函数告诉编译器,我们要把这个左值当成右值来处理
- move调用告诉编译器:有一个左值,但我们希望像一个右值一样处理它.
- 调用move就意味着:除了对a赋值或销毁外,我们将不再使用它,例如我们不能把它的值赋给别人——我们可以销毁一个移后源对象,也可以赋予它新值,但不能使用一个移后源对象的值
- 注意:对move我们不提供using声明;使用move,应该直接使用std::move而不是move,这样可以避免潜在的名字冲突
6.2 移动构造函数和移动赋值函数:从给定对象“窃取”资源而不是拷贝资源
- 为了让我们自己的类型支持移动操作,需要为其定义移动构造函数和移动赋值运算符。
- 这两个成员类似对应的拷贝操作,但它们从给定对象“窃取”资源而不是拷贝资源。
移动构造函数:T(T &&tmp):初始化列表{}
- 移动构造函数第一个参数是非const的右值引用,任何额外参数必须有默认实参
- 除了完成资源移动,移动构造函数还必须确保移后源对象处于这样一个状态:销毁它是无害的。
- 特别是,一旦资源完成移动,源对象必须不再指向被移动的资源—,这些资源的所有权已经归属新创建的对象。
- 移动构造函数,需要满足如下要求:
- 形参为该类型的右值引用
- 除此之外的形参都应该有默认值
- 必须保证移后源对象处于可销毁的状态
- 定义自己的移动构造函数,该函数的形参是一个右值引用。如下例子:
//noexcept通知标准库我们的构造函数不抛出任何异常
StrVec::StrVec(StrVec &&s) noexcept //移动操作不应抛出任何异常
:elements(s.elements),first_free(s.first_free),cap(s.cap) //只要是构造函数都可以列表初始化;通过初始化列表完成移动
{
s.elements = s.first_free = s.cap=nullptr;
//s把资源给了新对象后,自己变成空指针
}
/*
上面的例子,相较于拷贝构造函数而言,它直接将右侧对象的资源的指针,复制过来,这样节省了拷贝指针指向资源的耗时操作。
然后再将右侧对象的资源的指针清空,这样可以保证这个右侧对象处在一个可安全销毁的状态下.
与构造函数不同,移动构造函数不分配任何新内存;它接管给定的StrVec中的内存。
在接管内存之后,它将给定对象中的指针都置为nullptr。这样就完成了从给定对象的移动操作,此对象将继续存在。
最终,移后源对象会被销毁,意味着将在其上运行析构函数。StrVec的析构函数在first_free上调用deallocate。
注意:如果我们忘记将s.elements ,s.first_free,s.cap指针置空,则销毁移后源对象就会释放掉我们刚刚移动的内存。
*/
移动操作、标准库容器和异常:指定noexcept,不抛出异常
- 由于移动操作“窃取”资源,它通常不分配任何资源。因此,移动操作通常不会抛出任何异常。当编写一个不抛出异常的移动操作时,我们应该将此事通知标准库。我们将看到,除非标准库知道我们的移动构造函数不会抛出异常,否则它会认为移动我们的类对象时,可能会抛出异常,并且为了处理这种可能性而做一些额外的工作。
- 我们在一个函数的参数列表后指定noexcept,即为通知标准库函数不抛出异常。
- 在一个构造函数中,noexcept出现在参数列表和初始化列表开始的冒号之间
class StrVec{
public:
StrVec(StrVec&&) noexcept; // 移动构造函数
//其他成员的定义
};
StrVec::StrVec(StrVec &&s) noexcept: /*列表初始化/成员初始化器*/
{ /* 构造函数体 */}
- 我们必须在类头文件的声明和定义中(如果定义在类外的话)都指定noexcept
- 为什么需要noexcept
- 移动构造函数,在移动自己的成员时,需要明确知道自己的成员在移动的时候,不能出错。如果没有明确的告知,那么就不会使用成员的移动构造函数,而是使用成员的拷贝构造函数。
- noexcept标记这个移动构造函数是安全的.
- 不抛出异常的移动构造函数和移动赋值运算符必须标记为noexcept
移动赋值运算符:定义:T& operator=(T &&tmp) noexcept
- 移动赋值运算符执行与析构函数和移动构造函数相同的工作。
- 与移动构造函数一样,如果我们的移动赋值运算符不抛出任何异常,我们就应该将它标记为noexcept。
- 类似拷贝赋值运算符,移动赋值运算符必须正确处理自赋值:
// StrVec的移动赋值运算符示例:
StrVec & StrVec::operator=(StrVec &&rhs) noexcept {
//直接检查自赋值情况
if (this!=&rhs) {
free();//释放已有元素
elements = rhs.elements;//从rhs接管资源
first_free = rhs.first_free;
cap = rhs.cap;
//将rhs置于可析构状态
rhs.elements = rhs.first_free = rhs.cap = nullptr;
}
return *this;
}
/*
在此例中,我们直接检查this指针与rhs的地址是否相同。
如果相同,右侧和左侧运算对象指向相同的对象,我们不需要做任何事情。
否则,我们释放左侧运算对象所使用的内存,并接管给定对象的内存。
与移动构造函数一样,我们将rhs中的指针置为nullptr。
*/
- 与其他任何赋值运算符一样,关键点是我们不能在使用右侧运算对象的资源之前就释放左侧运算对象的资源(可能是相同的资源)
移后源对象必须可析构:通过将移后源对象的指针成员置为nullptr来实现
- 从一个对象移动数据并不会销毁此对象,但有时在移动操作完成后,源对象会被销毁。因此,当我们编写一个移动操作时,必须确保移后源对象进入一个可析构的状态。我们的StrVec的移动操作满足这一要求,这是通过将移后源对象的指针成员置为nullptr来实现的。
- 在移动操作之后,移后源对象必须保持有效的、可析构的状态,但是用户不能对其值进行任何假设(即最好不要去动它,除了析构它之外,让它安静地功成身退)
合成的移动操作
- 合成的移动操作:没有自定义拷贝控制成员+每个非static数据成员都可以移动时才会合成移动操作。
- 自定义移动操作的类必须定义自己的拷贝操作,否则合成拷贝构造函数和合成拷贝赋值运算符会被定义为删除的。
- 与处理拷贝构造函数和拷贝赋值运算符一样,编译器也会合成移动构造函数和移动赋值运算符。 但是合成移动操作的条件与合成拷贝操作的条件大不相同。
- 与拷贝操作不同,编译器根本不会为某些类合成移动操作。特别是,如果一个类定义了自己的拷贝控制成员(拷贝构造函数、拷贝赋值运算符或者析构函数),编译器就不会为它合成移动构造函数和移动赋值运算符了。因此某些类就没有移动构造函数或移动赋值运算符。如果一个类没有移动操作,通过正常的函数匹配,类会使用对应的拷贝操作来代替移动操作。
- 只有当一个类没有定义任何自己版本的拷贝控制成员,且类的每个非static数据成员都可以移动时,编译器才会为它合成移动构造函数或移动赋值运算符。编译器可以移动内置类型的成员。如果一个成员是类类型,且该类有对应的移动操作,编译器也能移动这个成员:
// 编译器会为X和hasX合成移动操作:
struct X{
private:
int i; //内置类型可以移动
string s; //string定义了自己的移动操作
}
struct hasX{
X mem; //X有合成的移动操作
}
X x, x2 = std::move(x); //使用合成的移动构造函数
hasX hx, hx2=std::move(hx); //使用合成的移动构造函数
移动操作永远不会隐式定义为删除的函数

- 与拷贝操作不同,移动构造函数永远都不会隐式定义为删除的函数。然而如果我们用=default来要求编译器显式合成移动操作,但是有些成员不能被移动,则编译器会将移动操作定义为删除的函数(不让你用),如:
// 假定Y是一个类,他定义了自己的拷贝构造函数,但未定义自己的移动构造函数
struct hasY{
hasY() = default;
hasY(hasY &&) = default;
Y mem;
// hasY将有一个删除的移动构造函数
};
hasY hy,hy2 = std::move(hy);//错误,移动构造函数是删除的
- 移动操作指的是:移动构造函数、移动赋值运算符
- 如下情况将定义一个删除的移动操作(何时移动操作是删除的):
| =delete | 原因 |
|---|---|
| 移动构造函数 | 1、类成员定义自己的拷贝构造函数且未定义移动构造函数 2、类成员未定义自己的拷贝构造函数且编译器不能合成移动构造函数 3、类成员的移动构造函数被定义为删除的或不可访问的 4、类的析构函数被定义为删除的或不可访问的(类似拷贝构造函数) |
| 移动赋值运算符 | 1、类成员定义自己的拷贝赋值运算符且未定义移动赋值运算符 2、类成员未定义自己的拷贝赋值运算符且编译器不能合成移动赋值运算符 3、类成员的移动赋值运算符被定义为删除的或不可访问的 4、有类成员是const或引用(类似拷贝赋值运算符) |
- 移动操作和合成拷贝控制成员间的相互作用关系:
- 如果一个类定义了一个移动构造函数和/或一个移动赋值运算符,则该类的合成拷贝构造函数和拷贝赋值运算符会被定义为删除的。
- 定义了移动操作的类必须也定义自己的拷贝操作,否则这些合成的拷贝控制成员默认地被定义为删除的
何时调用拷贝,何时调用移动
- (1)若类中拷贝操作与移动操作同时存在,则进行函数匹配:
- 实参是左值的函数会使用拷贝操作,实参是右值的函数会使用移动操作
- 即:移动右值,拷贝左值
StrVec v1,v2;
v1=v2; //v2是左值,使用拷贝赋值
StrVec getVec(istream &);//getVec返回一个右值
v2=getVec(cin);//getVec(cin)是一个右值,使用移动赋值
- (2)若类中只有拷贝操作且实参是右值,则会调用拷贝操作。
- 如果一个类有一个拷贝构造函数但未定义移动构造函数,在此情况下,编译器不会合成移动构造函数,这意味着此类将有拷贝构造函数但不会有移动构造函数
class Foo{
public:
Foo() = default;
Foo(const Foo&);//拷贝构造函数
...
}
Foo x;
Foo y(x);//拷贝构造函数,x是一个左值
Foo z(std::move(x));//拷贝构造函数,因为未定义移动构造函数
//std::move(x)返回一个绑定到x的Foo&&,因为没有移动构造函数,因此我们可以将一个Foo&&转换为一个const Foo&,因此使用拷贝构造函数
- 移动赋值运算符和拷贝赋值运算符可以是同一个函数:
- 可以使用一个单一赋值运算符实现拷贝赋值运算符和移动赋值运算符两种功能:
class HasPtr{
public:
//添加的移动构造函数
HasPtr(HasPtr &&p) noexcept:ps(p.ps),i(p.i){p.ps = 0}
//赋值运算符既是移动赋值运算符,也是拷贝赋值运算符
HasPtr& operator=(HasPtr rhs){
swap(*this,rhs);
return *this;
}
};
// 该赋值运算符可以实现两种功能的原因:此运算符有一个非引用参数,所以实参传过来的时候,形参要进行拷贝初始化
// 拷贝初始化方式根据实参类型选择调用拷贝构造函数或移动构造函数——左值被拷贝,右值被移动:
HasPtr hp, hp2; //调用默认构造函数初始化
hp = hp2; //hp2作为变量是个左值,调用拷贝构造函数来赋值
hp = std::move(hp2); //强行右值,调用移动构造函数来移动hp2
- 移动操作的好处-举个例子
// 我们以之前的邮件类为例:通过定义移动操作,Message类可以使用string和set的移动操作来避免拷贝contents和folders成员的额外开销。
// 除了移动folders成员外,我们还要更新每个指向原Message的Folder-删除指向旧Message的指针,添加指向新Message的指针。
// 因为移动操作都需要更新Folder指针,我们把它封装成函数以便复用:
void Message::move_Folders(Message *m)
{
folders = std::move(m->folders); //使用set的移动赋值运算符,避免了不必要的拷贝
for(auto f : folders)
{
f->remMsg(m); //从Folder中删除旧Message
f->addMsg(this); //将本Message添加到Folder中
}
m->folders.clear(); //确保销毁m是无害的
}
// 接下来就可以很方便地自定义移动操作了:
//移动构造函数
Message::Message(Message &&m) : contents(std::move(m.content))
{
move_Folders(&m); //移动folders并更新Folder指针
}
//移动赋值运算符
Message& Message::operator=(Message &&rhs)
{
if(this != &rhs) //检查自赋值
{
remove_from_Folders(); //销毁this指向的旧状态
contents = std::move(rhs.contents); //调用move将rhs的content移动到this对象
move_Folders(&rhs); //更新Folders指向本Message
}
return *this;
}
更新后的三 / 五法则
- 所有五个拷贝控制成员应该看作一个整体:
- 一般来说,如果一个类定义了任何一个拷贝操作,它就应该定义所有五个操作。如前所述,某些类必须定义拷贝构造函数、拷贝赋值运算符和析构函数才能正确工作。这些类通常拥有一个资源,而拷贝成员必须拷贝此资源。
- 一般来说,拷贝一个资源会导致一些额外开销。在这种拷贝并非必要的情况下,定义了移动构造函数和移动赋值运算符的类就可以避免此问题。
移动迭代器:其解引用运算符生成一个右值引用
- 新标准库中定义了一种移动迭代器适配器。一个移动迭代器通过改变给定迭代器的解引用运算符的行为来适配此迭代器。
- 一般来说,一个迭代器的解引用运算符返回一个指向元素的左值。与其他迭代器不同,移动迭代器的解引用运算符生成一个右值引用。
- 通过调用标准库的make_move_iterator函数将一个普通迭代器转换为一个移动迭代器。此函数接受一个迭代器参数,返回一个移动迭代器。
- 原迭代器的所有其他操作在移动迭代器中都照常工作。由于移动迭代器支持正常的迭代器操作,我们可以将一对移动迭代器传递给算法:
void StrVec::reallocate(){
//分配大小两倍于当前规模的内存空间
auto newcapacity = size()?2*size():1;
auto first = alloc.allocate(newcapacity);
//移动元素
auto last = uninitialized_copy(make_move_iterator(begin()),make_move_iterator(end()),first);
free(); //释放旧空间
elements = first; //更新指针
first_free = last;
cap = elements + newcapacity;
}
// uninitialized_copy对输入序列中的每个元素调用construct将元素“拷贝”到目的位置。
// 此算法使用迭代器的解引用运算符从输入序列中提取元素。
// 由于我们传递给它的是移动迭代器,因此解引用运算符生成的是一个右值引用,这意味着construct将使用移动构造函数来构造元素。
- 标准库不保证哪些算法适用移动迭代器,哪些不适用。由于移动一个对象可能销毁原对象,因此只有在确信算法在为一个元素赋值或将其传递给一个用户定义的函数后不再访问它时,才能将移动迭代器传递给算法
- 建议:不要随意使用移动操作,因为你不知道以后源对象是什么状态,而且你也不能再去对它做什么,当然如果你够自信,都是自己良好定义的,那还是鼓励用的。
- 由于一个移后源对象具有不确定的状态,对其调用std::move是危险的。当我们调用move时,必须绝对确认移后源对象没有其他用户
- 通过在类代码中小心地使用move,可以大幅度的提升性能。而如果随意在普通用户代码中使用移动操作,很可能导致莫名其妙的,难以查找的错误,而难以提升应用程序性能
6.3 右值引用和成员函数
- 通常,我们在一个对象上调用成员函数,而不管该对象是一个左值还是一个右值。C++允许向右值赋值,若想阻止该用法,强制使左侧运算对象(即this指向的对象)必须是左值,可在参数列表后放置引用限定符。
- 同时定义拷贝和移动操作的好处:
// 例如,定义了push_back的标准库容器提供两个版本:
void push_back(const X&) //拷贝:绑定到任意类型的X
void push_back(X&&) //移动:只能绑定到类型X的可修改的右值
// 区分移动和拷贝的重载函数通常有两个版本:一个接受const T&,另一个接受T&&
// 对于第一个版本,我们可以将能转换为类型X的任何对象传递给第一个版本的push_back,此版本从其参数拷贝数据。对于第二个版本,我们只可以传递给它非const的右值,因此当我们传递一个可修改的右值时,编译器会选择运行这个版本,此版本会从其参数移动数据。
StrVec vec;
string s = "some string or another";
vec.push(s);//实参是左值,调用push(const string &)
vec.push("done");//实参是右值,调用push(string &&)
右值和左值引用成员函数
- 通常,我们在一个对象上调用成员函数,而不管该对象是一个左值还是一个右值。C++允许向右值赋值,若想阻止该用法,强制使左侧运算对象(即this指向的对象)必须是左值,可在参数列表后放置引用限定符。
string s1 = "a", s2 = "b";
auto n = (s1+s2).find('a'); //我们居然在一个右值上调用函数,右值代表值啊,然而这是可以的。。。主要是因为新旧标准问题
s1 + s2 = "fff"; //这也行的。// 虽然s1+s2返回右值,但它依旧可以调用拷贝赋值运算符来实现赋值。
- 我们指出this的左值 / 右值属性的方式与定义const成员函数相同,即,在参数列表后放置一个引用限定符。
- 引用限定符可以是&或&&,&指出this可以指向一个左值,&&指出this可以指向一个右值。类似const限定符,引用限定符只能用于(非static)成员函数,且必须同时出现在函数的声明和定义中。
class Foo{
pubilic:
Foo &operator=(const Foo&) &;//只能向可修改的左值赋值
};
//声明和定义中都要有引用限定符
Foo & operator=(const Foo &rhs) &{
//...
return *this;
}
- 对于&限定的函数,我们只能将它用于左值;对于&&限定的函数,只能用于右值
Foo &retFoo();//返回引用;retFoo调用返回一个左值
Foo retVal();//返回一个值,retVal调用返回一个右值
Foo i,j;//都是左值
i = j;//正确:i是左值
retFoo() = j;//正确:retFoo返回的是一个左值
retVal() = j;//错误:revVal返回一个右值
i = retVal();//正确
-一个函数可以同时用const和引用限定。若const与引用限定符同时存在,则const必须在前,引用限定符必须在后。(在参数列表后面放const,表示该函数不能修改类中的成员变量)
Foo anothr() const &{}; //把&放在const之后
重载和引用函数
- 一个成员函数可以根据是否有const来区分其重载版本P247,也可以根据引用限定符来区分重载版本,还可综合引用限定符和const来区分重载版本。
class Foo{
public:
Foo sorted() &&;//可用于可改变的右值
Foo sorted() const &;//可用于任何类型的Foo
private:
vector<int> data;
};
//本对象为右值,因此可以原址排序
Foo Foo:sorted() &&{
sort(data.begin(),data.end());
return *this;
}
//本对象是const或是一个左值,哪种情况我们都不能对其进行原址排序
Foo Foo:sorted() const &{
Foo ret(*this);//拷贝一个副本
sort(ret.data.begin(),ret.data.end());//排序副本,我们无法改变this,所以要拷贝个副本来排序返回
return ret;//返回副本
}
- 编译器会根据调用sorted的对象的左值/右值属性来确定使用哪个sorted版本:
Foo &retFoo();//返回引用;retFoo调用返回一个左值
Foo retVal();//返回一个值,retVal调用返回一个右值
retVal().sorted();//retVal是一个右值,调用Foo::sorted() &&
retFoo().sorted();//retFoo是一个左值,调用Foo::sorted() const &
- 当定义const成员函数时,可以定义两个版本,唯一的差别是一个版本有const限定而另一个没有
- 引用限定的函数则不一样。如果我们定义两个或两个以上具有相同名字和相同参数列表的成员函数,就必须对所有函数都加上引用限定符,或者所有都不加:
class Foo{
public:
Foo sorted() &&;
Foo sorted() const;//错误:必须加上引用限定符
//Comp是函数类型的类型别名
//此函数类型可以用来比较int
using Comp = bool(const int &,const int &);
Foo sorted(Comp *);//正确:不同的参数列表
Foo sorted(Comp *) const;//正确:两个版本都没有引用限定符
};
- 总结:如果一个成员函数有引用限定符,则具有相同参数列表的所有版本都必须有引用限定符。
- 要么都不加,要么都加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号