


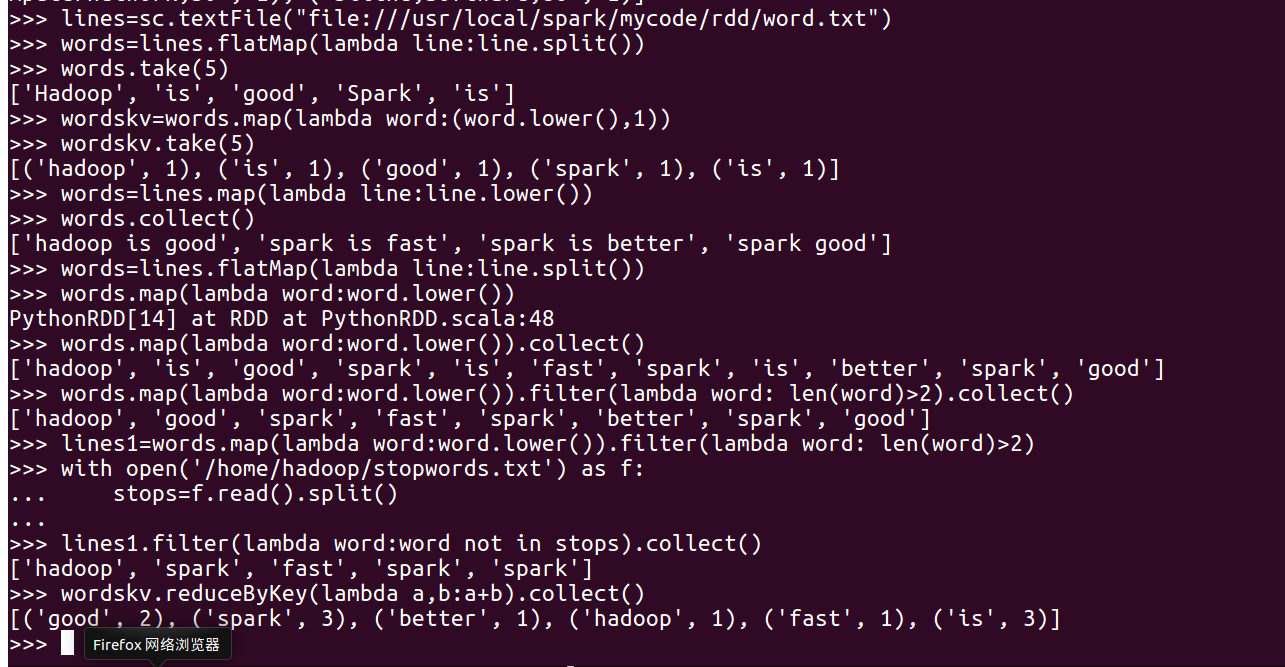
一、词频统计:
- 读文本文件生成RDD lines
- 将一行一行的文本分割成单词 words flatmap()
- 全部转换为小写 lower()
- 去掉长度小于3的单词 filter()
- 去掉停用词
- 转换成键值对 map()
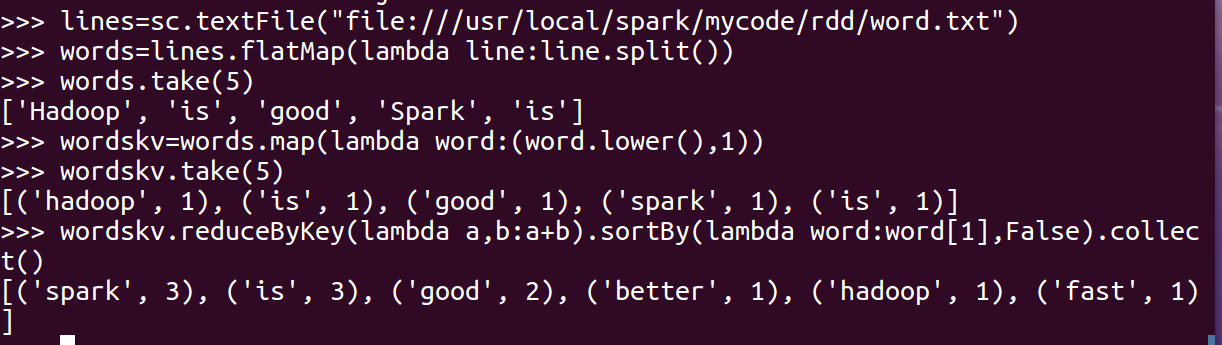
- 统计词频 reduceByKey()
- 按字母顺序排序 sortBy(f)
- 按词频排序 sortByKey()
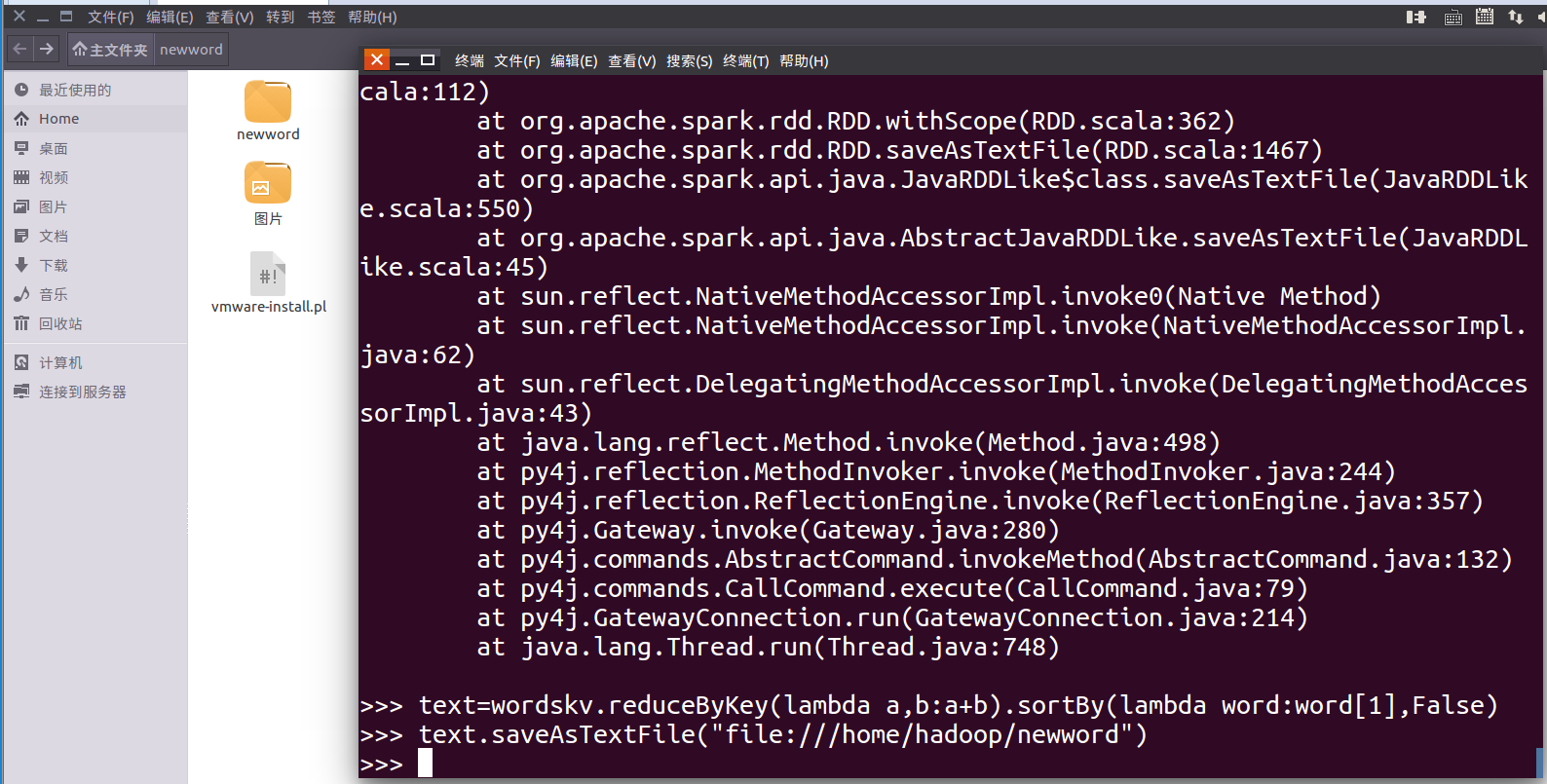
10.结果文件保存 saveAsTextFile(out_url)
二、学生课程分数案例
- 总共有多少学生?map(), distinct(), count()

- 开设了多少门课程?

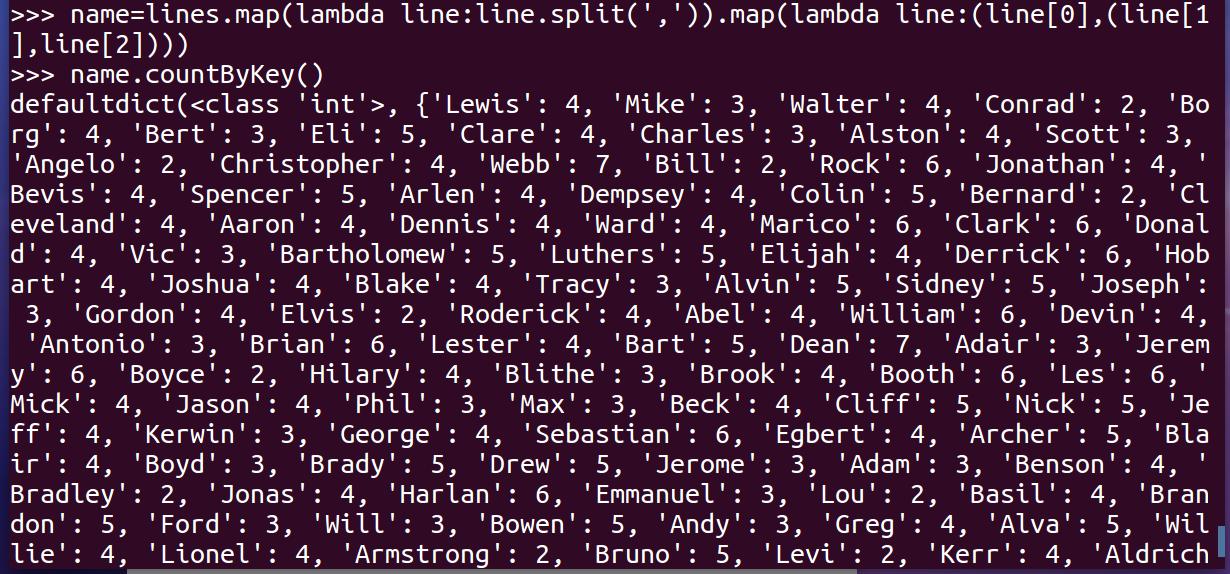
- 每个学生选修了多少门课?map(), countByKey()
- 每门课程有多少个学生选?map(), countByValue()

- Tom选修了几门课?每门课多少分?filter(), map() RDD

- Tom选修了几门课?每门课多少分?map(),lookup() list

- Tom的成绩按分数大小排序。filter(), map(), sortBy()

- Tom的平均分。map(),lookup(),mean()
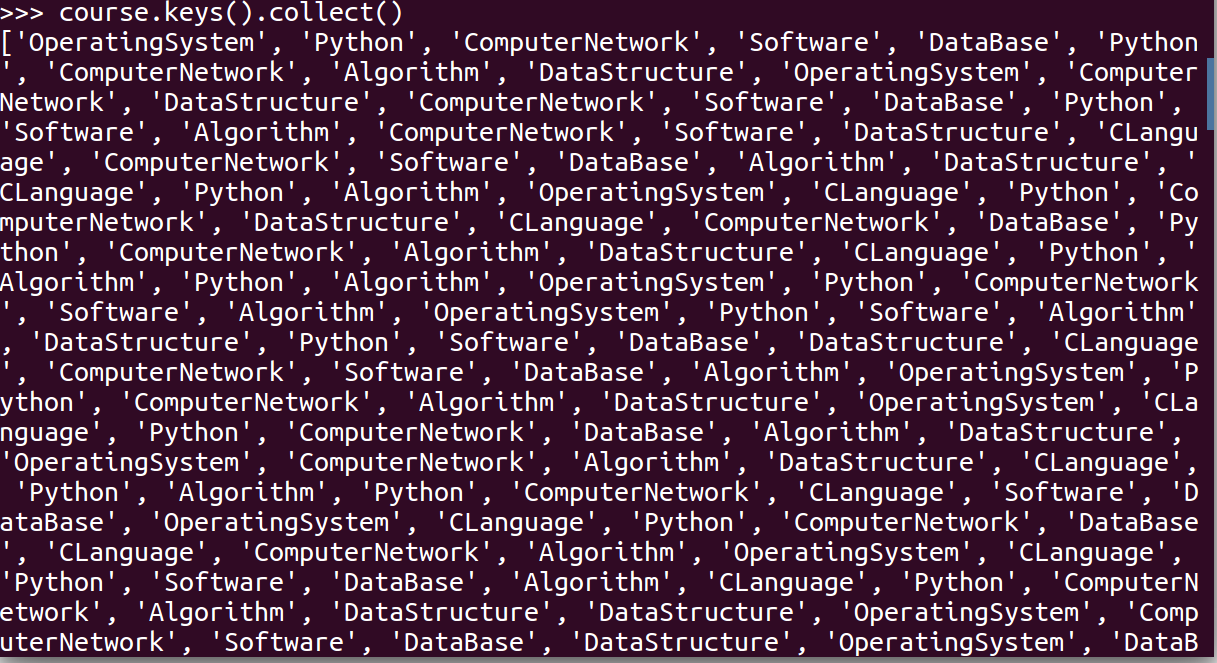
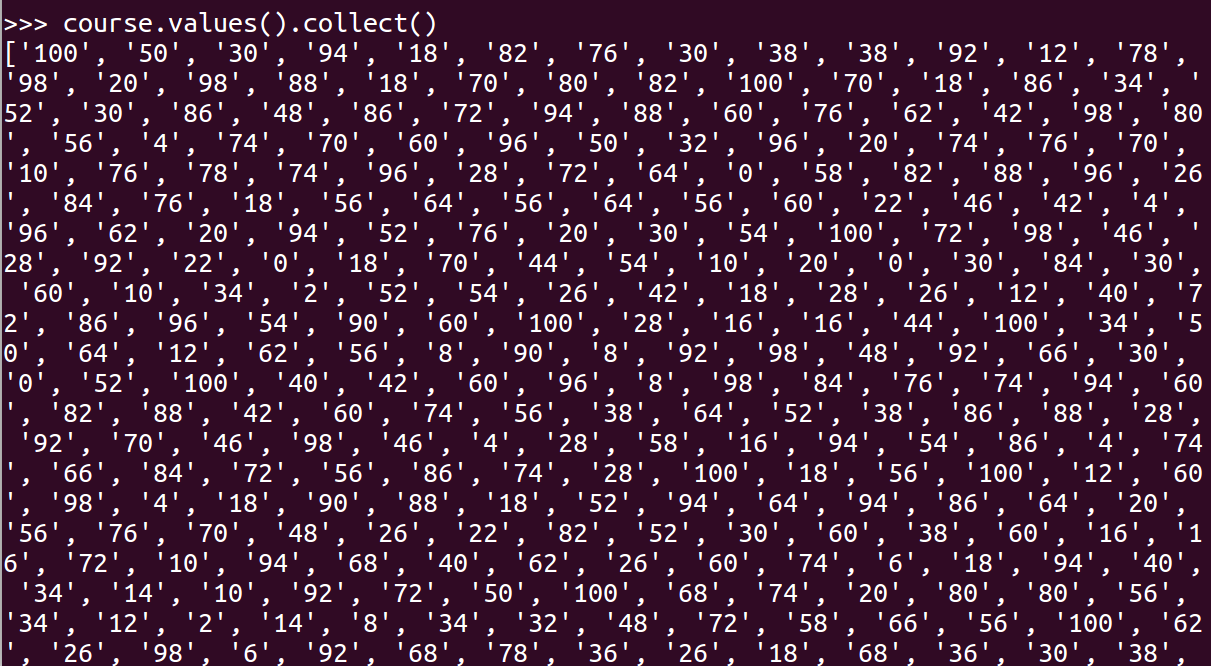
- 生成(课程,分数)RDD,观察keys(),values()
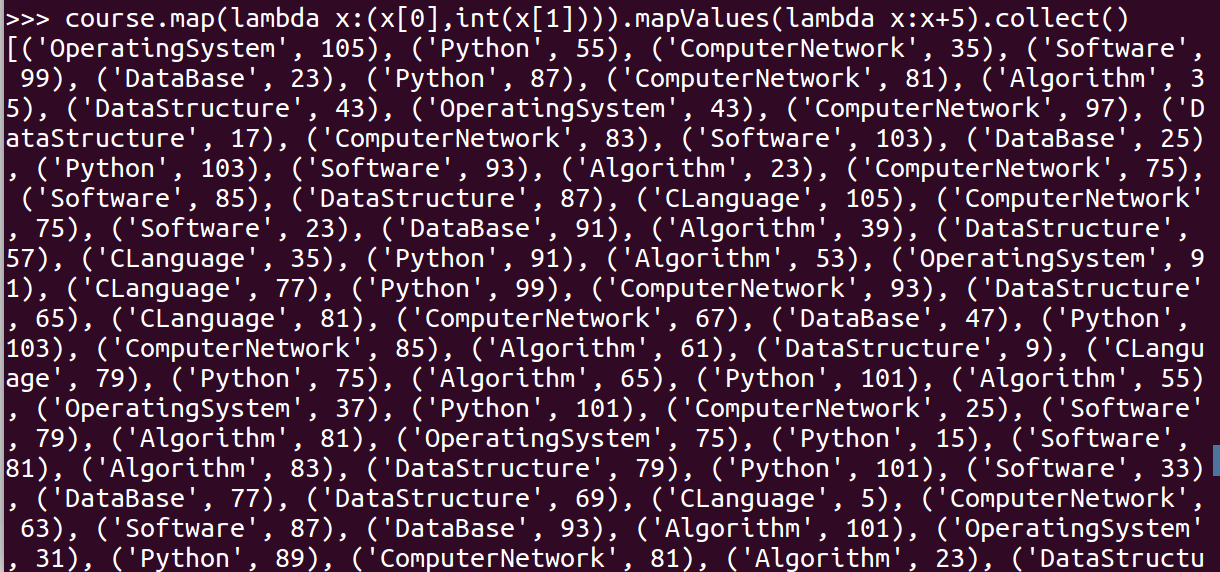
- 每个分数+5分。mapValues(func)
- 求每门课的选修人数及所有人的总分。combineByKey()

- 求每门课的选修人数及平均分,精确到2位小数。map(),round()

- 求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
