

云计算之路-阿里云上:向大家汇报一下今天上午的网站故障
昨天晚上,我们向博客站点的负载均衡中又增加了一台8核CPU的云服务器,一共用24个核跑博客站点。
今天早上,我们修改了程序,记录从memcached与nosql中读取数据的耗时,以确认是不是与memcached/nosql有关。每次故障时,阿里云都要怀疑memcached与nosql,在这上面耗费了很多的时间。
另外,为了进一步减轻Web服务器的CPU负担,我们将memcached从Web服务器中独立了出来。
今天早上9:30的高峰扛了过去,哪知10:00左右问题又开始出现。
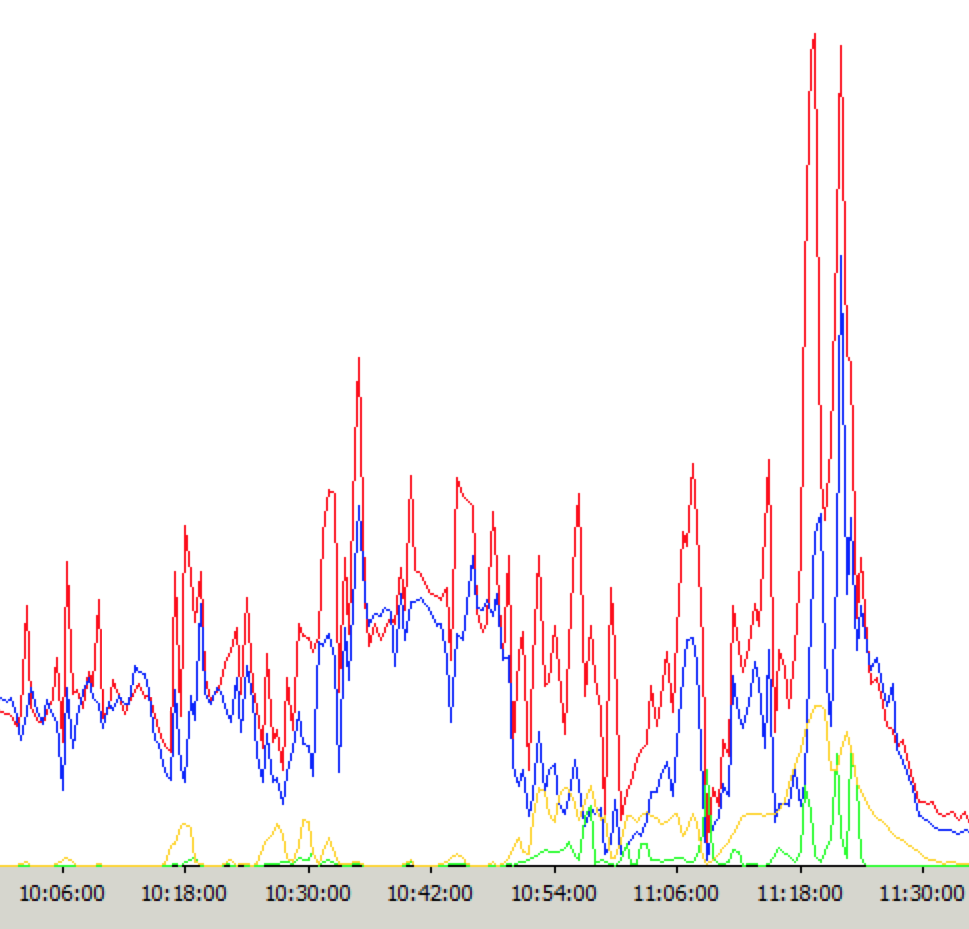
(红色曲线表示的是CPU占用率)
故障期间CPU平均占用率在20%以上。我们增加一台云服务器的目的就是想将CPU平均占用率控制在20%以下,在9:30访问高峰没出问题的时候CPU平均占用率就在20%以下。每次故障,CPU占用率是最直接的反映。这也是我们用了阿里云之后发现的一个很大的不同,以前用物理服务器,我们的Web服务器CPU平均占用率长期在80%以上,一点问题没有。
故障期间单台云服务器的IIS并发连接数由平时的10以内达到我们设置的5000的上限(503错误就是这个引起的),IIS并发连接数暴增由两个可能的原因:一个可能是SLB(负载均衡)出问题扔过来大量额外的请求,一个可能是Web服务器处理能力急聚下降,很多请求得不到处理,越积越多。
我们采用一个方法进行了验证。不走SLB,直接用单台云服务器跑博客站点;如果是SLB的问题,避开它之后问题应该立即缓解。一从SLB切换到单台云服务器,这台云服务器的IIS并发连接数就串到了上万(IIS的连接数限制已取消),对于这么大的连接数,单台云服务器毫无还手之力。以前我们用自己的物理服务器,也是8核CPU,跑的站点还比现在多,2万的IIS并发连接也应对自如。通过这个验证说明了SLB没问题,说明了单台云服务器(虚拟机)虽然用的是2.4G的物理CPU(Azure的虚拟机CPU也只有1.6G),但实际处理能力大打折扣。
在故障期间memcached与nosql的数据读取速度正常,即使禁用memcached与nosql,问题依旧,所以问题与memcached/nosql无关。
通过对今天故障的分析,我们的判断是:云服务器(虚拟机)的CPU处理能力是最大的嫌疑。
我们应对措施是:进一步减轻单台云服务器的负担,将单台云服务器的CPU平均占用率控制在20%以内,目前已经又增加一台8核的Web服务器,用32个核跑博客站点。
相关博文:博客园与啊里云的故障假设:高需与低配



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· 一文掌握DeepSeek本地部署+Page Assist浏览器插件+C#接口调用+局域网访问!全攻略
2010-05-17 上周热点回顾(5.10-5.16)