常见激活函数
理解深度学习中不同激活函数的特点时,可以结合相应的数学公式来更清晰地理解它们。
以下是常见激活函数的特点以及相应的数学公式解释:
- 神经网络为什么需要激活函数:首先数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,强化网络的学习能力。所以激活函数的最大特点就是非线性。
- 不同的激活函数,根据其特点,应用也不同。
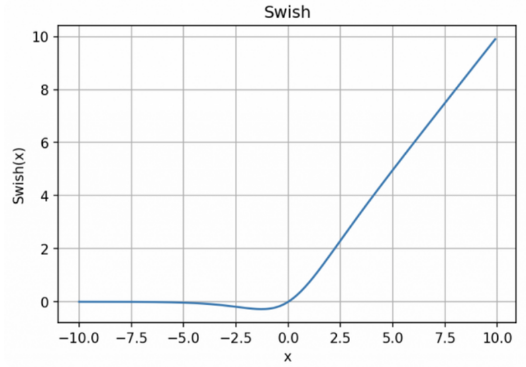
- Sigmoid和tanh的特点是将输出限制在(0,1)和(-1,1)之间,说明Sigmoid和tanh适合做概率值的处理,例如LSTM中的各种门;而ReLU就不行,因为ReLU无最大值限制,可能会出现很大值。
- 同样,根据ReLU的特征,Relu适合用于深层网络的训练,而Sigmoid和tanh则不行,因为它们会出现梯度消失。
-
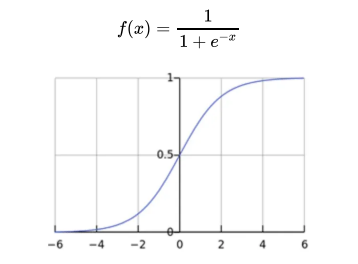
Sigmoid 激活函数:
-
公式:
![image]()
-
特点:Sigmoid函数将输入$x$映射到0到1之间的值,用于二元分类问题。它具有平滑的S形曲线。
-
优点:输出范围有界,可用于产生概率估计。
-
缺点:容易出现梯度消失问题,特别是在深层神经网络中。
-
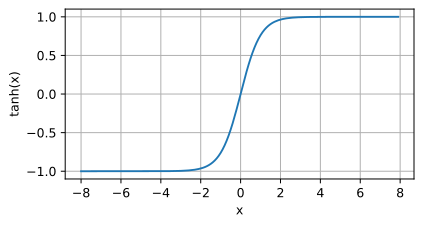
与sigmoid函数类似,tanh函数也能将其输入压缩转换到区间(-1,1)上,tanh函数的公式如下:
![image]()
![image]()
- 这个tanh函数⼜被称作双曲正切函数,可以看出它的函数范围是(-1,1)⽽均值为0,解决了上⾯sigmoid的⼀个问题。但是不难发现,该函数依旧没有解决梯度消失的问题。
-
-
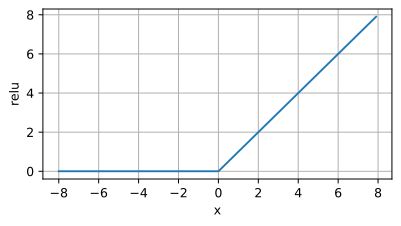
ReLU 激活函数(Rectified Linear Unit):
-
公式:
![image]()
![image]()
-
特点:ReLU在$x$为正数时输出与输入相等,为负数时输出为零。
-
优点:计算简单,有效地克服了梯度消失问题,在深度学习中常用。
-
缺点:可能导致神经元死亡问题,即一些神经元在训练中永远不会激活。
-
-
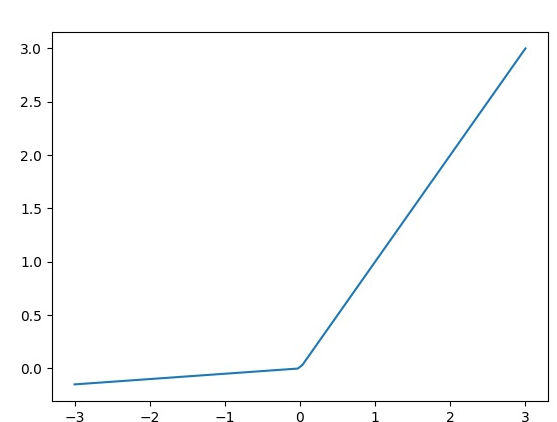
Leaky ReLU 激活函数:
- 公式:
![image]()
![image]()
- 特点:Leaky ReLU是ReLU的改进版本,允许小于零的值具有小斜率$\alpha$,通常为0.01。
- 优点:解决了ReLU的神经元死亡问题。
- 缺点:仍然可能存在梯度消失问题。
- 公式:
-
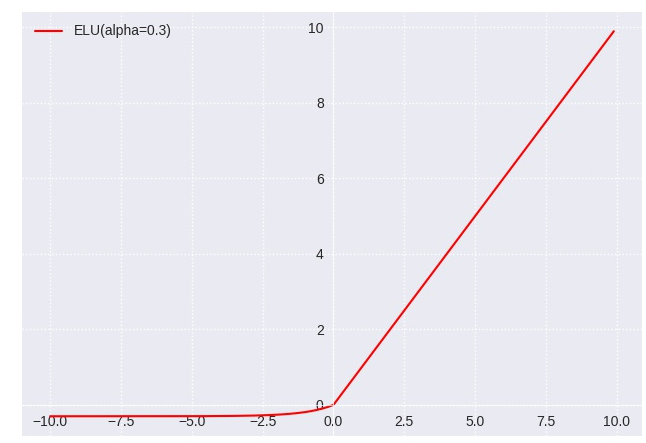
ELU 激活函数(Exponential Linear Unit):
-
公式:
![image]()
![image]()
-
特点:ELU是一种具有非线性特性的激活函数,在小于零的范围内具有平滑的斜率。
-
优点:解决了神经元死亡问题,有助于快速训练。
-
缺点:相对计算成本较高。
-
-
Swish 激活函数:
- 公式:
![image]()
![image]()
- 特点:Swish是一种结合了Sigmoid和ReLU特点的激活函数,通常在一些任务中表现良好。
- 优点:非线性特性,对于某些问题具有更好的性能。
- 缺点:较新,可能不适用于所有情况。
![image]()
- 公式:
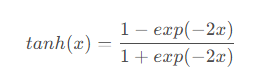
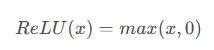
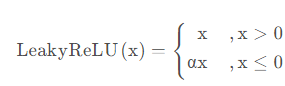
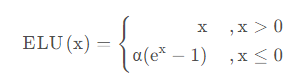
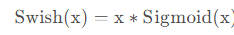
每个激活函数都有其独特的数学表达式和特点,理解这些特点有助于选择合适的激活函数以及了解它们在神经网络中的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号