BN的可训练参数,BN批归一化操作
批归一化(Batch Normalization,简称BN)是一种深度学习中常用的正则化技术,它有一些可训练的参数,包括:
- 缩放参数(Scale): 通常用γ表示,它用来调整每个特征的标准差,从而控制特征的缩放。
- 偏移参数(Shift): 通常用β表示,它用来调整每个特征的平均值,从而控制特征的平移。
- 这两个参数是可训练的,它们允许模型根据数据的分布来动态地调整每个特征的缩放和平移,以提高网络的表现能力
批归一化(Batch Normalization,简称BN)的操作可以通过以下公式来解释:
- 假设我们有一个包含 m 个样本的 mini-batch,每个样本有 n 个特征。首先,我们计算该 mini-batch 中每个特征的均值(mean)和方差(variance):
-
均值计算:
对于第 j 个特征,我们计算其均值 μ_j 如下:
![]()
其中,x_ij 表示 mini-batch 中第 i 个样本的第 j 个特征。
-
方差计算:
对于第 j 个特征,我们计算其方差 σ_j^2 如下:
![]()
其中,x_ij 表示 mini-batch 中第 i 个样本的第 j 个特征。
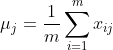
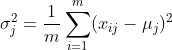
然后,我们使用这些均值和方差来进行归一化操作:
-
归一化:
对于 mini-batch 中的每个样本的第 j 个特征,我们使用均值和方差来进行归一化,得到归一化后的特征值 z_ij 如下:
![]()
其中,ε 是一个小的常数,用于防止方差为零的情况。
-
重缩放和平移:
最后,我们使用可训练的缩放参数(γ)和偏移参数(β)来重新缩放和平移归一化后的特征:
![]()
其中,y_ij 是最终的输出特征,γ_j 是可训练的缩放参数,β_j 是可训练的偏移参数。
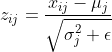
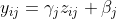
这个过程对于 mini-batch 中的每个特征都会执行一次,这样就完成了批归一化操作。这些可训练的参数(γ 和 β)允许模型根据数据的分布来动态地调整特征的缩放和平移,从而提高网络的训练效果和泛化性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号