第一次个人编程作业
1.GitHub
[github仓库]:
2.PSP表格
| PSP2.1 | personal software process stages | 预计耗时(min) | 实际耗时(min) |
|---|---|---|---|
| planing | 计划 | 90 | 120 |
| estimate | 估计这个任务需要多少时间 | 120 | 120 |
| development | 开发 | 600 | 900 |
| analysis | 需求分析 | 30 | 30 |
| design spec | 生成设计文档 | 30 | 50 |
| design review | 设计复审 | 30 | 50 |
| coding standard | 代码规范(为目前的开发制定合适的规范) | 30 | 20 |
| design | 具体设计 | 60 | 90 |
| coding | 具体编码 | 300 | 480 |
| code review | 代码复审 | 60 | 50 |
| test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| reporting | 报告 | 100 | 80 |
| test report | 测试报告 | 100 | 100 |
| size measurement | 计算工作量 | 60 | 60 |
| postmortem&process improvement plan | 事后总结,并提出过程改进计划 | 60 | 60 |
| 合计 | 1790 | 2360 |
3.计算模块接口的设计与实现过程
本次实验主要思想是依靠正则表达式,将读入信息中需要的部分按照要求提取出来;实现是面向过程的,并不是面向对象的,并没有设置任何函数。
整体思路:
先将手机号码提取出来,再利用','分别将姓名和地址提取出来,然后再对地址部分处理,按顺序提出。
对于难度三的题,先按照难度二的处理,再调用高德地图的API补全前面四级的信息。
先是各种正则表达式,用于从字符串中提取需要的内容
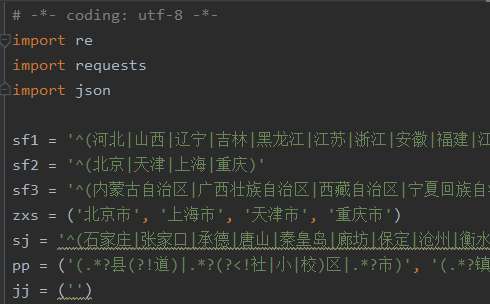
略去提取手机和姓名的部分,直接进入地址部分:
因为省份中有直辖市,且直辖市会少一个地级市,所以要对省份和市级特判
loc = line[1]loc_list = [] # 地址列表
p = 0 # p控制开始匹配地址
flag = re.match(sf1, loc[p:]) # 匹配普通省份
if flag:
p = p+flag.end()
loc_list.append(flag.group(1) + '省')
if loc[p] == '省':
p = p + 1
else:
flag = re.match(sf2, loc[p:]) # 匹配直辖市
if flag:
loc_list.append(flag.group(1))
else:
flag = re.match(sf3, loc[p:])
if flag:
p = p + flag.end()
loc_list.append(flag.group(1)) # 匹配自治区
else:
loc_list.append('')
flag = re.search(sj, loc[p:]) # 匹配地级市
接下来就是对市级以下的地址提取,由于操作其实是重复的,索性就写了一个循环,前面判断了一下难度
n = 4
if num == '1':
n = 2for i in range(n): # 后续匹配
flag = re.match(pp[i], loc[p:])
if flag:
p = p + flag.end()
loc_list.append(flag.group(0))
else:
loc_list.append('')
loc_list.append(loc[p:])
最后就是对3级难度的处理,先是调用高德的API,获取地址的经纬度,然后在获取地址的详细信息,再将其中填到对应的地方
if num=='3':
url = 'https://restapi.amap.com/v3/geocode/geo?address=' + loc + '&output=XML&key=55102a2c4b79bf8c87cab849177e086a'
al = requests.get(url).text
al = re.search('\d+.?\d+,\d+.?\d+', al).group()
url = 'https://restapi.amap.com/v3/geocode/regeo?output=xml&location=' + al + '&key=55102a2c4b79bf8c87cab849177e086a&radius=1000&extensions=base'
al = requests.get(url).text
al = re.search('<province>(.*?)</province>.*?<city>(.*?)</city>.*?<district>(.*?)</district>.*?<township>(.*?)</township>', al)
if loc_list[0] == '':
if al.group(1) in zxs:
loc_list[0] = al.group(1)[:2]
loc_list[1] = al.group(1)
else:
loc_list[0] = al.group(1)
if loc_list[1] == '':
loc_list[1] = al.group(2)
if loc_list[2] == '':
loc_list[2] = al.group(3)
if loc_list[3] == '':
loc_list[3] = al.group(4)
4.性能分析:
Timer unit: 1e-07 s
Total time: 3.30956 s
File: C:/Users/chenminglei/PycharmProjects/location/111.py
Function: main at line 7
Line # Hits Time Per Hit % Time Line Contents
7 def main():
8 1 32.0 32.0 0.0 sf1 = '^(略)'
9 1 10.0 10.0 0.0 sf2 = '^(略)'
10 1 7.0 7.0 0.0 sf3 = '^(略)'
11 1 7.0 7.0 0.0 zxs = (略)
12 1 7.0 7.0 0.0 sj = '^(略)'
13 1 7.0 7.0 0.0 pp = (略)
14 1 7.0 7.0 0.0 jj = ('')
15 1 32852193.0 32852193.0 99.3 line = input()
16 1 28.0 28.0 0.0 num = line[:1]
17 1 28.0 28.0 0.0 line = line[2:].strip('.|\n')
18 1 5941.0 5941.0 0.0 tel = re.search(r'(\d){11}', line).group()
19 1 48.0 48.0 0.0 line = line.replace(tel, '')
20 1 1067.0 1067.0 0.0 line = re.split(',', line)
21 1 11.0 11.0 0.0 loc = line[1]
22 1 7.0 7.0 0.0 loc_list = [] # 地址列表
23 1 7.0 7.0 0.0 p = 0 # p控制开始匹配地址
24 1 19138.0 19138.0 0.1 flag = re.match(sf1, loc[p:]) # 匹配普通省份
25 1 22.0 22.0 0.0 if flag:
26 1 22.0 22.0 0.0 p = p+flag.end()
27 1 33.0 33.0 0.0 loc_list.append(flag.group(1) + '省')
28 1 19.0 19.0 0.0 if loc[p] == '省':
29 1 13.0 13.0 0.0 p = p + 1
30 else:
31 flag = re.match(sf2, loc[p:]) # 匹配直辖市
32 if flag:
33 loc_list.append(flag.group(1))
34 else:
35 flag = re.match(sf3, loc[p:])
36 if flag:
37 p = p + flag.end()
38 loc_list.append(flag.group(1)) # 匹配自治区
39 else:
40 loc_list.append('')
41 1 197824.0 197824.0 0.6 flag = re.search(sj, loc[p:]) # 匹配地级市
42 1 15.0 15.0 0.0 if flag:
43 1 15.0 15.0 0.0 p = p + flag.end()
44 1 25.0 25.0 0.0 loc_list.append(flag.group(0) + '市')
45 1 12.0 12.0 0.0 if loc[p] == '市':
46 1 8.0 8.0 0.0 p = p + 1
47 else:
48 loc_list.append('')
49 1 7.0 7.0 0.0 n = 4
50 1 8.0 8.0 0.0 if num == '1':
51 1 7.0 7.0 0.0 n = 2
52 3 37.0 12.3 0.0 for i in range(n): # 后续匹配
53 2 18155.0 9077.5 0.1 flag = re.match(pp[i], loc[p:])
54 2 26.0 13.0 0.0 if flag:
55 2 21.0 10.5 0.0 p = p + flag.end()
56 2 33.0 16.5 0.0 loc_list.append(flag.group(0))
57 else:
58 loc_list.append('')
59 1 14.0 14.0 0.0 loc_list.append(loc[p:])
60 1 9.0 9.0 0.0 if num=='3':
61 url = 略
62 al = requests.get(url).text
63 al = re.search('\d+.?\d+,\d+.?\d+', al).group()
64 url = 略
65 al = requests.get(url).text
66 al = re.search('<province>(.*?)</province>.*?<city>(.*?)</city>.*?<district>(.*?)</district>.*?<township>(.*?)</township>', al)
67 if loc_list[0] == '':
68 if al.group(1) in zxs:
69 loc_list[0] = al.group(1)[:2]
70 loc_list[1] = al.group(1)
71 else:
72 loc_list[0] = al.group(1)
73 if loc_list[1] == '':
74 loc_list[1] = al.group(2)
75 if loc_list[2] == '':
76 loc_list[2] = al.group(3)
77 if loc_list[3] == '':
78 loc_list[3] = al.group(4)
79 1 13.0 13.0 0.0 information = {'姓名': line[0], '手机': tel, '地址': loc_list}
80 1 673.0 673.0 0.0 print(json.dumps(information, ensure_ascii=False))
5.测试结果:
输入:
1!冯昔唉,安徽省合肥市庐江县郭河镇G3京台高18835354291速合肥市庐江县广寒桥街道.
2!季宋,湖北咸宁市崇阳县肖岭乡下隽街中共肖岭村支15164791535部委员会.
3!孙旗乖,13366755810白城市洮北区长庆南街65号.
输出:
{"姓名": "冯昔唉", "手机": "18835354291", "地址": ["安徽省", "合肥市", "庐江县", "郭河镇", "G3京台高速合肥市庐江县广寒桥街道"]}
{"姓名": "季宋", "手机": "15164791535", "地址": ["湖北省", "咸宁市", "崇阳县", "肖岭乡", "下隽街", "", "中共肖岭村支部委员会"]}
6.计算模块错误分析:
还有很多种情况没有考虑进去,所以错误还是有很多的
就比如上面正则都是同时判断的,会出现在后面的可能会比在前面的晚匹配的,导致结果的错误
找不到样例(吐血),但这个错误还是存在的
7.实验总结:
这次实验虽然是面向百度的编程,但收获还是不浅的。之前学过一段时间python,由于没法实践,忘得差不多了,靠这次实验捡回了一点,对正则表达式有了初步的掌握。就酱。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号