
字符编码
python 字符编码与转码
注意:unicode和utf-8之间不需要转换,可以直接互相打印,GBK如果需要和utf-8之间进行转换一定要通过unicode
pycharm的默认编码如果不指定则会取系统的编码集,windows是默认gbk的
转换编码只在2进制文件解码编码中必须指定,如果文本文件指定encoding则会报错

s="你好"#python 默认的编码为unicode因此,所有的字符串的编码均为unicode print(s.encode("gbk"))#编码后,字符串的数据类型转变为2进制,打印的结果就是二进制的编码print(s.encode("gbk")) print(s.encode("utf-8")) print(s.encode("utf-8").decode("utf-8").encode("gb2312"))#把utf-8编码先解码为unicode(写utf-8表示原编码为utf-8),然后重新编码为gb2312 输出: b'\xc4\xe3\xba\xc3' b'\xe4\xbd\xa0\xe5\xa5\xbd' b'\xc4\xe3\xba\xc3'
http://www.cnblogs.com/luotianshuai/articles/5735051.html
在2.7环境中咱们要写上这一行#-*- coding:utf-8 -*- 为什么我们要加这一行呢?这一样的意思是置顶编码类型为utf-8编码!
首先在看这个问题之前,咱们是否曾想过一个问题?
为什么我们可以在显示器上能看到这些文字、数字、图片、字符、等等信息呢?大家都知道计算机本身只能识别 0 1 的组合,他们是怎么展示这些内容的呢?我们怎么和计算机去沟通呢?
如果我们使用0 1 的组合和计算机沟通你还能看到这些内容吗?还有一个问题就是01的组合对于咱们说几乎看不懂对吧!
那怎么办?如何让计算机理解我们的语言,并且我们能理解计算机的语言呢?
举个比较形象的例子,中英文词典对照表,这样我们就可以把中英文进行互相的翻译了呢?对不对!同理计算机也是这样的他需要一个标准的对照关系,那么这个标准最早叫什么呢?ASCII表
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
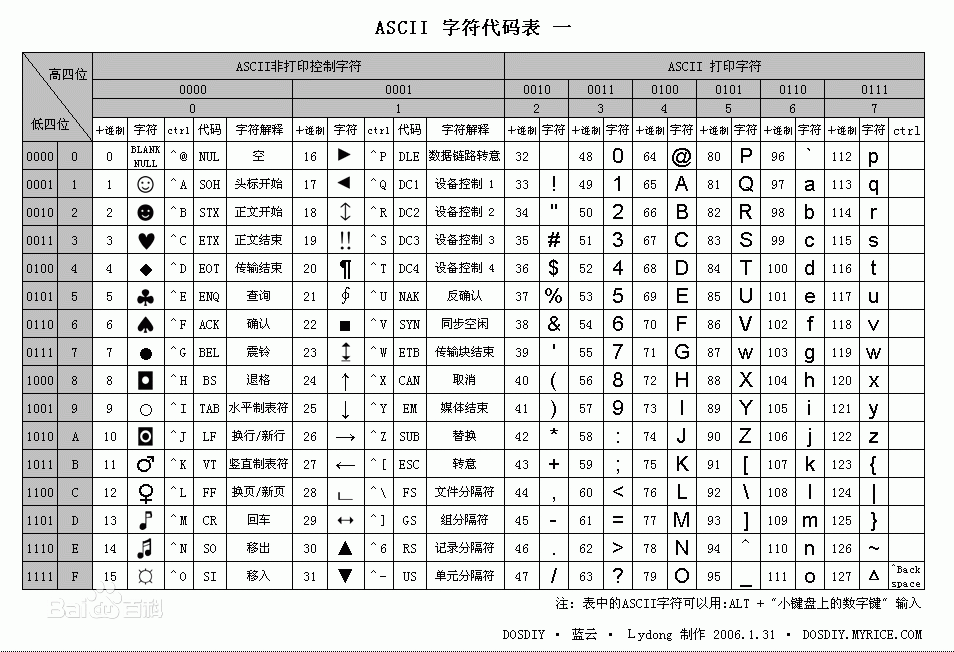
咱们看下这张表:
有特殊符号、大写字母、小写字母、数字(这里注意下0~9的数字是字符),在这些字符左边都有一个10进制的数字。但是对于10进制来说计算机他也是不能理解的,因为他只能理解0 1 ,但是10进制和2进制的转换就非常容易了!
点击我之前写过的一篇文章来查看:十进制&二进制转换
举例来说:如果我在键盘上按一个A字母的时候那么实际是给计算机传输了一个数字65,通过这样的机制和计算机沟通,有了这个ASCII码表就可以和任何计算机进行沟通了。NICE
这里在看个知识点:计算机中最小的单位是什么?bit bit就咱们常说一位二进制,一位二进制要么是0 要么是 1
但是bit这个单位太小了,我们用字节(byte)来表示。他们是有换算的规则的(看下面的规则我想大家都不是很陌生对吧):
8b = 1B #小b=bit ; 大B=byte 1024B = 1KB 1024KB = 1M 1024M = 1G 1024G = 1T '''
在存储英文的时候我们至少需要1个字节(一个字母),就是8位(bit),看下ASCII表中1个字节就可以表示所有的英文所需要的字符,是不非常高效!
为什么呢?早期的计算机的空间是非常宝贵的!
那你会发现1个字节8位,他能存储的最大数据是2的8次方-1 = 255,一个字节最多能表示255个字符 那西方国家他们使用了127个字符,那么剩下字符是做什么的呢?就是用来做扩展的,西方人考虑到还有其他国家。所以留下了扩展位。
但是呢有问题,计算机是西方人发明的,如果仅仅支持英文的话,这127个字符完全就可以表示所有英文中能用的的内容了。但是他没有考虑咱们大中国啊!ASCII到了中国之后发现:咱们中国最常用的中文都有6000多个完全不够用啊!
但是怎们办?中国人非常聪明:就在原有的扩展位中,扩展出自己的gbk、gb2312、gb2318字符编码。
他是怎么扩展的呢?比如说在ASCII码中的128这个位置,这个位置又指定一张单独表,聪明吧! 其他国家也是这样设计的!
中国东亚大国是吧,我们国家比较NB,我要兼容其他国家的常用的编码!比如韩国日本,因为韩国和日本人家都有自己的编码,人家根本就不鸟你,举个例子来说,比如韩国的游戏,在中国下载安装之后会出现乱码的情况?什么鬼?
这种乱码的出现基本上就两种情况:
1、字符编码没有
2、字符编码冲突了,人家在写这个程序的时候指定的字符集和咱们使用的字符集的位置不对。 0 0 !
你想想不光是亚洲国家这样,欧洲国家,非洲国家都会存在这个问题,基于这个乱象国际互联网组织就说你们各个国家都别搞了,我们给你们搞一个统一的,这个统一的是什么呢Unicode“万国编码”,
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,
规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536, 注:此处说的的是最少2个字节,可能更多。
这里还有个问题:使用的字节增加了,那么造成的直接影响就是使用的空间就直接翻倍了!举例还说:同样是ABCD这些字符存储一篇相同的文章,使用ASCII码如果是1M的话,那么Unicode存储至少2M可能还会更多。
为了解决个问题就出现了:UTF-8编码
UTF-8编码:是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
通过这种可扩展的方式来存储。
OK 上面了解了:
1、什么ASCII编码
2、什么Unicode编码
3、什么UTF-8编码
回顾下乱码的出现原因:1、没有字符集 2、字符集冲突
回过头来看下为什么需要在第二行加上指定编码呢?在2.x版本的Python中Pyton在解释.py文件的时候,默认是给他一个编码的就是ASCII码,so如果在2.7版本中如果你不指定编码并且在.py文件中写了一个ASCII码中没有的字符就会显示乱码 0 0 !
不过这个问题在Python3中就不存在了,因为在Python3中默认就是Unicode编码。。。。。
Python编码转换
有一个问题,既然有统一的Unicode编码了,为毛还需要编码转换?大家都统一一个编码不就可以了吗?
1、
不要问我为什么,我问你们个问题,如果世界上出了一种世界语言,你会放弃中文吗?去使用这个世界通用语言吗?这就是个坑,是个遗留问题。
但是虽然以后可能世界语言会慢慢替代咱们常用的语言,大家以后沟通就使用世界语言就不会有沟通障碍了对吧。(就是举个例子)
2、
还有一个情况是什么呢?韩国的游戏到中国来之后,是乱码?结合上一个回答咱们可以猜出:编写这个游戏的人在编写游戏的时候可能根本就没有考虑出口其他国家。那如果没有这个Unicode编码的话,到咱们这里来显示肯定是乱码是吧。
那就得需要通过转码把他们编码集,转换为Unicode(utf-8)编码集。这样他们就可以正常显示韩文了!(这里只是转编码集并不是翻译成中文不要弄混了~~!)
一、Python3中的编码转换
#因为在Python3中默认就是unicode编码
#!/usr/bin/env python #-*- coding:utf-8 -*- #author luotianshuai tim = '天帅' #转为UTF-8编码 print(tim.encode('UTF-8')) #转为GBK编码 print(tim.encode('GBK')) #转为ASCII编码(报错为什么?因为ASCII码表中没有‘天帅’这个字符集~~) print(tim.encode('ASCII'))
二、Python2.X中的编码转换
#因为在python2.X中默认是ASCII编码,你在文件中指定编码为UTF-8,但是UTF-8如果你想转GBK的话是不能直接转的,的需要Unicode做一个转接站点。
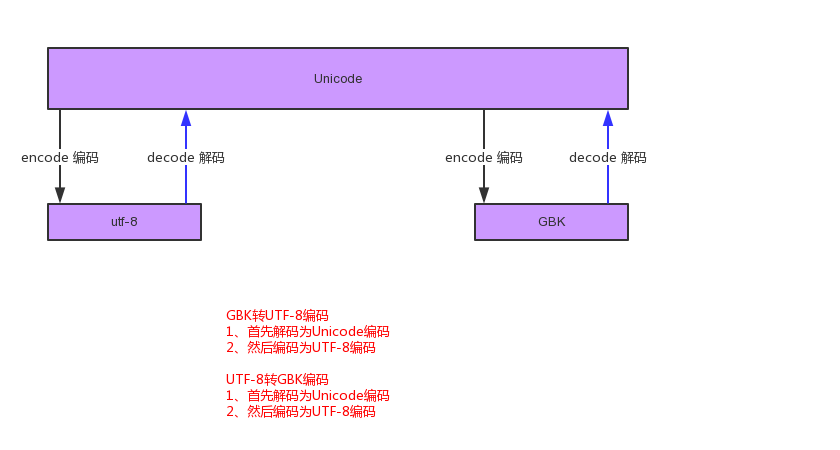
#!/usr/bin/env python #-*- coding:utf-8 -*- #author luotianshuai import chardet tim = '你好' print chardet.detect(tim) #先解码为Unicode编码,然后在从Unicode编码为GBK new_tim = tim.decode('UTF-8').encode('GBK') print chardet.detect(new_tim) #结果 ''' {'confidence': 0.75249999999999995, 'encoding': 'utf-8'} {'confidence': 0.35982121203616341, 'encoding': 'TIS-620'} '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号