数据结构与算法学习笔记之后进先出的“桶”
前言
栈最为一种的常用的数据结构,用“桶”来形容最合适不过;今天我们就来学习一下
正文
一、栈的定义?
1.“后进先出,先进后出”的数据结构。
2.从操作特性来看,是一种“操作受限”的线性表,只可以在一端插入和删除数据。
二、为什么需要栈?
1.任何数据结构都是对特定应用场景的抽象,栈是一种操作受限的数据结构,其操作特性用数组和链表均可实现,但却暴露太多的操作接口,使用时容易出错;
2.当某个数据集合只涉及在一端插入和删除数据,且满足后进者先出,先进者后出的操作特性时,我们应该首选栈这种数据结构
三、如何实现栈?
栈可以用数组,链表来实现
1.以数组为例
空间复杂度为O(1)
时间复杂度大多数为O(1),特殊情况自动扩容拷贝原数组时为O(n);
均摊时间复杂度接近于O(1);

// 基于数组实现的顺序栈
public class ArrayStack {
private String[] items; // 数组
private int count; // 栈中元素个数
private int n; // 栈的大小
// 初始化数组,申请一个大小为 n 的数组空间
public ArrayStack(int n) {
this.items = new String[n];
this.n = n;
this.count = 0;
}
// 入栈操作
public boolean push(String item) {
// 数组空间不够了,直接返回 false,入栈失败。
if (count == n) return false;
// 将 item 放到下标为 count 的位置,并且 count 加一
items[count] = item;
++count;
return true;
}
// 出栈操作
public String pop() {
// 栈为空,则直接返回 null
if (count == 0) return null;
// 返回下标为 count-1 的数组元素,并且栈中元素个数 count 减一
String tmp = items[count-1];
--count;
return tmp;
}
}
(代码来自于网络,如有侵权请告知我删除)
2.以链表为例(网上找的)
空间复杂度为O(1)
时间复杂度大多数为O(1)
public class StackOfLinked<Item> implements Iterable<Item> { //定义一个内部类,就可以直接使用类型参数 private class Node{ Item item; Node next; } private Node first; private int N; //构造器 public StackOfLinked(){} //添加 public void push(Item item){ Node oldfirst = first; first = new Node(); first.item = item; first.next = oldfirst; N++; } //删除 public Item pop(){ Item item = first.item; first = first.next; N--; return item; } //是否为空 public boolean isEmpty(){ return N == 0; } //元素数量 public int size(){ return N; } //返回栈中最近添加的元素而不删除它 public Item peek(){ return first.item; } @Override public Iterator<Item> iterator() { return new LinkedIterator(); } //内部类:迭代器 class LinkedIterator implements Iterator{ int i = N; Node t = first; @Override public boolean hasNext() { return i > 0; } @Override public Item next() { Item item = (Item) t.item; t = t.next; i--; return item; } } }
(代码来自于网络,如有侵权请告知我删除)
四、栈的应用
1.函数调用中的应用
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构,用来存储函数调用时的临时变量。每进入一个函数,就会将其中的临时变量作为栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
2.在表达式求值中的应用(比如:34+13*9+44-12/3)
利用两个栈,一个用来保存操作数,一个用来保存运算符。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较,若比运算符栈顶元素优先级高,就将当前运算符压入栈,若比运算符栈顶元素的优先级低或者相同,从运算符栈中取出栈顶运算符,从操作数栈顶取出2个操作数,然后进行计算,把计算完的结果压入操作数栈,继续比较。
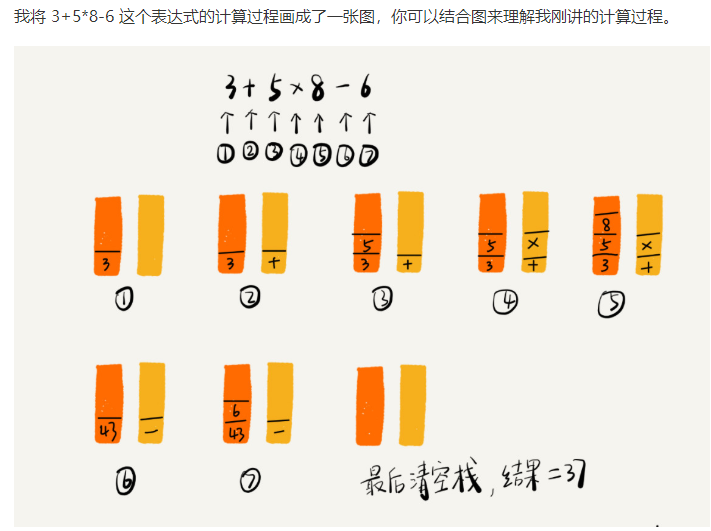
(图片来自于王争)
3.栈在括号匹配中的应用(比如:{}{[()]()})
用栈保存为匹配的左括号,从左到右一次扫描字符串,当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号,如果能匹配上,则继续扫描剩下的字符串。如果扫描过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明未匹配的左括号为非法格式。
4.如何实现浏览器的前进后退功能?
我们使用两个栈X和Y,我们把首次浏览的页面依次压如栈X,当点击后退按钮时,再依次从栈X中出栈,并将出栈的数据一次放入Y栈。当点击前进按钮时,我们依次从栈Y中取出数据,放入栈X中。当栈X中没有数据时,说明没有页面可以继续后退浏览了。当Y栈没有数据,那就说明没有页面可以点击前进浏览了。
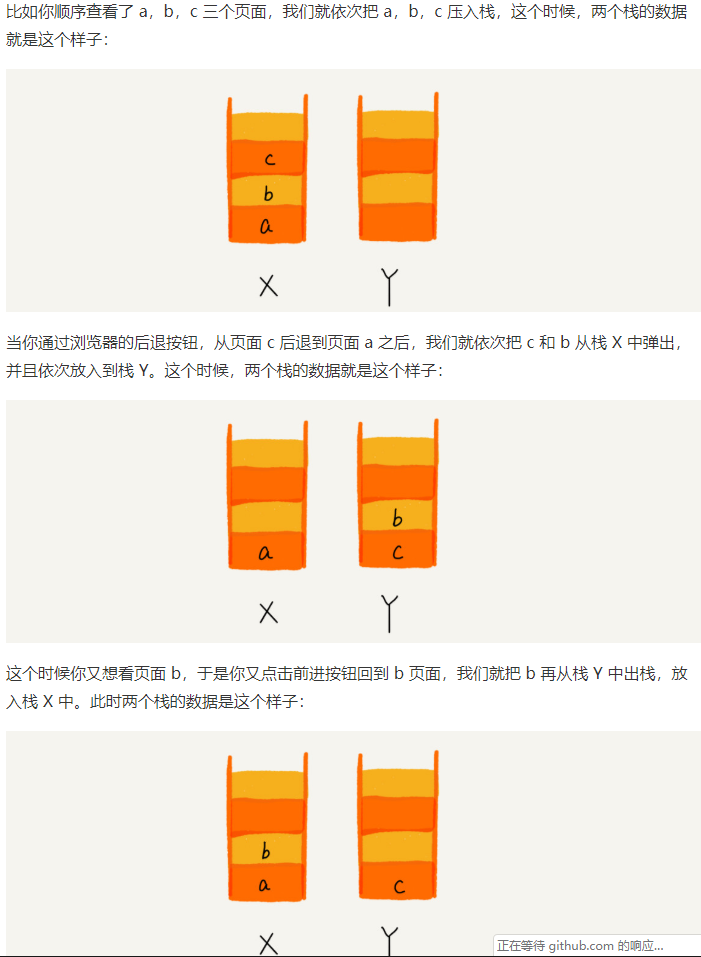
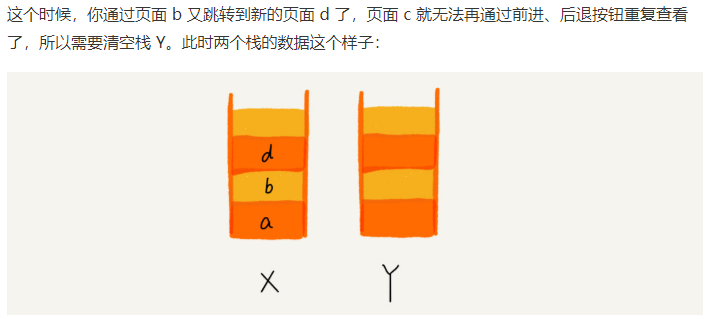
(图片来自于王争)
五、两个问题
1. 我们在讲栈的应用时,讲到用函数调用栈来保存临时变量,为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
答:因为函数调用的执行顺序符合后进者先出,先进者后出的特点。
函数调用中经常嵌套,栗子:A调用B,B又调用C,那么就需要先把C执行完,结果赋值给B中的临时变量,B的执行结果再赋值给A的临时变量,嵌套越深的函数越需要被先执行,这样刚好符合栈的特点,因此每次遇到函数调用,只需要压栈,最后依次从栈顶弹出依次执行即可,根据数据结构是特定应用场景的抽象的原则,我们优先考虑栈结构。
2.我们都知道,JVM 内存管理中有个“堆栈”的概念。栈内存用来存储局部变量和方法调用,堆内存用来存储 Java 中的对象。那 JVM 里面的“栈”跟我们这里说的“栈”是不是一回事呢?如果不是,那它为什么又叫作“栈”呢?
答:内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。
内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。
代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。
静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。
栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。
相关文章
数据结构与算法学习笔记之写链表代码的正确姿势(下)
数据结构与算法学习笔记之 提高读取性能的链表(上)
数据结构与算法学习笔记之 从0编号的数组
以上内容为个人的学习笔记,仅作为学习交流之用。

欢迎大家关注公众号,不定时干货,只做有价值的输出
作者:Dawnzhang
出处:https://www.cnblogs.com/clwydjgs/p/9792256.html
版权:本文版权归作者
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述