数据结构之——跳表说明及实现
肯取势者可为人先,能谋势者必有所成
跳表说明
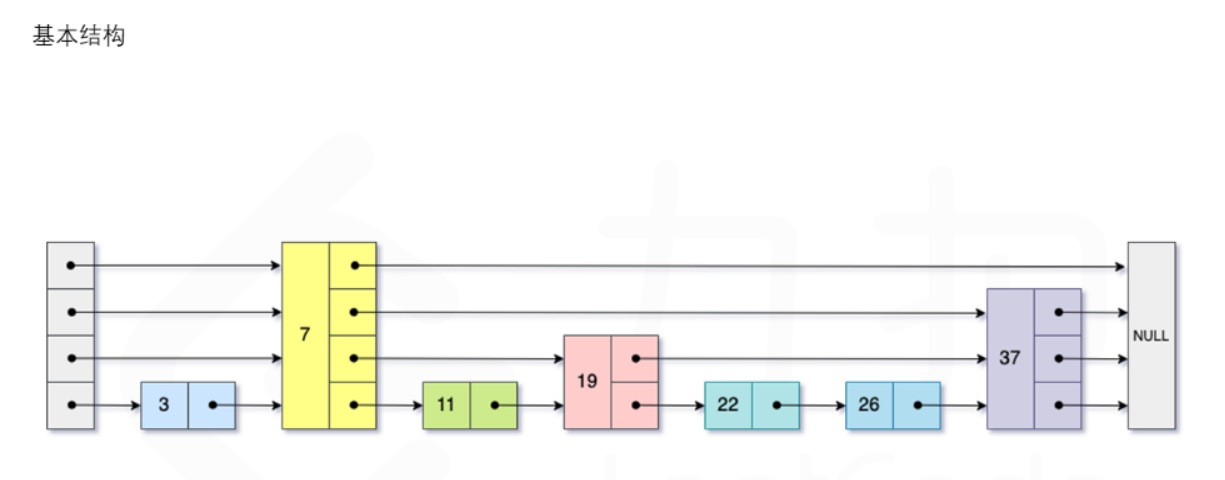
1.跳表是一种随机化的数据结构,可以被看做二叉树的一个变种,它在性能上和红黑树、AVL 树不相上下,但是跳表的原理非常简单,目前在 Redis 和 LevelDB 中都有用到。
2.跳表的期望空间复杂度为 O(n),跳表的查询,插入和删除操作的期望时间复杂度均为O(logn)。跳表实际为一种多层的有序链表,跳表的每一层都为一个有序链表,且满足每个位于第 i层的节点有 p 的概率出现在第 i+1层,其中 p 为常数。
3.跳表的查找、插入和删除操作可看:https://leetcode.cn/problems/design-skiplist/solution/she-ji-tiao-biao-by-leetcode-solution-e8yh/
要点说明
1.跳表的每一个节点都有设置的level<=MAX_LEVEL长度的数组(forward)用于存储该节点各层指向的下一个节点(向右的),每一个节点的层数由随机化概率判定
2.跳表的层数是随着数据的插入逐渐增加的(向上创建节点),最大为MAX_LEVEL,是否增加由随机化的概率判定,P_FACTOR一般设置为0.25,小于P_FACTOR才会向上创建节点,避免层数添加过快过多(下面的实现中,只做了一次判断,即确认创建节点所到的最高层,并设置插入节点的层数)也正因为这个,跳表实际运用中的索引是比较“乱”的,不会完全向下层逐层二分(理想状态)。
3.跳表在插入数据时,需要记录每一次的向下节点(实际为了方便操作,记录的是向下节点的前一个节点,因为链表的前一个节点能让我们很方便地处理下一个和下下个节点),最底层必然是要建立插入节点的,然后依次向上层创建节点(根据P_FACTOR判断创建与否)
4.删除的时候,要确保待删除节点在各层都被删除掉
5.要维护level的变化,插入数时,level可能变大,删除数据时,level可能变小
跳表实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date: 2022/7/27
import random
MAX_LEVEL = 32
P_FACTOR = 0.25
def random_level() -> int:
lv = 1
while lv < MAX_LEVEL and random.random() < P_FACTOR:
lv += 1
return lv
class SkiplistNode:
__slots__ = 'val', 'forward'
def __init__(self, val: int, max_level=MAX_LEVEL):
self.val = val
self.forward = [None] * max_level
class Skiplist:
def __init__(self):
self.head = SkiplistNode(-1)
self.level = 0
def search(self, target: int) -> bool:
curr = self.head
for i in range(self.level - 1, -1, -1):
# 找到第 i 层小于且最接近 target 的元素
while curr.forward[i] and curr.forward[i].val < target:
curr = curr.forward[i]
curr = curr.forward[0]
# 检测当前元素的值是否等于 target
return curr is not None and curr.val == target
def add(self, num: int) -> None:
update = [self.head] * MAX_LEVEL
curr = self.head
for i in range(self.level - 1, -1, -1):
# 找到第 i 层小于且最接近 num 的元素
while curr.forward[i] and curr.forward[i].val < num:
curr = curr.forward[i]
update[i] = curr
# 随机获取创建节点的最大层数
lv = random_level()
self.level = max(self.level, lv)
new_node = SkiplistNode(num, lv)
for i in range(lv):
# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点
new_node.forward[i] = update[i].forward[i]
update[i].forward[i] = new_node
def erase(self, num: int) -> bool:
update = [None] * MAX_LEVEL
curr = self.head
for i in range(self.level - 1, -1, -1):
# 找到第 i 层小于且最接近 num 的元素
while curr.forward[i] and curr.forward[i].val < num:
curr = curr.forward[i]
update[i] = curr
# 获取待删除节点
curr = curr.forward[0]
if curr is None or curr.val != num: # 值不存在
return False
for i in range(self.level):
# 如果不等于,说明低层的等于num,从当前层开始不会再有等于num的,因为跳表每次向下,下一层的可能向下节点只可能大于等于上一层的节点
if update[i].forward[i] != curr:
break
# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳
update[i].forward[i] = curr.forward[i]
# 更新当前的 level 从上往下进行更新,头节点右节点没有说明该层没有其他节点,故直接level-1
while self.level > 1 and self.head.forward[self.level - 1] is None:
self.level -= 1
return True
参考
1.Skip Lists: A Probabilistic Alternative to Balanced Trees
2.设计跳表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号