DjangoRestFramework使用总结
你要去相信,没有到不了的明天。
摘要
本文主要描述DjangoRestFramework的相关内容,额外提及部分涉及到的其他知识。
简介
1.Django REST framework 框架是一个用于构建Web API的强大而又灵活的工具。通常简称为DRF框架 或 REST framework,DRF框架是建立在Django框架基础之上的。那为何要使用DjangoRestFramework,每个项目都需要做基础构架,这个时候需要考虑跟多的事情,包括
- 统一的异常处理
- 统一的查询过滤
- 权限校验方案
- 认证方式
- 代码分层
- 前后端数据格式规范
- 其他...
这时候,使用RestFramework能让我们快速并较好地完成这部分工作,进而进行其他事项的工。同样,在编码阶段,也能让我们的编码效率得到进一步提升。如:对于一个简单表的增、删、改、查,完全不需要我们自己去编码。
总而言之,使用RestFramework能进一步提升工作的效率,减少重复造轮子。
2.特点:
- 提供认证、权限、限流、版本、序列化、视图、解析器、分页、路由、渲染十大组件;
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化,且可以自定义添加字段,便于构造需要的数据格式;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 多种身份认证和权限认证方式的支持;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,可根据需要采用相应的方式;
- 提供直观方便的 API web 界面;
- 可扩展性,插件丰富;
3.环境安装与配置:
pip install djangorestframework #安装
其他配合使用的包和版本:
python3.6+
Django==2.2.13
django-filter==2.3.0
django-redis==4.12.1
djangorestframework==3.11.1
DRF是以Django扩展应用的方式提供的,所以可以直接利用已有的Django环境而无需重新创建。(若没有Django环境,需要先创建环境安装Django)
在django配置文件settings.py(以具体项目为准)的INSTALLED_APPS中添加'rest_framework'。
INSTALLED_APPS = [ ... 'rest_framework',]
即可开始使用。
Django中的 FBV和CBV
Django有两种视图,分别为:
- FBV (function base view):基于函数的视图
- CBV(class base view):基于类的视图
其中,FBV 是比较常见的,就是使用了函数来处理用户的请求;而 CBV是使用了类来处理用户的请求,是基于反射实现根据请求方式的不同,执行不同的方法。
原理:url -> view方法 -> dispatch方法(反射执行其他请求方式:GET/POST/PUT/DELETE)
更多解释:
认证
1.使用默认认证方案:
可以在配置文件中配置全局默认的认证方案
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.BasicAuthentication', # 基本表单认证
'rest_framework.authentication.SessionAuthentication', # session认证
)
}
也可以在视图中通过设置authentication_classess属性来设置
from rest_framework.authentication import SessionAuthentication, BasicAuthentication
from rest_framework.views import APIView
class ExampleView(APIView):
authentication_classes = (SessionAuthentication, BasicAuthentication)
...
认证失败会有两种可能的返回值:
- 401 Unauthorized 未认证
- 403 Permission Denied 权限被禁止
2.RestFramework认证流程:
view中获取请求(request)-> dispatch函数进行反射 -> response, 其中,dispatch中有如下过程:
- 对原生request进行进一步封装(initialize_request函数,添加了parsers,authenticators,content_negotiator,parser_context(原生request解析后的内容))
- 封装后返回的为Request对象,若想访问其属性,如原生request,可查看Request对象属性,即self._request
- 然后根据封装后的request进行相应的验证(initial函数),包括perform_content_negotiation, determine_version, perfom_authentication, check_permissions, check_throttles等
- 其中perform_authentication是对于认证的校验,其执行的内容是Request对象的user(@proprity) ,进而执行方法_authenticate,最终完成认证
- 另外_authenticate中还执行了Request对象中的authenticate方法,具体查看源码流程
3.自定义认证类
-
继承BaseAuthentication类,不继承的话需要再写
authenticate_header(self, request)方法 -
必须要重写
authenticate(self, request)方法,一般是返回元组 -
authenticate(self, request)方法会有三种返回(1)元组
(2)None
(3)异常
from rest_framework.authentication import BaseAuthentication
class TestAuthentication(BaseAuthentication):
def authenticate(self, request):
...
return (result, token)
RestFramework还提供其他的认证类,如BasicAuthentication、SessionAuthentication、TokenAuthentication等,定义在rest_framework.authentication中。
权限
1.权限控制可以限制用户对于视图的访问和对于具体数据对象的访问。
- 在执行视图的dispatch()方法前,会先进行视图访问权限的判断
- 在通过get_object()获取具体对象时,会进行对象访问权限的判断
2.使用:
可以在配置文件中设置默认的权限管理类,如
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAuthenticated', # 授权访问
)
}
如果未指明,则采用如下默认配置
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.AllowAny',
)
也可以在具体的视图中通过permission_classes属性来设置,如
from rest_framework.permissions import IsAuthenticated
from rest_framework.viewsets import ModelViewSet
BooksModelViewSet(ModelViewSet):
permission_classes = (IsAuthenticated,) #登录授权用户
...
3.自定义权限控制类
- 继承BasePermission类,然后重写下面的方法
- 返回值为布尔型
from rest_framework.permissions import BasePermission
class TestPermission(BasePermission):
def has_permission(self, request, view):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return True
def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return True
提供的权限控制类,在rest_framework.permissions中:
- AllowAny 允许所有用户
- IsAuthenticated 仅通过认证的用户
- IsAdminUser 仅管理员用户
- IsAuthenticatedOrReadOnly 认证的用户可以完全操作,否则只能get读取
- DjangoModelPermissions等
限流
1.可以对接口访问的频次进行限制,以减轻服务器压力,主要用于反爬虫。
2.使用:
可以在配置文件中,使用DEFAULT_THROTTLE_CLASSES 和 DEFAULT_THROTTLE_RATES进行全局配置,
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle'
),
#DEFAULT_THROTTLE_RATES 可以使用 second, minute, hour 或day来指明周期。
'DEFAULT_THROTTLE_RATES': {
'anon': '5/day', # 匿名用户每天访问5次
'user': '100/day' # 登录用户访问100次
}
}
也可以在具体视图中通过throttle_classes属性来配置,如
from rest_framework.throttling import UserRateThrottle
from rest_framework.views import APIView
class BookListView(APIView):
throttle_classes = (UserRateThrottle,)
...
3.自定义限流类
- 一般继承SimpleRateThrottle类,然后必须重写
get_cache_key方法并定义scope,返回为字典 - 如果继承BaseThrottle类,则还需要重写
allow_request,返回为布尔类型
from rest_framework.throttling import BaseThrottle, SimpleRateThrottle
class TestThrottle(SimpleRateThrottle)
scope = 'user'
def get_cache_key(self, request, view):
if request.user.is_authenticated:
ident = request.user.pk
else:
ident = self.get_ident(request)
return self.cache_format % {
'scope': self.scope,
'ident': ident
}
# 一般继承SimpleRateThrottle,而不是BaseThrottle
class BaseThrottle:
"""
Rate throttling of requests.
"""
def allow_request(self, request, view):
"""
Return `True` if the request should be allowed, `False` otherwise.
"""
raise NotImplementedError('.allow_request() must be overridden')
可选限流类,定义在rest_framework.throttling中
1) AnonRateThrottle
限制所有匿名未认证用户,使用IP区分用户。
使用DEFAULT_THROTTLE_RATES['anon'] 来设置频次
2)UserRateThrottle
限制认证用户,使用User id 来区分。
使用DEFAULT_THROTTLE_RATES['user'] 来设置频次
3)ScopedRateThrottle
限制用户对于每个视图的访问频次,使用ip或user id。
版本
1.在给外部提供的API中,可会存在多个版本,为了区分不同版本,django rest framework提供了4种版本类供我们选择。
-
QueryParameterVersioning:在url中传递版本,如:
http://www.example.com/api?version=v1 -
URLPathVersioning:在url路径传递版本,如:
http://www.example.com/api/v1 -
AcceptHeaderVersioning:在请求头的
Accept中传递版本,如:GET /something/ HTTP/1.1 Host: example.com # 指定version Accept: application/json; version=1.0 -
NamespaceVersioning:后端在定义url是指定namespace用于区分版本,对使用者而言类似URLPathVersioning
# 使用namespace指定版本 urlpatterns = [ url(r'^v1/', include('users.urls', namespace='v1')), url(r'^v2/', include('users.urls', namespace='v2')) ]
2.使用
在配置文件中全局配置
REST_FRAMEWORK = {
# 版本控制
"DEFAULT_VERSIONING_CLASS": 'rest_framework.versioning.URLPathVersioning',
"ALLOWED_VERSIONS": ['v1', "v2"],
"DEFAULT_VERSION": "v1"
"VERSION_PARAM": "version"
}
也可以在视图中指定
class ExampleView(APIView):
versioning_class = "v1"
然后在url中编写相对应的url即可。
3.自定义版本控制类:
- 继承BaseVersioning类,重写
determine_version(self, request, *args, **kwargs)方法 - 一般直接使用内置的类,不需要自己写
from rest_framework.versioning import (
BaseVersioning,
QueryParameterVersioning,
URLPathVersioning
)
# 一般直接使用内置的类,不需要自己写
class TestVersion(BaseVersioning):
"""
自定义的version,通过get参数传参
"""
def determine_version(self, request, *args, **kwargs):
version = request.query_params.get('version')
return version
- 需要注意的是:在view中会返回request.version,用于获取版本;request.versioning_scheme:获取版本的对象。
- reverse:反向生成url,需要定义url中的name(如需反向生成url,则重写reverse函数)
过滤
1.对于列表数据可能需要根据字段进行过滤。
可以通过添加django-fitlter扩展来增强支持, 但过滤的视图应要求是实现了ListModelMixin扩展类及其子类的视图。
pip install django-filter
2.使用:
在配置文件中增加全局配置:
INSTALLED_APPS = [
...
'django_filters', # 需要注册应用,
]
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',)
}
在视图中添加filterset_fields属性,指定可以过滤的字段
class BookListViewSet(ModelViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
filterset_fields = ('title', 'author')
3.自定义过滤类
- 继承BaseFilterBackend类,重写
filter_queryset(self, request, queryset, view)方法 - 返回queryset
from rest_framework.filters import BaseFilterBackend
from django_filters.rest_framework import DjangoFilterBackend
class MyBaseFilterBackend(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
"""
Return a filtered queryset.
"""
...
return queryset
BaseFilterBackend定义在rest_framework.filters中,另外。通常使用django_filters.rest_framework中的DjangoFilterBackend类作为基础过滤类,支持 REST framework 高度自定义字段过滤。
4.使用 排序OrderingFilter
对于列表数据,REST framework提供了OrderingFilter过滤器来按照指定字段进行排序。同样要实现ListModelMixin扩展类及子类的视图才能使用。
-
在类视图中设置
filter_backends,使用rest_framework.filters.OrderingFilter过滤器,REST framework会在请求的查询字符串参数中检查是否包含了ordering参数,如果包含了ordering参数,则按照ordering参数指明的排序字段对数据集进行排序。class BookListViewSet(ModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoSerializer filter_backends = [OrderingFilter] ordering_fields = ('id', 'bread', 'bpub_date') -
默认情况下,查询参数被命名为
'ordering',但这可能会被ORDERING_PARAM设置覆盖。例如,要按 username 对用户排序:
# 正序 http://example.com/api/users?ordering=username # 倒序 http://example.com/api/users?ordering=-username # 多个字段排序,用逗号隔开 http://example.com/api/users?ordering=account,username
注意:如果在视图上未指定 ordering_fields 属性,则过滤器类将默认允许用户过滤由 serializer_class 属性指定的序列化器中的任何可读字段,所以最好指定,避免数据泄漏。
-
指定默认排序使用ordering
# 正序 ordering = ('username',) 或 ordering = ['username'] # 倒序 ordering = ('-username',) 或 ordering = ['-username']
5.使用SearchFilter过滤类
SearchFilter 类支持简单的基于单个查询参数的搜索,并且基于 Django 管理员的搜索功能。
class UserListView(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
filter_backends = (filters.SearchFilter,)
search_fields = ('username', 'email')
这将允许客户端通过查询来过滤列表中的项,例如:
http://example.com/api/users?search=russell
还可以使用查找 API 双下划线表示法对 ForeignKey 或 ManyToManyField 执行相关查找:
search_fields = ('username', 'email', 'profile__profession')
默认情况下,搜索将使用不区分大小写的部分匹配。搜索参数可能包含多个搜索项,它们应该是空格和/或逗号分隔的。如果使用多个搜索项,则只有在所有提供的项匹配的情况下,对象才会返回到列表中。
可以通过在 search_fields 之前添加各种字符来限制搜索行为。
- '^' 开始搜索。
- '=' 完全匹配。
- '@' 全文搜索。(目前只支持 Django 的 MySQL 后端。)
- '$' 正则表达式搜索。
举个栗子:
search_fields = ('=username', '=email')
默认情况下,搜索参数被命名为 'search',但这可能会被 SEARCH_PARAM 设置覆盖。
解析器
1.REST framework 提供了Parser解析器,在接收到请求后会自动根据Content-Type指明的请求数据类型(如JSON、表单等)将请求数据进行parse解析,解析为类字典对象保存到Request对象中。
注意:Request对象的数据是自动根据前端发送数据的格式进行解析之后的结果(上文中认证流程提到了对原生request进行进行一步封装,其中的parsers就是指解析器)
值得一提的是,无论前端发送的哪种格式的数据,我们只需要使用以下两种方式读取数据:
1)request.data
request.data 返回解析之后的请求体(表单、json)数据。类似于Django中标准的request.POST和 request.FILES属性,但提供如下特性:
- 包含了
解析之后的文件和非文件数据 - 包含了对POST、PUT、PATCH请求方式解析后的数据
- 利用了REST framework的parsers解析器,不仅支持表单类型数据,也支持JSON数据
2)query_params
request.query_params与Django标准的request.GET相同,用于获取查询字符串,只是更换了更正确的名称而已。
2.使用:
在配置文件中全局定义:
REST_FRAMEWORK = {
...
'DEFAULT_PARSER_CLASSES': {
'rest_framework.parsers.JSONParser',
}
}
在视图中添加parser_classes
from rest_framework.versioning import URLPathVersioning
from rest_framework.parsers import JSONParser
class UserView(APIView):
'''查看用户信息'''
parser_classes = [JSONParser,]
versioning_class =URLPathVersioning
def get(self,request,*args,**kwargs):
res={"name":"wd","age":22}
return JsonResponse(res,safe=True)
def post(self,request,*args,**kwargs):
print(request.data) #获取解析后的请求结果
return JsonResponse({"success":"ok"}, safe=True)
3.可使用的解析类(不用自己定义或重写,直接使用就好)
- JSONParser :对应'application/json'
- FormParser:对应'application/x-www-form-urlencoded'
- MultiPartParser:对应'multipart/form-data'
- FileUploadParser:对应
'*/*'
在当前实际使用中,基本没有手动去指定使用哪一种或哪几种解析类。
序列化
1.序列化器允许将复杂数据 (如查询集和模型实例) 转换为可以轻松渲染成 JSON,XML 或其他内容类型的原生 Python 数据类型。序列化器还提供反序列化,在验证传入的数据之后允许解析数据转换回复杂类型。
序列化器的作用:
- 进行数据的校验
- 对数据对象进行转换
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。
现在创建一个类(非数据库模型类)
from datetime import datetime
class Comment(object):
def __init__(self, email, content, created=None):
# 三个字段
self.email = email
self.content = content
self.created = created or datetime.now()
comment = Comment(email='leila@example.com', content='foo bar')
序列化的声明如下:
from rest_framework import serializers
class CommentSerializer(serializers.Serializer):
# 对应上面定义的三个字段
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()
这样便可以通过序列化类,实现 Python 原生的数据类型(这里是comment对象)与Json格式数据的相互转换。
# 序列化
serializer = CommentSerializer(comment)
# 序列化后的json数据
serializer.data
# 反序列化(json格式数据转回Comment类对象类型)
serializer = CommentSerializer(data=data)
# 验证
serializer.is_valid()
serializer.validated_data
2.关联对象嵌套序列化
1) PrimaryKeyRelatedField
此字段将被序列化为关联对象的主键。属性使用related_name的值,如果没有则使用关联类小写_set(heroinfo_set)
user = serializers.PrimaryKeyRelatedField( read_only=True)
- 指定read_only=True时,该字段将不能用作反序列化使用
- StringRelatedField
此字段将被序列化为关联对象的字符串表示方式(即关联模型类__str__方法的返回值)
3)使用关联对象的序列化器
user = UserInfoSerializer(many=True) # 根据指定的UserInfoSerialzier序列化中指定的字段返回
3.反序列化
-
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象;
-
在获取反序列化的数据前,必须调用
is_valid()方法进行验证,验证成功返回True,否则返回False; -
验证失败,可以通过序列化器对象的
errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名;
验证成功,可以通过序列化器对象的validated_data属性获取数据。
4.自定义验证
序列化的is_valid()方法提供的验证只能验证对应的字段和类型,对应一些额外的验证需要我们自己去实现
1)验证单一字段
class BookInfoSerializer(serializers.Serializer):
# 方法名定义为validated_字段名
def validated_btitle(self, value):
if value == 'python':
raise serializers.ValidationError('书名python错误')
return value
2)验证多个字段
class BookInfoSerializer(serializers.Serializer):
# 方法名定义为validate
def validate(self, attrs):
bread = attrs['bread']
bcomment = attrs['bcomment']
if bread < bcomment:
raise serializers.ValidationError('阅读量小于评论量')
return attrs
5.保存数据
如果在验证成功后,想要基于validated_data类属性完成数据对象的创建,可以通过实现create()和update()两个方法来实现。
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def create(self, validated_data):
"""新建"""
return BookInfo.objects.create(**validated_data)
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
# 存入数据库
instance.save()
return instance
注:如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
6.模型类序列化器ModelSerializer
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现,update方法不支持多个创建
1)定义
要使用要继承serializers.ModelSerializer
比如我们创建一个BookInfoSerializer:
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
# 返回所有字段
fields = '__all__'
# 返回特定字段
# fields = ['id', 'name']
# 除去特定字段
# exclude = ['id']
- model 指明参照哪个模型类
- fields 指明为模型类的哪些字段生成
- exclude 指明不生成那些字段,与fields只能二选一进行使用
2)可以在django环境中执行python manage.py shell命令来查看自动生成的BookInfoSerializer的具体实现。
>>> from booktest.serializers import BookInfoSerializer
>>> serializer = BookInfoSerializer()
>>> serializer
BookInfoSerializer():
id = IntegerField(label='ID', read_only=True)
btitle = CharField(label='名称', max_length=20)
bpub_date = DateField(allow_null=True, label='发布日期', required=False)
bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False)
bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False)
image = ImageField(allow_null=True, label='图片', max_length=100, required=False)
3)添加额外参数
可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
分页
1.使用:
配置文件中设置全局的分页方式,如:
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5 # 每页数目
}
也可在视图中通过pagination_class属性来指明。
from rest_framework.pagination import PageNumberPagination
class BookDetailViewSet(ModelViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
pagination_class = PageNumberPagination
注意:如果在视图内关闭分页功能,只需在视图内设置
pagination_class = None
2.自定义分页类:
- 继承PageNumberPagination,自定义get_paginated_response(self, data)函数
- 返回Response对象
from rest_framework.pagination import PageNumberPagination
class StandardPageNumberPagination(PageNumberPagination):
page_size_query_param = 'page_size'
max_page_size = 10
class BookDetailViewSet(ModelViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
pagination_class = StandardPageNumberPagination
- 使用
books/?page=1&page_size=5请求每页会返回5条数据
3.DjangoRestFramework提供了三种分页组件:
- PageNumberPagination:普通分页,查看第n页,每个页面显示n条数据。可以在子类中定义的属性:
- page_size 每页数目
- page_query_param 前端发送的页数关键字名,默认为"page"
- page_size_query_param 前端发送的每页数目关键字名,默认为None
- max_page_size 前端最多能设置的每页数量
2)LimitOffsetPagination:基于位置的分页,在第n个位置,向后查看n条数据,和数据库的sql语句中的limit offset类似,参数offet代表位置,limit代表取多少条数据。可以在子类中定义的属性:
- default_limit 默认限制,默认值与
PAGE_SIZE设置一样 - limit_query_param limit参数名,默认'limit'
- offset_query_param offset参数名,默认'offset'
- max_limit 最大limit限制,默认None
3)CursorPagination:游标分页,意思就是每次返回当前页、上一页、下一页,并且每次的上一页和下一页的url是不规则的。
- cursor_query_param 参数名,默认为'cursor'
- page_size 每页数目
- page_size_query_param 参数名,默认为None
- max_page_size 前端最多能设置的每页数量
- ordering 排序规则,默认为'-created'
视图

APIView
1.APIView是REST framework提供的所有视图的基类,继承自Django的View父类。
2.APIView与View的不同之处在于:
- 传入到视图方法中的是REST framework的
Request对象,而不是Django的HttpRequeset对象; - 视图方法可以返回REST framework的
Response对象,视图会为响应数据设置(render)符合前端要求的格式; - 任何
APIException异常都会被捕获到,并且处理成合适的响应信息; - 在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制。
3.支持定义的属性:
- authentication_classes 列表或元祖,身份认证类
- permissoin_classes 列表或元祖,权限检查类
- throttle_classes 列表或元祖,流量控制类
在APIView中仍以常规的类视图定义方法来实现get() 、post() 或者其他请求方式的方法。
from rest_framework.views import APIView
from rest_framework.response import Response
# url配置写法
# url(r'^books/$', views.BookListView.as_view()),
class BookListView(APIView):
def get(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
GenericAPIView
rest_framework.generics.GenericAPIView继承自APIVIew,增加了对于列表视图和详情视图可能用到的通用支持方法。通常使用时,可搭配一个或多个Mixin扩展类。
1.支持定义的属性:
1)列表视图与详情视图通用:
- queryset:列表视图的查询集
- serializer_class :视图使用的序列化器
2)列表视图使用:
- pagination_class :分页控制类
- filter_backends :过滤控制后端
3)详情页视图使用:
- lookup_field :查询单一数据库对象时使用的条件字段,默认为'
pk' - lookup_url_kwarg :查询单一数据时URL中的参数关键字名称,默认与look_field相同
2.提供的方法:
1)列表视图与详情视图通用:
-
get_queryset(self)
返回视图使用的查询集,是列表视图与详情视图获取数据的基础,默认返回
queryset属性,可以需要进行重写。 -
get_serializer_class(self)
返回序列化器类,默认返回
serializer_class,可以需要进行重写,用于不同的接口需要的序列化内容不一致的情况。例如:def get_serializer_class(self): if self.request.user.is_staff: return FullAccountSerializer return BasicAccountSerializer -
get_serializer(self, *args, **kwargs)
返回序列化器对象,被其他视图或扩展类使用,如果我们在视图中想要获取序列化器对象,可以直接调用此方法。
注意,在提供序列化器对象的时候,REST framework会向对象的context属性补充三个数据:request、format、view,这三个数据对象可以在定义序列化器时使用。
2)详情视图使用:
-
get_object(self)
返回详情视图所需的模型类数据对象,默认使用
lookup_field参数来过滤queryset。 在视图中可以调用该方法获取详情信息的模型类对象。注意:
1.若详情访问的模型类对象不存在,会返回404。
2.该方法会默认使用
APIView提供的check_object_permissions方法检查当前对象是否有权限被访问。def get_object(self): queryset = self.filter_queryset(self.get_queryset()) # 确认使用的过滤字段. lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field assert lookup_url_kwarg in self.kwargs, ( 'Expected view %s to be called with a URL keyword argument ' 'named "%s". Fix your URL conf, or set the `.lookup_field` ' 'attribute on the view correctly.' % (self.__class__.__name__, lookup_url_kwarg) ) filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]} # 模型类对象不存在,会返回404 obj = get_object_or_404(queryset, **filter_kwargs) # 权限校验 self.check_object_permissions(self.request, obj) return obj
五个扩展类
1.ListModelMixin
列表视图扩展类,提供list(request, *args, **kwargs)方法快速实现列表视图,返回200状态码。
class ListModelMixin:
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
2.CreateModelMixin
创建视图扩展类,提供create(request, *args, **kwargs)方法快速实现创建资源的视图,成功返回201状态码。如果序列化器对前端发送的数据验证失败,返回400错误。
class CreateModelMixin:
"""
Create a model instance.
"""
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
serializer.save()
def get_success_headers(self, data):
try:
return {'Location': str(data[api_settings.URL_FIELD_NAME])}
except (TypeError, KeyError):
return {}
3.RetrieveModelMixin
详情视图扩展类,提供retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。如果存在,返回200, 否则返回404。
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
4.UpdateModelMixin
更新视图扩展类,提供update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。同时也提供partial_update(request, *args, **kwargs)方法,可以实现局部更新。成功返回200,序列化器校验数据失败时,返回400错误。
class UpdateModelMixin:
"""
Update a model instance.
"""
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
def partial_update(self, request, *args, **kwargs):
kwargs['partial'] = True
return self.update(request, *args, **kwargs)
5.DestroyModelMixin
删除视图扩展类,提供destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。成功返回204,不存在返回404。
class DestroyModelMixin:
"""
Destroy a model instance.
"""
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
self.perform_destroy(instance)
return Response(status=status.HTTP_204_NO_CONTENT)
def perform_destroy(self, instance):
instance.delete()
RestFramework根据GenericAPIView和五个扩展类提供了一些可用的视图,如:
# 源码,这里例举三个,其他的类似
class CreateAPIView(mixins.CreateModelMixin,
GenericAPIView):
"""
Concrete view for creating a model instance.
"""
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class UpdateAPIView(mixins.UpdateModelMixin,
GenericAPIView):
"""
Concrete view for updating a model instance.
"""
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def patch(self, request, *args, **kwargs):
return self.partial_update(request, *args, **kwargs)
class ListCreateAPIView(mixins.ListModelMixin,
mixins.CreateModelMixin,
GenericAPIView):
"""
Concrete view for listing a queryset or creating a model instance.
"""
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
可根据实际需要进行选取,然后继承实现对应功能。
视图集
ViewSet
1.使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中:
- list() 提供一组数据
- retrieve() 提供单个数据
- create() 创建数据
- update() 保存数据
- destory() 删除数据
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 如 list() 、create() 等。
class BookInfoViewSet(viewsets.ViewSet):
def list(self, request):
...
def retrieve(self, request, pk=None):
...
设置路由(视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上)如:
urlpatterns = [
url(r'^books/$', BookInfoViewSet.as_view({'get':'list'}),
url(r'^books/(?P<pk>\d+)/$', BookInfoViewSet.as_view({'get': 'retrieve'})
]
2.action属性
在视图集中,我们可以通过action对象属性来获取当前请求视图集时的action动作是哪个,通常通过action来区分使用的序列化类,如:
def get_serializer_class(self):
if self.action == 'create':
return BookInfoSerializer
else:
return BookDetialInfoSerializer
视图集类
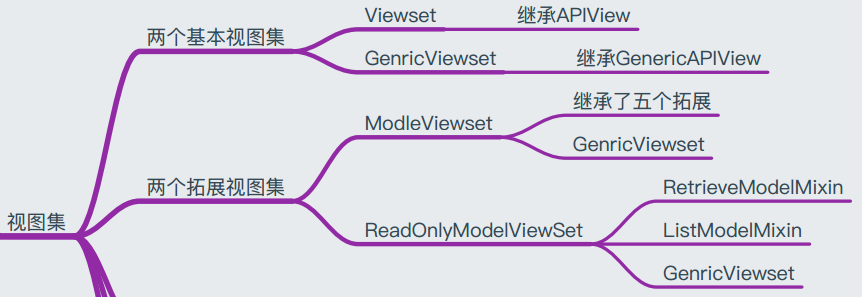
1.ViewSet
继承自APIView和ViewSetMixin,作用与APIView基本类似,提供了身份认证、权限校验、流量管理等。
在ViewSet中,没有提供任何动作action方法,需要自己实现action方法。而ViewSetMixin类的as_view方法设置了类的action属性,并将我们定义的action方法与请求方式进行绑定, 存于action_map属性(字典)中。
2.GenericViewSet
继承自GenericAPIView,作用也与GenericAPIVIew类似,提供了get_object、get_queryset等方法便于列表视图与详情信息视图的开发。
3.ReadOnlyModelViewSet
继承自GenericAPIVIew,同时包括了ListModelMixin、RetrieveModelMixin。
4.ModelViewSet
继承自GenericAPIVIew,同时包括了ListModelMixin、RetrieveModelMixin、CreateModelMixin、UpdateModelMixin、DestoryModelMixin。即所有增删改查功能都具备。
路由
1.对于视图集ViewSet,除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来快速实现路由信息。
REST framework提供了两个router
- SimpleRouter
- DefaultRouter
SimpleRouter和DefaultRouter的区别在于后者能生成首页(方便查看所有接口 ),而前者不能。
2.使用:
1) 创建router对象,并注册视图集,例如
from rest_framework import routers
router = routers.SimpleRouter()
router.register(r'books', BookInfoViewSet, base_name='book')
register(prefix, viewset, base_name)
- prefix 该视图集的路由前缀
- viewset 视图集
- base_name 路由名称的前缀
如上述代码会形成的路由如下:
^books/$ name: book-list
^books/{pk}/$ name: book-detail
2)添加路由数据
可以有两种方式:
urlpatterns = [ ... ]
urlpatterns += router.urls复制代码
或
urlpatterns = [ ..., url(r'^', include(router.urls))]
这种方式只会生成视图集扩展类里面定义的方法,对于自定义的方法不能生成。
3)视图集中包含附加action
导入rest_framework.decorators.action装饰器可解决上面自定义的方法不能生成的问题。
from rest_framework.decorators import action
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
@action(methods=['get'], detail=False) #detail = False不生成正则匹配
def read(self, request, pk):
...
@action(methods=['put'], detail=True)#detail = True生成正则匹配
def modify(self, request, pk):
...
此视图集会形成的路由:
^books/read/$ name: book-read
^books/{pk}/modify/$ name: book-modify
注意:要使用自动生成路由的方法,视图必须继承自视图集。
TODO:使用视图集只能处理前端通过request发过来的数据是表单或json数据的类型。
3.几种常用的路由写法
from django.conf.urls import url,include
# APIView类型的url
url(r'^api/v1/users/', views.UserView.as_view())
# ViewSet类型的url,对请求方法进行映射
url(r'^api/v1/users/', views.UserView.as_view({'get':'list','post':'create'}))
url(r'^api/v1/users/(?P<pk>\d+)$', views.UserView.as_view({'get':'retrieve','delete':'destroy','put':'update','patch':'partial_update'})),
# 使用路由器
from rest_framework import routers
router=routers.DefaultRouter() #是列化router类
router.register(r'userinfo$',views.UserView) #注册一个url,后续会生成我们想要的个url
urlpatterns = [
url(r'^api/v1/',include(router.urls)),#将生成的url加入到路由中
]
响应
1.REST framework提供了一个响应类Response,使用该类构造响应对象时,响应的具体数据内容会被转换(render渲染)成符合前端需求的类型。
Response(self, data=None, status=None, template_name=None, exception=False, headers=None, content_type=None)
参数说明:
data: 响应准备的序列化处理后的数据,一般为字典类型;status: 状态码,默认200;template_name: 模板名称,如果使用HTMLRenderer时需指明;headers: 用于存放响应头信息的字典;exception: 异常, 默认为Falsecontent_type: 响应数据的Content-Type,通常此参数无需传递,REST framework会根据前端所需类型数据来设置该参数。
2.状态码:
REST framewrok在rest_framework.status模块中提供了常用状态码常量。常用的几个:
HTTP_200_OK = 200
HTTP_201_CREATED = 201
HTTP_202_ACCEPTED = 202
HTTP_302_FOUND = 302
HTTP_400_BAD_REQUEST = 400
HTTP_401_UNAUTHORIZED = 401
HTTP_403_FORBIDDEN = 403
HTTP_404_NOT_FOUND = 404
HTTP_500_INTERNAL_SERVER_ERROR = 500
异常处理
1.使用:
采用默认的方式,如下
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler'
}
在配置文件中声明自定义的异常处理
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'my_project.my_app.utils.custom_exception_handler'#定义处理异常的路径,以项目实际为准
}
2.自定义异常处理
REST framework提供了异常处理,可以自定义异常处理函数。
from rest_framework.views import exception_handler
from rest_framework import status
from django.db import DatabaseError
def custom_exception_handler(exc, context):
# 先调用REST framework默认的异常处理方法获得标准错误响应对象
response = exception_handler(exc, context)
# 在此处补充自定义的异常处理
if response is not None:
response.data['status_code'] = response.status_code
view = context['view']
# 数据库的异常
if isinstance(exc, DatabaseError):
print('[%s]: %s' % (view, exc))
response = Response({'detail': '服务器内部错误'}, status=status.HTTP_507_INSUFFICIENT_STORAGE)
return response
3.REST framework定义的异常
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败
参考
1.官方文档
2.中文文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号