Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考
主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过于复杂,先完成一个小目标
环境:
python 3.6
主要问题:
1. 在爬取美团黄山酒店第一页后,顺利拿到想要的信息,但在点击第二页后,chrome中检查信息能够看见想要的信息,但是查看源代码却没有,思考后,应该是Ajax动态获取的,然后查找办法,最终通过selenium模拟浏览器,然后进行爬取
2. 标签查找,通过chrome进行分析整体网站标签信息后,对某一个标签的class未清楚认识,导致错误认识,消耗比较长的调试时间
代码如下:
import requests from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities import xlwt url = 'http://hotel.meituan.com/huangshan/' #获取酒店分页信息,返回最大页码 def get_page_num(url): html = requests.get(url).text soup = BeautifulSoup(html,'lxml') page_info = soup.find_all('li',class_='page-link') #获取酒店首页的页面导航条信息 page_num = page_info[-1].find('a').get_text() #获取酒店页面的总页数 return int(page_num) #返回酒店页面的总页数 #获取所有酒店详细信息,包含酒店名称,链接,地址,评分,消费人数,价格,上次预定时间 def get_hotel_info(url): dcap = dict(DesiredCapabilities.PHANTOMJS) dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36') #设置userAgent,可以从浏览器中找到,用于反爬虫禁止IP browser = webdriver.PhantomJS("/Users/chenglv/phantomjs-2.1.1-macosx/bin/phantomjs", desired_capabilities=dcap) #指定phantomjs程序路径 browser.get(url) hotel_info = {} hotel_id = ['酒店名','网址','酒店地址','评价','消费人数','价格','上次预约时间'] col_num = 1 page_num = 1 book = xlwt.Workbook(encoding='utf-8',style_compression=0) #创建excel文件 sheet = book.add_sheet('hotel_info',cell_overwrite_ok=True) #创建excel sheet表单 for i in range(len(hotel_id)): #写入表单第一行,即列名称 sheet.write(0,i,hotel_id[i]) #excel中写入第一行列名 while(page_num < get_page_num(url)+1): #获取一个页面的所有酒店信息 for item in browser.find_elements_by_class_name('info-wrapper'): hotel_info['name'] = item.find_element_by_class_name('poi-title').text hotel_info['link'] = item.find_element_by_class_name('poi-title').get_attribute('href') hotel_info['address'] = item.find_element_by_class_name('poi-address').text.split(' ')[1] hotel_info['star'] = item.find_element_by_class_name('poi-grade').text hotel_info['consumers'] = item.find_element_by_class_name('poi-buy-num').text hotel_info['price'] = item.find_element_by_class_name('poi-price').text hotel_info['last_order_time'] = item.find_element_by_class_name('last-order-time').text #将当前页面中的酒店信息获取到后,写入excel的行中 for i in range(len(hotel_info.values())): sheet.write(col_num,i,list(hotel_info.values())[i]) col_num+=1 browser.find_element_by_class_name('paginator').find_element_by_class_name('next').find_element_by_tag_name('a').click() #一个页面写完后,通过点击"下一页"图标至下一页,继续获取 page_num += 1 book.save('hotel_info_huangshan.csv') def main(): get_hotel_info(url) if '__main__' == __name__: main()
运行后结果如下图:
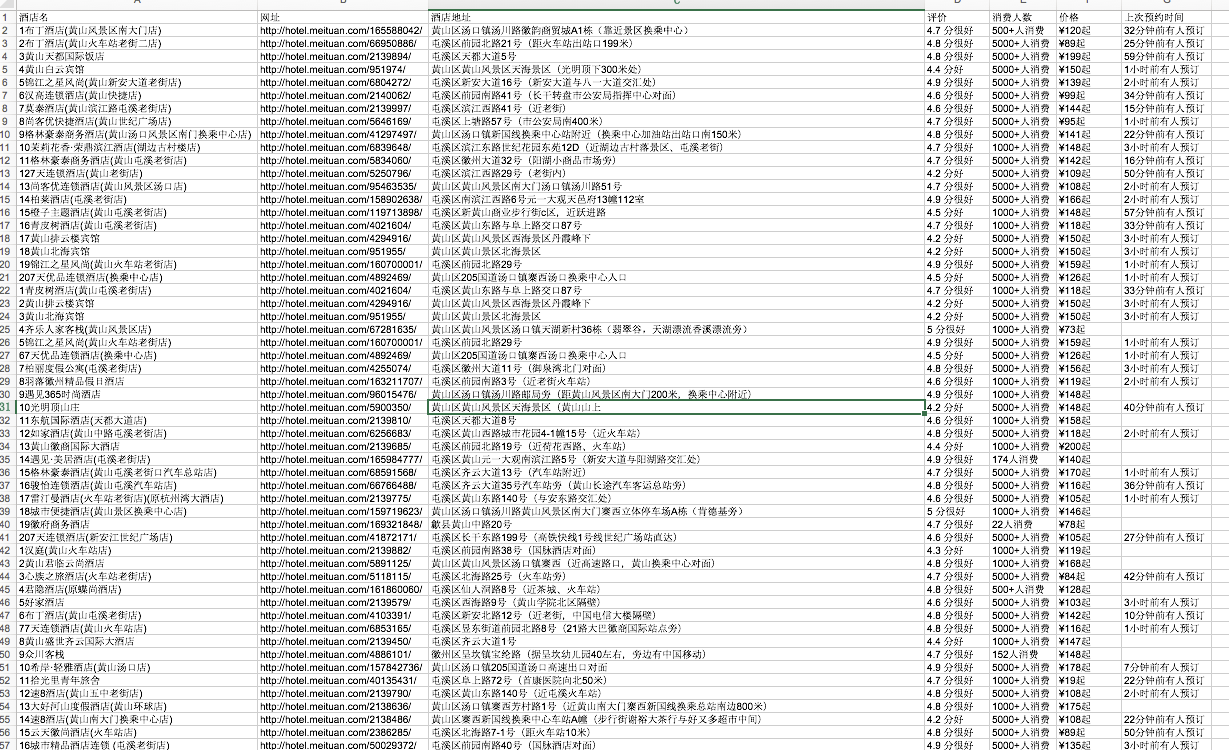
此部分仅因兴趣编写,还有很多未考虑,后期可以进行多层爬取,以及爬取更多的内容。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号