python---内置函数,匿名函数,嵌套函数,高阶函数,序列化
函数简单说明


# 函数即"变量" # 高阶函数 # a.把一个函数名当做实参传给另一个函数(在不修改被装饰函数的源代码的情况下,为其添加功能) # b.返回值中包含函数名(不修改函数的调用方式) ''' import time def bar(): print("in the bar!") time.sleep(2) def foo(func): start_time = time.time() func() #根据内存地址,执行代码 stop_time = time.time() print("run time %s" %(stop_time-start_time)) foo(bar) #函数嵌套,是在一个函数内,用一个def来定义一个新的函数 def foo(): print("in the foo") def bar(): print("in the bar") bar() #函数调用 def foo(): print("in the foo") bar() def bar(): print("in the bar")
匿名函数
1 calc = lambda a,b :a+b 2 print(calc(1,2)) 3 4 calc = lambda n : 3 if n<5 else n*n 5 print(calc(12)) 6 7 res = filter(lambda n:n>5,range(10)) 8 res = map(lambda n:n*n,range(5)) 9 for i in res: 10 print('----',i) 11 12 res = [lambda i:i*2 for i in range(10)]
内置函数
1 # -*- coding:utf-8 -*- 2 # LC 3 print(all([1,2,3,0,4])) #all中的课迭代对象全为真则返回真 4 print(any([1,2,3,0])) #any中有一个为真则返回真 5 print(bin(101)) #把数字转换成2进制 6 print(bool({})) #判断整数是否为真,列表,元组,字典如果为空,则返回False 7 8 a = bytes("abcde",encoding="utf-8") #字符串默认是不能够修改的 9 b = bytearray("abcde",encoding="utf-8") #将原有数据变化成一个列表,并且可以改变 10 b[1] = 100 #改变列表中的值,但必须要赋值一个整型,为ASCII码表对应的数字,即d对应ASCII码中的100 11 print("----",b) 12 13 callable([]) #判断是否为可调用对象,函数,类都是可以调用的,即是否有()调用 14 print(callable([])) 15 def hel():pass 16 print(callable(hel)) 17 18 chr(100) #输入数字,返回数字对应的unicode表中的字符 19 print("----",chr(97)) 20 21 ord("i") #输入字符,将字符对应的unicode表的数字返回 22 print(ord("你")) 23 24 code = "for i in range(10):print(i)" 25 exec(code) #exec能够将字符串转换成可执行代码并执行 26 27 print(dir(code)) #查看一点对象具体有什么方法可以使用 28 29 print(divmod(10.2,2.2)) #查看两张相除的结果及余数 30 31 #enumerate([]) #将可迭代对象按着序列号排序 32 list1 = ['January','February','March','April','May','June','July','August','September','October','November','December'] 33 print(list(enumerate(list1,start=1))) #表示从1开始计数,将list1中的对象分配一个序号 34 for index,i in enumerate(list1,start=1): 35 print(index,i) 36 37 #filter 38 res = filter(lambda n:n>5,range(10)) #结合lambda,filter将lambda中为True的返回 39 for i in res: 40 print(i) 41 #map 42 res = map( lambda n:n*2,range(6)) #map将lambda range中所有的元素进行运算 43 for i in res: 44 print(i) 45 46 res = [lambda i:i*2 for i in range(10)] 47 #reduce 48 import functools 49 rese = functools.reduce(lambda x,y:x+y,range(5)) #表示x,y默认从0,1开始,x+y结果传递给x,y每次+1,并把结果给x,(即列表中所有数字相加) 50 print(rese) 51 52 res = functools.reduce(lambda x,y:x*y,range(1,10)) #列表中所有数字相乘 53 print('----',res) 54 55 #frozeset 56 a = frozenset([1,2,3,5,534,4,34,2]) #表示一个不可变集合,即默认集合拥有的方法将无法使用 57 print(a) 58 59 #globals() #将整个程序,仅这个文件的变量按着key,value的格式,字典的方式呈现 60 print(globals()) 61 62 #hash 63 64 #hex #将数字转换成16进制 65 #oct(x) #将数字转换成8进制 66 hex(152) 67 68 #id #返回内存地址 69 print('---',id(1)) 70 71 #locals() #寻找局部变量中的变量,仅在局部有效 72 73 #max() #找出最大的值 74 #min() 75 76 #pow 77 print(pow(2,4,5)) #求x的y次方,然后使用z求余 78 79 #round 80 print(round(1.232122322,5)) #表示保留小数点后几位 81 82 #sorted 83 a = {5:2,8:0,1:4,-5:7,99:11} 84 print(sorted(a.items())) #将字典a变成列表,并排序,默认按着字典的key排序 85 # 结果:[(-5, 7), (1, 4), (5, 2), (8, 0), (99, 11)] 86 print(sorted(a.items(),key=lambda x:x[1])) #按着字典value排序,使用lambda来指定转换后的列表中的第二个数字排序 87 # 结果:[(8, 0), (5, 2), (1, 4), (-5, 7), (99, 11)] 88 89 #zip #将多个可迭代对象进行相互柔和,以最短的算 90 a = (1,2,3,4,5,6,7) 91 b = ('a','b','c','d','e','f') 92 print(len(b)) 93 c = ('+' for i in range(len(b))) #使用生成器生成一个元组 94 print(c) 95 for i in zip(a,b,c): 96 print(i) 97 98 #map #将可迭代对象按着函数执行,即将可迭代对象的值传递给函数,并返回结果 99 def hel(*args): 100 101 return args 102 for i in map(hel,a,b): 103 print(i)
序列化
1 #json序列化 #json能够将内存中的熟悉序列化值硬盘文件中,json只能序列号简单的,如列表,元组,字典等,函数不行 2 import json 3 info = { 4 'name':'lc', 5 'age':19 6 } 7 f = open("test.txt",'w') 8 f.write(json.dumps(info)) 9 f.close() 10 11 #json反序列化 #json返序列化能够将文件中的数据加载至内存中,保持原格式 12 f = open("test.txt","r") 13 data = json.loads(f.read()) #通过loads来实现 14 print(data["age"]) #可以直接读取 15 f.close() 16 17 #pickle序列化 #pickle能够序列化复杂的对象类型,如函数,pickle仅在python中有效,json是在各种语言中都有效 18 import pickle 19 import json 20 def hello(name): 21 print("hello,",name) 22 info = { 23 'name':'lc', 24 'age':'19', 25 'func':hello #函数 26 } 27 f = open("test.txt","wb") #pickle序列化需要用字节格式 28 pickle.dump(info,f) #等价于f.write(pickle.dumps(info)) 29 f.close() 30 31 #pickle反序列化 32 f = open("test.txt","rb") 33 data = pickle.load(f) #等价于data = pickle.loads(f.read()) 34 print(data["func"]("lvcheng")) 35 f.close()
高阶函数
转载:http://www.cnblogs.com/ghgyj/p/3997548.html
要理解“函数本身也可以作为参数传入”,可以从Python内建的map/reduce函数入手。
如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Processing on Large Clusters”,你就能大概明白map/reduce的概念。
我们先看map。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
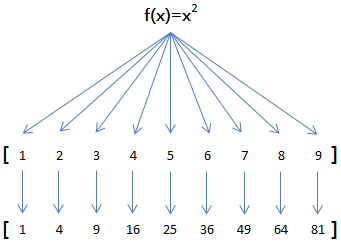
现在,我们用Python代码实现:
>>> def f(x):
... return x * x
...
>>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
请注意我们定义的函数f。当我们写f时,指的是函数对象本身,当我们写f(1)时,指的是调用f函数,并传入参数1,期待返回结果1。
因此,map()传入的第一个参数是f,即函数对象本身。
像map()函数这种能够接收函数作为参数的函数,称之为高阶函数(Higher-order function)。
你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print L
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?
所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数。
再看reduce的用法。reduce把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
>>> def add(x, y):
... return x + y
...
>>> reduce(add, [1, 3, 5, 7, 9])
25
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> def fn(x, y):
... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
13579
这个例子本身没多大用处,但是,如果考虑到字符串str也是一个序列,对上面的例子稍加改动,配合map(),我们就可以写出把str转换为int的函数:
>>> def fn(x, y):
... return x * 10 + y
...
>>> def char2num(s):
... return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
...
>>> reduce(fn, map(char2num, '13579'))
13579
整理成一个str2int的函数就是:
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
return reduce(fn, map(char2num, s))
还可以用lambda函数进一步简化成:
def char2num(s):
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
def str2int(s):
return reduce(lambda x,y: x*10+y, map(char2num, s))
也就是说,假设Python没有提供int()函数,你完全可以自己写一个把字符串转化为整数的函数,而且只需要几行代码!
lambda函数的用法在下一节介绍。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号