原生JS实现后端文件流导出Excel(附Node后端代码)
原生JS实现后端文件流导出Excel(附Node后端代码)
导出文件一般是这两种方式:第一种是后端返回一个路径然后前端直接跳转下载。第二种也是本文使用的方式则是后端返回文件流,前端下载。第二种一般是ajax操作,所以还有可能后端返回的是json格式的错误消息,这些都需要前端做相应的处理。
现在前端技术越来越成熟,这个操作完全可以直接用原生的js实现,这次直接抛开JQuery/axios等ajax库,来学习下原生js如何实现该操作。(学习原生js,虽然可能用不到。但是能加强你对现成的基于原生js封装的库的理解,所以是很有必要的)
下文将依次介绍:
- 后端效果
- XMLHttpRequest实现文件下载
- 处理后端的返回结果
- Fetch实现文件下载
- Node.js后端导出代码
- demo演示
注意:本文很多代码都用了ES6的新特性,有ES5需求的可以用babel转一下。
后端效果
先看看后端的效果是啥样的,我们再写前端代码。
先来看看模拟数据,一个很简单的人员列表,数据是这样的:
为了方便测试api我没有限制Request Method,所以我们可以直接在浏览器看效果。
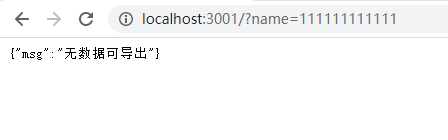
根据名称搜索,没有数据时返回一个提示的json:
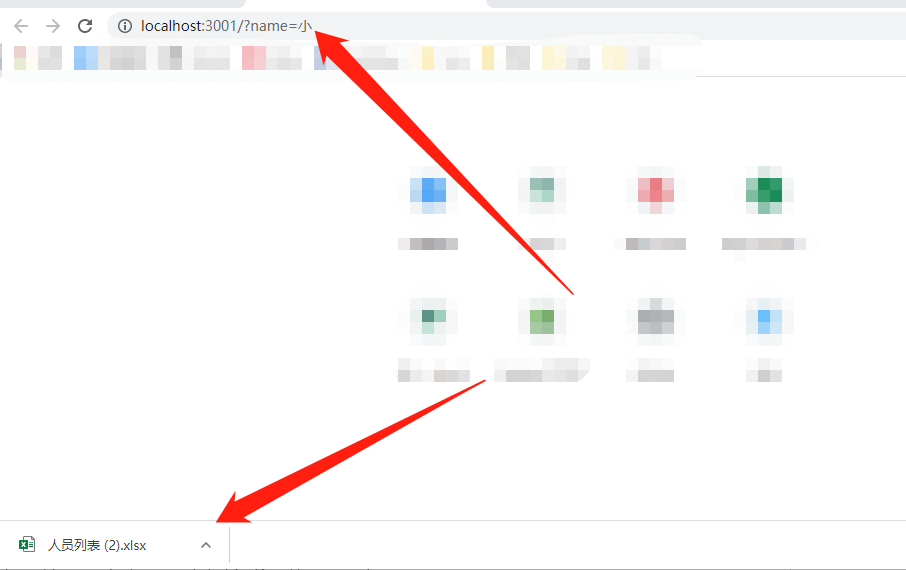
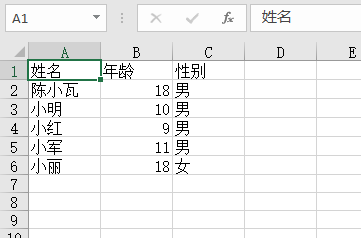
搜索名称中有'小'字的数据,可以下载Excel,excel中的数据是查询结果:
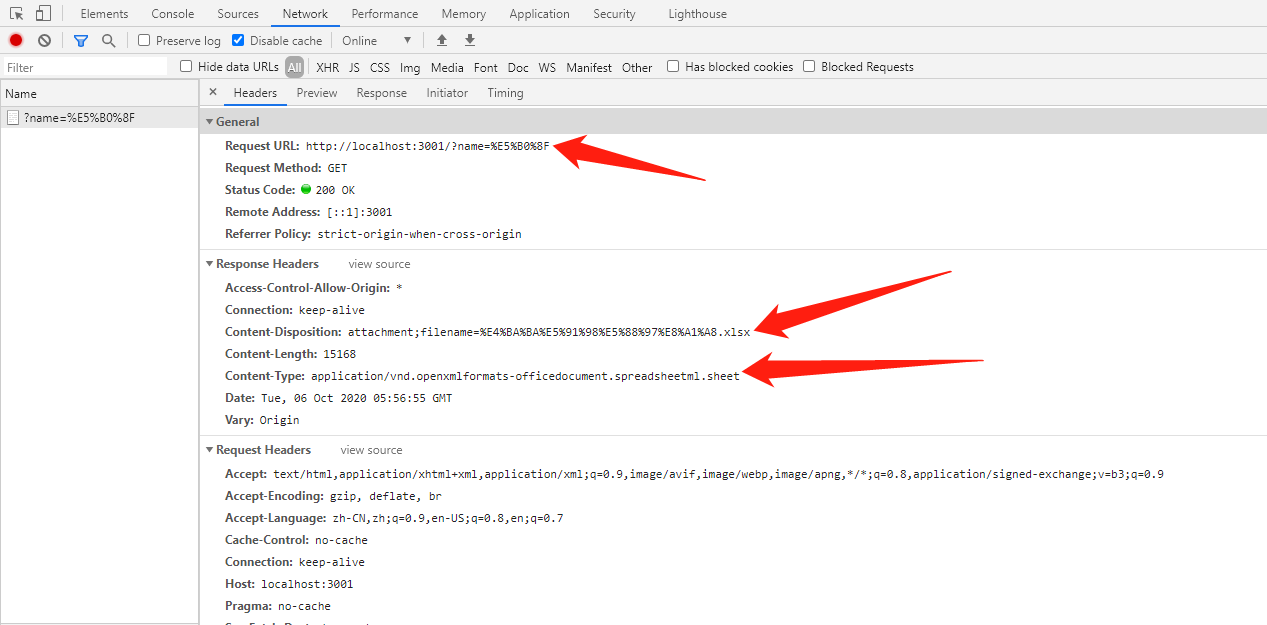
再看看后端的接口信息,中文部分被浏览器自动转码了:
看完后端的效果,咱们可以开始写前端代码。
XMLHttpRequest实现文件下载
先上代码:
//XMLHttpRequest实现文件下载
function exportExcelByXhr(name = '') {
var xhr = new XMLHttpRequest();
xhr.timeout = 3000;
xhr.ontimeout = (event) => alert("请求超时!");
xhr.responseType = 'blob';
xhr.open('GET', baseURL + name, true);
xhr.onreadystatechange = function () {
if (xhr.readyState == XMLHttpRequest.DONE && xhr.status == 200) {
//下载操作:文件流在xhr.response中
handleBlob(xhr.response);
}
}
xhr.send(null);//请求数据
}
流程也很简单,其实就是:
创建一个XMLHttpRequest -> 设置类型为blob -> 传入查询参数请求接口 -> 回调函数中处理响应结果
好像挺简单的,没啥好说的了。
handleBlob是我自己封装的js函数,对后端数据的处理(包括下载Excel,以及json的处理)在这个里面。
处理后端的返回结果
想要处理后端的返回结果,我们得先知道xhr.response是个啥。先打印出来看看吧
console.log(xhr.response);
json的情况:
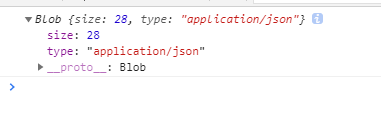
文件流的情况:

好家伙,既然已经知道了是啥玩意,我们就可以直接判断然后做相应的处理了。
只需要判断type是不是json,是json就转json,不是就转文件就行。
上代码:
//处理后端返回的Blob
function handleBlob(responseData) {
if (responseData.type === "application/json") {
const reader = new FileReader();
reader.onload = function () {
const { msg } = JSON.parse(reader.result);
alert(`后端消息:${msg}`);
}
reader.readAsText(responseData, 'utf-8');
} else {
// 如果后端响应头中没有指定 MIME Type , 就需要前端转一下
// const blob = new Blob([responseData], {
// type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
// });
openDownloadFile(responseData, '列表');
}
}
目前代码实现:如果是文件就下载,不是就弹出消息。
下载文件我专门搞了个openDownloadFile方法,里面没有ES6的语法,有需要的可以直接拿去用。
Blob对象和url都可以导出。
/**
* 下载文件
* @param {any} urlObj 要下载的地址 或者 Blob对象
* @param {any} saveName 文件保存的名字 可选参数
*/
function openDownloadFile(urlObj, saveName) {
var openDownload = function (href, fileName) {
var downloadElement = document.createElement('a');
downloadElement.target = "_blank";
downloadElement.href = href;
downloadElement.download = fileName || ""; // HTML5新增的属性,指定保存文件名,可以不要后缀
document.body.appendChild(downloadElement);
downloadElement.click(); // 点击下载
document.body.removeChild(downloadElement); // 下载完成移除元素
}
if (typeof urlObj == 'object' && urlObj instanceof Blob) {
if (window.navigator && window.navigator.msSaveOrOpenBlob) {
//针对于IE浏览器的处理, 因部分IE浏览器不支持createObjectURL
window.navigator.msSaveOrOpenBlob(urlObj, saveName);
} else {
var url = window.URL.createObjectURL(urlObj); // 创建blob地址
openDownload(url, saveName);
window.URL.revokeObjectURL(url); // 释放掉blob对象创建的地址
}
} else {
openDownload(urlObj, saveName);
}
}
Fetch实现文件下载
Fetch是2017年甚至更早出来的一个可以代替XMLHttpRequest做ajax请求的方式。虽然好像出来好几年了,但是IE所有版本都是不支持的,其它浏览器在2017年之后发布的版本应该可以用。同时Fetch不属于ECMAScript的范畴,它属于Web API。
直接上代码,也挺简单的:
//Fetch实现文件下载
function exportExcelByFetch(name = '') {
fetch(baseURL + name, {
method: 'GET', // or 'PUT'
body: null, // data can be `string` or {object}!
headers: new Headers({
'responseType': 'blob'
})
})
.then(response => response.blob())
.then(data => {
handleBlob(data);
});
}
Node.js后端导出代码
搞了这么久前端咱们来看看后端怎么实现的吧。
代码:
const Koa = require('koa');
const XLSX = require('xlsx');
const cors = require('koa2-cors');
const app = new Koa();
const titles = ['姓名', '年龄', '性别'];
const data = [
{ name: '陈小瓦', age: 18, sex: '男' },
{ name: '李飞', age: 33, sex: '男' },
{ name: '林妹妹', age: 22, sex: '女' },
{ name: '小明', age: 10, sex: '男' },
{ name: '小红', age: 9, sex: '男' },
{ name: '小军', age: 11, sex: '男' },
{ name: '小丽', age: 18, sex: '女' },
{ name: '甲', age: 45, sex: '男' },
{ name: '乙', age: 21, sex: '男' },
{ name: '丁', age: 55, sex: '女' },
{ name: '武丑', age: 100, sex: '男' },
{ name: '子牛', age: 101, sex: '男' },
{ name: '盐虎', age: 102, sex: '男' },
{ name: '峰儿', age: 26, sex: '男' },
{ name: '坤鸡', age: 22, sex: '男' },
];
app.use(cors());
app.use((ctx, next) => {
if (ctx.path === '/') {
next();
return;
}
//不是根目录访问全部返回404
ctx.status = 404;
});
app.use((ctx, next) => {
const name = ctx.query["name"];
//获取查询条件查询
const queryData = data.filter(p => p.name.includes(name));
let result, mimeType, filename;
if (queryData.length > 0) {
const xlsData = [titles];
for (const item of queryData) {
let d = [item.name, item.age, item.sex];
xlsData.push(d);
}
//json转excel
let sheet = XLSX.utils.aoa_to_sheet(xlsData);
//excel转node文件流
result = sheetToBuffer(sheet);
mimeType = 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet';
filename = `attachment;filename=${encodeURIComponent('人员列表')}.xlsx`;
} else {
result = { msg: '无数据可导出' };
mimeType = "application/json; charset=utf-8";
}
ctx.body = result;
ctx.set("Content-Type", mimeType);
if (filename) {
ctx.set("Content-Disposition", filename);
}
ctx.status = 200;
});
app.listen(3001);
/**
* 获取excel文件流
*/
function sheetToBuffer(sheet, sheetName) {
sheetName = sheetName || 'sheet1';
let workbook = {
SheetNames: [sheetName],
Sheets: {}
};
workbook.Sheets[sheetName] = sheet;
// 生成excel的配置项
let wopts = {
bookType: 'xlsx', // 要生成的文件类型
type: 'buffer'
};
let wbout = XLSX.write(workbook, wopts);
return wbout;
}
说下流程:
利用filter和includes筛选出符合条件的数据 -> 把excel表头和数据拼在一起 -> js数组对象转excel -> excel转流 -> 最后返回文件流并且设置响应头
demo演示
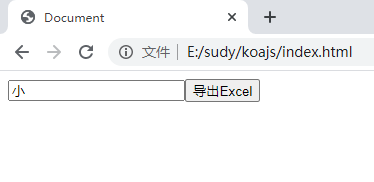
放了个文本框和按钮,点击按钮可以导出:
本文全部源码都在这个demo里,可自行下载使用:
https://gitee.com/cluyun/excelexportdemo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号