ElastiCache for Redis 缓存策略
延迟加载
顾名思义,延迟加载 是一种仅在需要时将数据加载到缓存中的缓存策略。它的工作方式如下所述。
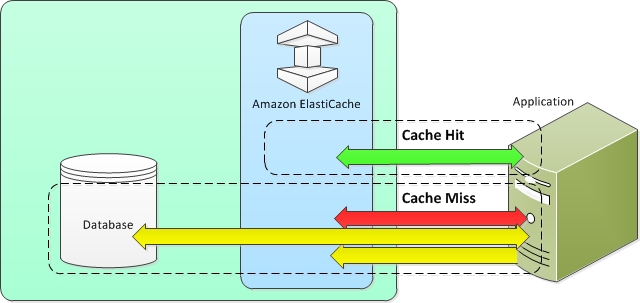
Amazon ElastiCache 是一种内存中键-值存储,位于您的应用程序和其访问的数据存储(数据库)之间。当应用程序请求数据时,它会先向 ElastiCache 缓存发出请求。如果数据在缓存中且最新,则 ElastiCache 会将数据返回到应用程序。如果数据不存在于缓存中或已过期,则应用程序会从数据存储中请求数据。然后,数据存储会将数据返回给应用程序。应用程序接下来将从存储收到的数据写入缓存。这样,下次请求该数据时可以更快速地检索它。
当数据在缓存中且未过期时,会发生缓存命中:
-
应用程序从缓存中请求数据。
-
缓存将数据返回给应用程序。
当数据不在缓存中或已过期时,会发生缓存未命中:
-
应用程序从缓存中请求数据。
-
缓存没有请求的数据,因此返回了
null。 -
应用程序从数据库中请求并接收数据。
-
应用程序使用新数据更新缓存。
下图阐明了这两个过程。
延迟加载的优点和缺点
延迟加载的优点如下:
-
仅对请求的数据进行缓存。
由于大部分数据从未被请求,因此延迟加载避免了向缓存中填入未请求的数据。
-
节点故障对于应用程序而言并不致命。
当某个节点发生故障并由新的空节点替换时,应用程序将继续运行,但延迟会增加。在对新节点发出请求时,每次缓存未命中都会导致对数据库的查询。同时,将数据副本添加到缓存中,以便从缓存中检索后续请求。
延迟加载的缺点如下:
延迟加载伪代码示例
下面是延迟加载逻辑的伪代码示例。
// *****************************************
// function that returns a customer's record.
// Attempts to retrieve the record from the cache.
// If it is retrieved, the record is returned to the application.
// If the record is not retrieved from the cache, it is
// retrieved from the database,
// added to the cache, and
// returned to the application
// *****************************************
get_customer(customer_id)
customer_record = cache.get(customer_id)
if (customer_record == null)
customer_record = db.query("SELECT * FROM Customers WHERE id == {0}", customer_id)
cache.set(customer_id, customer_record)
return customer_record对于此示例,获取数据的应用程序代码如下。
customer_record = get_customer(12345)直写
直写策略会在将数据写入数据库时在缓存中添加或更新数据。
直写的优点和缺点
直写的优点如下:
-
缓存中的数据永不过时。
由于每次将数据写入数据库时都会更新缓存中的数据,因此缓存中的数据始终保持最新。
-
写入性能损失与读取性能损失。
每次写入都涉及两次往返:
-
对缓存进行写入
-
对数据库进行写入
这将增加流程的延迟。即便如此,与检索数据时的延迟相比,最终用户通常更能容忍更新数据时的延迟。有一个内在的意义,即更新的工作量更大,因而花费的时间会更长。
-
直写的缺点如下:
-
缺失的数据。
如果您启动新节点,无论是由于节点故障还是横向扩展,都会存在缺失数据。在数据库上添加或更新数据之前,这些数据一直缺失。您可以通过实施采用直写的延迟加载来最大限度地减少此情况。
-
缓存扰动。
大多数数据永远不会被读取,这是浪费资源。通过添加生存时间 (TTL) 值,您可以最大限度地减少浪费的空间。
直写伪代码示例
下面是直写逻辑的伪代码示例。
// *****************************************
// function that saves a customer's record.
// *****************************************
save_customer(customer_id, values)
customer_record = db.query("UPDATE Customers WHERE id = {0}", customer_id, values)
cache.set(customer_id, customer_record)
return success对于此示例,获取数据的应用程序代码如下。
save_customer(12345,{"address":"123 Main"})添加 TTL
延迟加载允许过时数据,但不会失败并产生空节点。直写可确保数据始终最新,但可能会失败并产生空节点,并且可能向缓存填充过多的数据。通过为每次写入添加生存时间 (TTL) 值,您可以获得每种策略的优点。同时,您可以在很大程度上避免使用额外数据使缓存混乱。
生存时间 (TTL) 是一个整数值,该值指定密钥过期之前的秒数。Redis 可以为此值指定秒数或毫秒数。当应用程序尝试读取过期的密钥时,会将其视为未找到密钥。查询数据库以获取密钥并更新缓存。此方法不保证值不会过时。但它可以确保数据不会变得太陈旧,并且要求不时从数据库刷新缓存中的值。
有关更多信息,请参阅 Redis set 命令 。
TTL 伪代码示例
下面是利用 TTL 的直写逻辑的伪代码示例。
// *****************************************
// function that saves a customer's record.
// The TTL value of 300 means that the record expires
// 300 seconds (5 minutes) after the set command
// and future reads will have to query the database.
// *****************************************
save_customer(customer_id, values)
customer_record = db.query("UPDATE Customers WHERE id = {0}", customer_id, values)
cache.set(customer_id, customer_record, 300)
return success下面是利用 TTL 的延迟加载逻辑的伪代码示例。
// *****************************************
// function that returns a customer's record.
// Attempts to retrieve the record from the cache.
// If it is retrieved, the record is returned to the application.
// If the record is not retrieved from the cache, it is
// retrieved from the database,
// added to the cache, and
// returned to the application.
// The TTL value of 300 means that the record expires
// 300 seconds (5 minutes) after the set command
// and subsequent reads will have to query the database.
// *****************************************
get_customer(customer_id)
customer_record = cache.get(customer_id)
if (customer_record != null)
if (customer_record.TTL < 300)
return customer_record // return the record and exit function
// do this only if the record did not exist in the cache OR
// the TTL was >= 300, i.e., the record in the cache had expired.
customer_record = db.query("SELECT * FROM Customers WHERE id = {0}", customer_id)
cache.set(customer_id, customer_record, 300) // update the cache
return customer_record // return the newly retrieved record and exit function对于此示例,获取数据的应用程序代码如下。
save_customer(12345,{"address":"123 Main"})customer_record = get_customer(12345)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号