
美国版“大众点评”的 Karpenter 迁移实践:如何让每一分钱的效益提升25%?
Yelp 是世界最大的点评网站,功能类似于国内的大众点评。本文由 Yelp 的 SRE 团队撰写,深入探讨他们从自研的 Clusterman 迁移至 AWS Karpenter 的实践历程,包括为何迁移、使用 Clusterman 面临的挑战、Karpenter 的优势以及其迁移策略。
01/Clusterman 及其局限性
Yelp 之前使用 Clusterman 来管理 Kubernetes 集群的弹性伸缩。
Clusterman 最初是一款为 Mesos 集群设计的开源工具,后来我们对其进行了适配 Kubernetes 的改造。
与直接管理整个 Kubernetes 集群不同,Clusterman 主要围绕 “Pool” 进行管理。
每个池由一组 AWS Auto Scaling Group(ASG) 提供支持, 扩缩逻辑基于一个核心配置——设定值(Setpoint),它表示“工作负载请求的资源量”与“集群可配置的总资源量”之间期望的资源预留比例。
Clusterman 通过动态调整 ASG 的期望容量来主动维持这一比例,此外,它还具备安全回收节点、使用自定义信号扩展集群,以及内置模拟器支持不同扩展参数的测试与优化等实用功能。
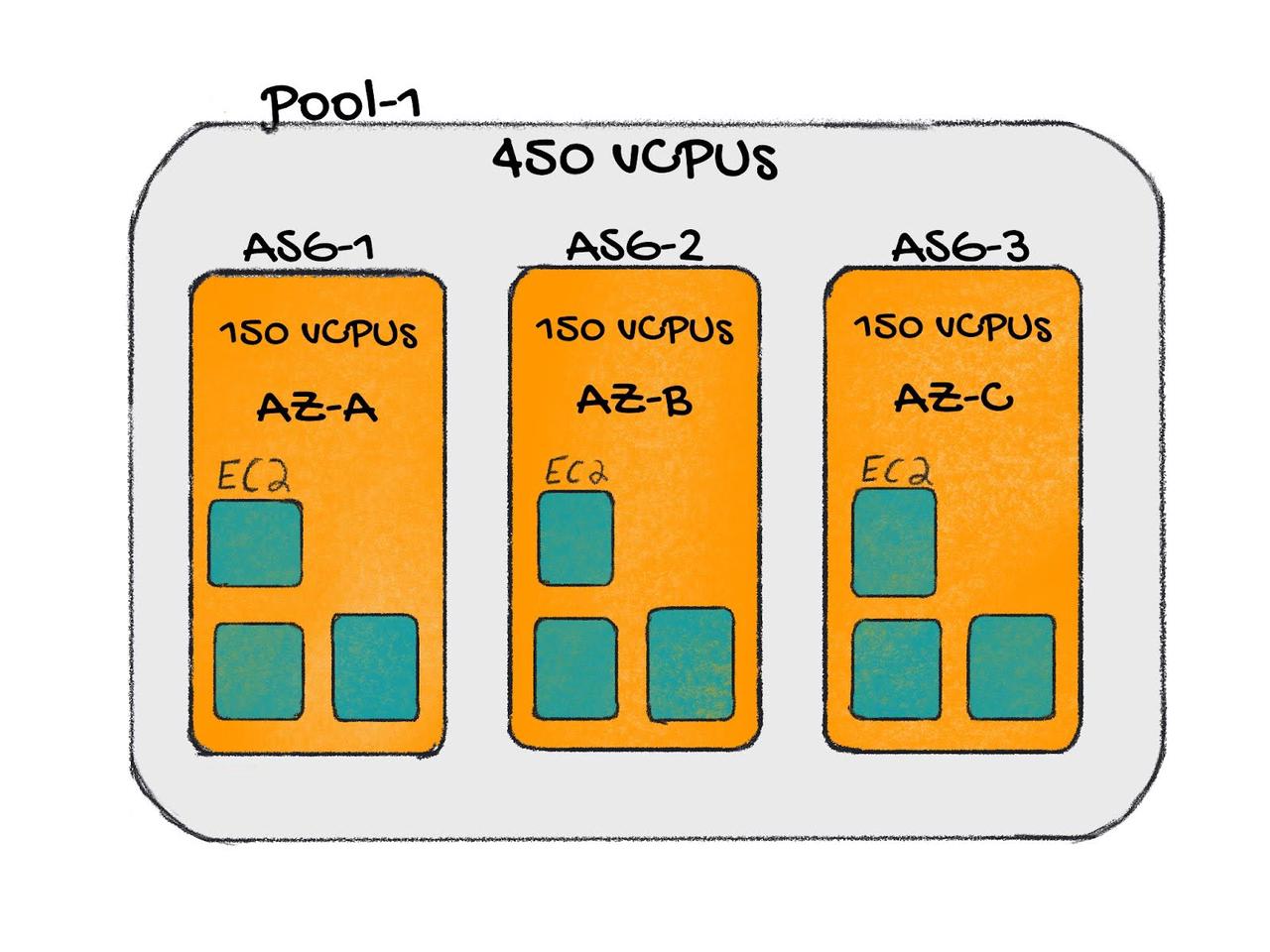
Clusterman的局限性
尽管 Clusterman 具备一定的能力,但它也存在许多局限性。
1. 难以确定最佳设定值
如果集群经常扩缩容,要找到合适的设定值并非易事:
- 设定值较低:可以提高集群稳定性,但会增加运行成本。
- 设定值较高:可能难以维持资源预留比例,影响工作负载的调度。
在 Clusterman 调整设定值的过程中,它有时会删除部分节点(以及这些节点上的 Pod)以优化资源预留比例。
然而,如果资源池中的可用资源不足,这些被删除的 Pod 可能会变得不可调度,进而触发 Clusterman 启动新实例。
这可能会陷入扩缩容的死循环:
- Clusterman 删除节点,以优化资源比例。
- 由于资源不足,部分 Pod 无法调度,触发新实例创建。
- Clusterman 不断尝试平衡集群,导致集群持续扩缩容。
这一循环不仅降低了扩缩容的效率,还导致资源管理复杂化,使得集群难以维持稳定并实现成本优化。
2. 难以满足工作负载的特定需求
Clusterman 依赖 ASG(Auto Scaling Group) 进行弹性扩缩,但它不会主动考虑待调度 Pod 的具体资源需求。
例如,如果某些 Pod 请求特定的 R 系列 EC2 实例,由于缺乏精准匹配能力,ASG 可能无法保证配置正确的实例。
因此,在处理这类特定资源请求时,运维团队通常需要:
- 创建新的资源池(Pool),手动指定 ASG 的实例类型
- 为每个 Pool 额外管理一个 Clusterman 实例
这种管理方式不仅增加了运维工作量,也增加了 Kubernetes 集群的运营成本。
3. 扩展速度受限
Clusterman 采用基于固定时间间隔(X 分钟)的轮询机制来调整集群规模,这导致:
- 难以应对瞬时流量激增,扩展响应较慢。
- 在动态集群环境下表现不佳,影响服务稳定性。
4. 自定义回收策略不够灵活
Clusterman 的节点回收(Recycling) 策略需要修改代码才能自定义。例如,如果想要回收 G5 系列实例,需要手动调整 Clusterman 代码。这种方式不仅增加了维护成本,还降低了在特殊场景下的适配灵活性。
02/寻找替代方案
我们需要什么?
随着 Clusterman 的问题日益凸显,我们开始着手收集在 Kubernetes 上运行工作负载的各团队的意见。
我们发现其中的许多具体需求,都凸显了管理 Clusterman 的负担。这些需求包括:
- 按可用区扩展:能根据待调度 Pod 的存储卷所在的可用区创建新实例。
- 支持不同 GPU 需求:多样化的机器学习工作负载,每种负载对 GPU 的需求不同。
- 满足调度约束:支持拓扑分布约束和亲和性规则,确保 Pods 能够合理分布。
除此之外,我们还有自己的要求:
- 扩缩速度快:做到在几秒内响应待调度 Pod。
- 降低成本:确保在自动扩缩的同时保持成本效益。
Karpenter vs. Cluster Autoscaler
在寻找 Clusterman 替代方案 的过程中,我们重点评估了 Cluster Autoscaler 和 Karpenter 这两个方案。
最终,我们没有选择 Cluster Autoscaler,因为它与 Clusterman 存在类似的问题,难以满足我们的需求,主要原因包括:
-
Node Groups 限制:
Cluster Autoscaler 采用节点组管理模式,要求同一组内的所有节点必须完全相同。 -
难以适配多样化工作负载:
我们的业务涉及不同的计算需求,例如不同 GPU 规格的机器学习任务,这使得 Cluster Autoscaler 难以灵活匹配最合适的实例,无法满足我们的扩缩容需求。
图文对比
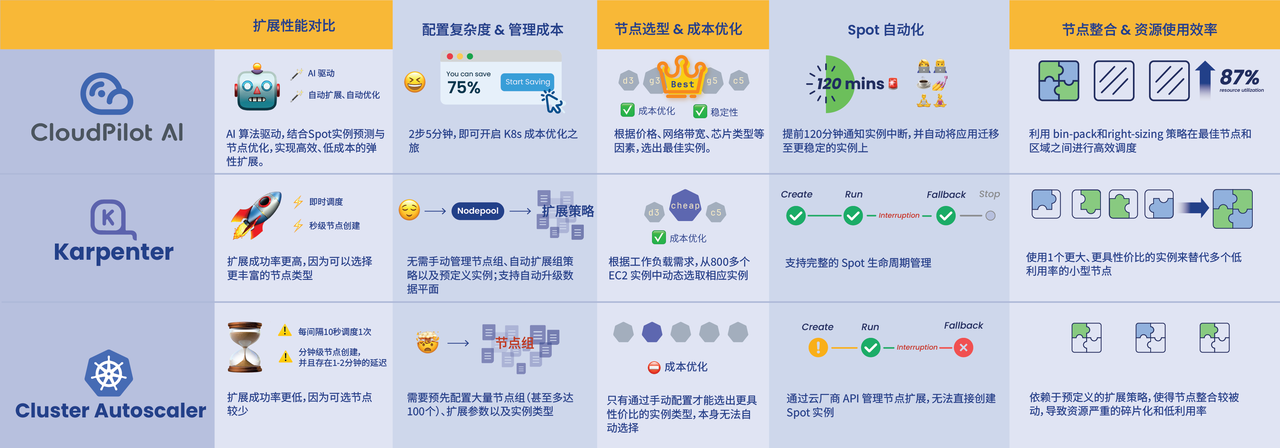
如果你想了解这几款工具的更多技术细节、查看 Karpenter 与 Cluster Autoscaler 的架构差异,回复关键词【对比】,获取完整版 PDF 文件。
03/为什么选择 Karpenter
Karpenter 是一款开源的 Kubernetes 集群自动扩缩容工具,专为优化 Kubernetes 集群的工作负载设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展。
相比 Clusterman,Karpenter 不仅能够根据工作负载需求快速启动实例,还具备诸多关键特性,为我们的基础设施管理带来了显著优化:
1. 更优的 Binpack 调度策略
Clusterman 依赖 ASG 选择实例类型和大小,导致资源利用率较低、成本较高,而 Karpenter 采用更智能的 Binpack 调度策略:
- 批量处理待调度 Pods,在启动实例前先评估所有待调度 Pod 的资源需求,确保实例选择更符合实际负载。
- 动态匹配最优实例类型,提高 CPU 和内存利用率,减少浪费,从而实现更高的资源利用率和成本优化。
2. 兼容 Pool 机制
Karpenter 采用 NodePool 机制,与我们现有的基于池(Pool-Based)的架构兼容。这使得我们可以在不影响现有基础设施的情况下顺利迁移,减少过渡成本。
3. 可自定义节点存活时间
Karpenter 允许用户指定节点存活时间(TTL),在满足 Pod 中断预算约束的前提下,实现定期回收节点,例如:
“请在 10 天后回收这些节点。”
4. 智能成本优化
Karpenter 提供灵活的成本优化机制,帮助我们控制云成本:
✅ 自动删除冗余节点:如果某个节点上的所有 Pods 都可以迁移到其他节点,Karpenter 会自动回收该节点。
✅ 按需实例替换:当有更具成本效益的实例可用时,Karpenter 会自动用更便宜的实例替换现有的按需实例,降低云成本。
✅ 智能合并:Karpenter 可终止多个小实例,转而使用更大的实例,从而提高性价比并减少管理成本。
CloudPilot AI (www.cloudpilot.ai) 对节点选择功能进行智能化升级。在选取实例的过程中,除了价格因素外,还将网络带宽、磁盘 I/O、芯片类型等因素纳入考虑范围内,通过智能算法选出兼顾成本和性能的实例类型,以减少资源浪费,增强应用稳定性。
目前,CloudPilot AI 提供30天免费试用,欢迎尝鲜。
5. 更强的调度能力
Karpenter 自动为节点添加有用的标签,提升工作负载的调度智能化程度。
现在,用户无需为特定的 EC2 需求单独创建新的节点池,只需在 Node Selector 或亲和性规则中指定 EC2 类别(Category)、家族(Family)、代际(Generation)等参数(详见 Well-Known Labels 列表),即可精准匹配合适的计算资源。
6. Spot 实例的自动回退机制
在使用 Clusterman 时,在黑色星期五(Black Friday)这种 Spot 资源紧缺的高峰期,我们通常需要手动调整 ASG 的配置,否则可能导致资源不足。
然而, Karpenter 支持在同一节点池中同时运行 Spot 实例和按需实例,如果某个可用区没有足够的 Spot 容量,它会自动切换到按需实例,无需额外干预。
这一特性帮助我们成功平稳度过了大促期间的高峰需求。
7.实时监控
Karpenter 提供了一整套实用的监控指标,帮助我们深度了解集群的自动伸缩状态和云成本数据。
在过去,调整自动伸缩策略时往往缺乏实时成本指标。借助 Karpenter 的可观测性能力,我们可以更直观地评估不同弹性伸缩配置对成本的实际影响,从而制定更优化的资源管理策略。
选择 Karpenter 后,我们不仅找到了一个能够满足核心需求的解决方案,还获得了一整套强大的工具和功能,帮助我们更从容地应对基础设施管理的不断演进与变化。
04/迁移策略
在从 Clusterman 迁移到 Karpenter 的过程中,我们首先需要考虑的是 Clusterman 对 ASG 的依赖,尤其是它基于属性的实例类型选择机制。
该机制允许用户基于一组实例属性来描述计算需求,而无需手动选择具体的实例类型。由于我们的 ASG 是基于属性的,因此在技术上可以相对顺利地将 ASG 的需求转换为 Karpenter 的 NodePool。
不过,需要注意的是,Karpenter 的 NodePool 并不完全等同于 ASG,某些属性(如 CPU 供应商)无法直接匹配。
在迁移初期,我们曾考虑直接将 ASG 下的节点所有权转移到 Karpenter,以实现无缝过渡。但经过调研,我们发现 Karpenter 并不支持这种方式。
因此,我们采用了一种渐进式迁移方案:逐步缩减 ASG 的容量,让 Clusterman 以较慢的速度删除节点。
虽然节点删除后会导致池内出现不可调度的 Pod,但 Karpenter 能够迅速检测到这些 Pod,并自动扩容,确保所有 Pod 都能顺利调度到新创建的节点上。
这一过渡过程比我们预期的更加顺利,主要得益于我们在迁移前做出的策略性决策。我们在所有工作负载中预先配置了 Pod 中断预算,以防止因主动缩容导致的业务中断。PDB 在整个迁移过程中起到了至关重要的作用,有效降低了迁移带来的潜在风险。
为了实时监控和追踪迁移进度,我们还开发了一套可视化面板,包含以下关键指标:
- ASG 和 Karpenter 容量对比,确保 Karpenter 逐步接管 ASG 负载。
- 每小时资源成本,以便持续监控费用开销。
- Spot 实例中断率,评估实例的稳定性。
- 自动扩缩容成本效率,确保资源利用率最大化。
- 扩缩容事件,分析 Karpenter 运行状态。
- 不可调度 Pod 及其调度时长,确保所有 Pod 都能顺利运行。
- 工作负载错误率,监测迁移期间的服务稳定性。
05/经验总结
Spot 实例的分配策略
在迁移过程中,我们学到的一个重要经验是 Spot 实例的分配策略。
在原有架构中,我们的 ASG 采用的是最低价格分配策略,而 Karpenter 默认使用的是价格-容量优化策略,并且这一策略无法进行自定义配置。
在迁移初期,这种固定策略曾让我们有所顾虑。我们担心 Karpenter 的决策可能会导致成本上升,或者因实例选择的不确定性带来额外成本。
然而,在实际使用过程中,我们的担忧被证明是多余的。Karpenter 不仅显著降低了 Spot 实例的中断率,还在总体上实现了更具成本效益的实例分配,最终带来了更稳定、更经济的计算资源管理方案。
针对 Spot 实例,CloudPilot AI(cloudpilot.ai) 提供全生命周期的智能化运维,包括:
-
提前120分钟发送中断通知:CloudPilot AI 基于机器学习算法预判 Spot 中断风险,预警时效较默认提升60倍,为运维团队赢得从容应对的黄金窗口。
-
无感迁移,保障业务稳定:CloudPilot AI 识别出 Spot 实例即将中断后,无需 DevOps 团队手动操作,自动将应用迁移至稳定实例(既有可能是 Spot 实例,也有可能是按需实例),保障业务稳定运行,同时兼具成本优势。
最终,CloudPilot AI 通过不断学习,持续优化,使得用户环境中的 Spot 实例的中断风险近乎归零。
为关键服务的 HPA 预留缓冲容量
在使用 Clusterman 进行弹性伸缩的过程中,我们发现了一个关键问题:必须确保为关键工作负载预留一定的可用资源。
这些关键工作负载在流量激增时,可能会在短时间内需要扩容更多副本。如果没有预留资源,就可能会导致扩容失败,影响业务连续性。
在 Clusterman 中,我们可以通过调整 Setpoint (即“工作负载请求的资源量”与“集群可配置的总资源量”之间期望的资源预留比例)来解决这个问题。
然而,在迁移到 Karpenter 后,我们发现 Karpenter 并没有内置功能来明确预留可用资源。
为了应对这一挑战,我们采取了一个巧妙的解决方案:运行“占位 Pod”(Dummy Pods),并为其设置特定的 PriorityClass。
PriorityClass 允许 Kubernetes 调度器在有待调度 Pod 无法配置资源时,优先驱逐这些占位 Pod,从而为关键服务的 Horizontal Pod Autoscalers (HPAs) 提供资源。
这种方法有效地保证了高优先级工作负载在扩容时始终有足够的缓冲容量,避免因为资源争抢导致调度失败。
Karpenter 与集群配置实践的对接
在迁移过程中,我们学到了一个重要的教训:必须妥善处理对临时存储(Ephemeral-Storage)需求较高的工作负载。
1. Karpenter 无法自动发现启动模板中的存储配置
在原有架构中,我们使用 ASG 进行节点伸缩,而 ASG 依赖启动模板来获取 EC2 配置(如 AMI-ID、网络、存储等)。
为了满足某些工作负载的高存储需求,我们在启动模板中增加了增加了存储信息(实例根卷大小)。
然而,即使在 Karpenter 配置中指定了启动模板名称,Karpenter 仍然无法识别这些修改,默认所有实例的存储大小均为标准的 17 GB。这导致一些对临时存储需求较高的工作负载一直无法调度。
为了解决这一问题,我们启动了一个评估流程,引入 blockDeviceMappings 机制,在 NodeClass 中显示定义实例的存储大小,使 Karpenter 能够准确获取 EC2 真实的存储配置信息。
2. Karpenter 无法识别 NVMe 本地存储
由于 Flink 工作负载需要快速且大规模的存储操作,我们选择了带有本地 NVMe SSD 块级存储的 EC2 实例(例如 c6id、m6id 等)。然而,Karpenter 无法将这些本地 SSD 存储识别为 Pod 的临时存储,阻碍了 Flink 任务池的迁移。
幸运的是,Karpenter 官方团队在新版本中引入了 instanceStorePolicy 机制,支持对本地存储的识别和调度,从而彻底解决了这一问题。
3. Karpenter 无法感知 Kubelet 相关配置
迁移过程中另一个值得注意的方面是,我们发现 Karpenter 并未原生感知到我们的 kubelet 设置,这些设置位于我们的配置管理系统中。
例如,我们使用 system-reserved 配置指定了 2 个 vCPU 和 4 GB 内存应保留给系统进程。但是 Karpenter 对这些自定义 kubelet 配置一无所知,导致资源分配出现偏差。
此外,我们的 Max-Pods 设置与 Karpenter 的内部计算也存在差异。配置管理系统和 Karpenter 对这些设置的解释方式之间的细微差别,凸显了外部配置与 Karpenter 资源管理算法之间需要更无缝的集成。
这一经验让我们意识到,要充分发挥 Karpenter 的调度能力,必须确保其能够正确解析并理解集群的配置逻辑。
通过遵循 Karpenter 的原生配置方式,确保其充分理解工作负载需求和底层资源情况,它才能高效地管理和调度集群资源,实现更稳定、更具成本效益的自动伸缩。
06/性能与可扩展性
Karpenter 在性能上远超 Clusterman,核心区别在于资源监控方式的不同。
-
Clusterman 依赖周期性检查(最短间隔 1 分钟),这导致其在检测和响应无法调度的 Pod 时存在一定的滞后。
-
Karpenter 基于 Kubernetes 事件驱动机制,能够实时感知并响应无法调度的 Pod(通常仅需几秒)。这种事件驱动模型大幅提升了性能,使得 Karpenter 在实现自动扩缩容时更加灵活高效。

Karpenter 不仅在性能上优于 Clusterman,在可扩展性方面也更胜一筹。
-
Clusterman 依赖内存密集型的架构,会存储所有 Pod 和节点的信息,随着集群规模的增长,容易遭遇内存溢出(OOM)问题,从而影响其扩缩能力。
-
而 Karpenter 仅存储必要的信息,并避免直接从 kube-apiserver 读取所有资源,从根本上规避了性能瓶颈,因此更适用于大规模 Kubernetes 集群。
此外,为了跟踪迁移过程中的云成本优化,我们在增加了支出效率(Spending Efficiency)这一新指标,该指标衡量的是运行单位资源(CPU/内存)的成本。
最终,Karpenter 使我们的支出效率平均提升了 25%,进一步验证了其在资源利用率和成本优化方面的优势。
07/结论
最初,Clusterman 对于 Yelp 来说是最优且实用的自动伸缩解决方案,特别是在我们从 Mesos 迁移到 Kubernetes 的过程中。
当时,我们决定扩展 Clusterman 的功能,使其不仅支持 Mesos,还能管理 Kubernetes 的扩缩容需求,这一策略大大简化了迁移过程,并使 Clusterman 成为唯一支持 Mesos 和 Kubernetes 的开源弹性扩缩工具。
然而,随着我们全面转向 Kubernetes,Clusterman 的维护成本逐渐增加,并且缺少一些关键特性,无法满足当前的工作负载需求。
与此同时,更先进的开源自动弹性伸缩工具(如 Karpenter)已经问世,不仅提供了更丰富的功能,而且对 Kubernetes 生态的支持也更加完善。因此,我们选择从 Clusterman 迁移至 Karpenter,以提升集群的弹性效率和资源管理能力。
推荐阅读
弹性工具选Karpenter还是Cluster Autoscaler?看这篇就知道啦!
posted on 2025-03-26 17:34 CloudPilotAI 阅读(177) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号