
一文消除大数据处理的资源浪费,实现 90% 成本降低
本文介绍如何通过 Karpenter 动态调度阿里云 Spot 实例运行 Spark 作业,实现 90%+ 成本节省。
涵盖集群搭建、Spark Operator/Karpenter 部署、Executor 弹性扩缩配置及效果验证,提供完整代码示例。
阅读时间约 10 分钟(技术细节较多,含代码及配置步骤)。
Apache Spark 是⼀个专门为大规模数据处理设计的计算引擎,广泛应用于数据分析和机器学习等场景。随着 Spark 处理数据量的指数级增长,传统的固定资源池模式面临 30-50% 的资源浪费,主要源于 Executor 空置、机型不匹配等问题。
为了解决这⼀问题,业内开始引⼊ Karpenter ⸺⼀个 Kubernetes 原生的弹性扩缩容控制器,通过以下核心能力有效实现成本优化:
- 智能调度算法:实时分析 Pod 资源需求,⾃动选择最优机型组合(如 Spot 实例、高性价比机型)
- 秒级弹性伸缩:作业启动时 40~45 秒内完成节点供给,作业结束后自动回收资源
- 碎片化资源整合:将分散的⼩资源请求聚合到⼤节点,提升整体利⽤率至 85%+
为什么选择 Karpenter?

Karpenter 是 Kubernetes 生态中开源的弹性扩缩容控制器,专为提升资源利用率和降低调度延迟设计。
它通过实时监测集群中 Pending 状态的 Pod 资源需求,智能决策最优节点规格并自动创建/回收实例,40-45 秒内即可完成资源供给(相比 Cluster Autoscaler 分钟级响应)。
特别适合 Spark 等批处理场景,支持动态扩展 Executor 节点池,结合 Spot 实例智能选择最优机型,实现 90%+ 资源成本节省和碎⽚化资源整合。
Spark + Karpenter 的降本实践
1. 创建⼀个集群(以阿里云举例, 已有可跳过)
Karpenter 云⼚商适配现状:https://github.com/kubernetes-sigs/karpenter?tab=readme-ov-file#karpenter-implementations
1.1 Terraform Create Cluster
创建云上 K8s 集群
aliyun configure
export ALICLOUD_ACCESS_KEY=<aliyun access key>
export ALICLOUD_SECRET_KEY=<aliyun secret key>
export ALICLOUD_REGION="cn-shenzhen"
git clone https://github.com/cloudpilot-ai/examples.git
cd examples/clusters/ack-spot-flannel
export TF_VAR_CLUSTER_NAME=<your_cluster_name>
terraform init
terraform apply --auto-approve
获取集群 kubeconfig
export CLUSTER_NAME=<your_cluster_name>
export KUBECONFIG=~/.kube/demo
export CLUSTER_ID=$(aliyun cs GET /clusters | jq -r --arg CLUSTER_NAME
"$CLUSTER_NAME" '.[] | select(.name == $CLUSTER_NAME) | .cluster_id')
aliyun cs GET /k8s/$CLUSTER_ID/user_config | jq -r '.config' > $KUBECONFIG
1.2 检查集群状态
kubectl get node
NAME STATUS ROLES AGE VERSION
cn-shenzhen.172.16.1.159 Ready <none> 32m v1.31.1-aliyun.1
cn-shenzhen.172.16.2.181 Ready <none> 32m v1.31.1-aliyun.1
2. 部署 Spark Operator
Spark Operator 提供了在 Kubernetes 集群中自动化部署和管理 Spark 作业生命周期的功能。
2.1 安装 Spark Operator
# Add the Helm repository
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
# Install the operator into the spark-operator namespace and wait for
deployments to be ready
helm install spark-operator spark-operator/spark-operator \
--namespace spark-operator --create-namespace --wait
请注意:Spark History Server 也需要安装,尽管未在此处单独列出。
2.2 测试 Spark
# Create an example application in the default namespace
kubectl apply -f https://raw.githubusercontent.com/kubeflow/sparkoperator/refs/heads/master/examples/spark-pi.yaml
# Get the status of the application
kubectl get sparkapp spark-pi
3. 部署 Karpenter (Karpenter-Provider-Alibabacloud)
- 配置环境变量
export CLUSTER_NAME=<your_cluster_name> # Config your cluster
name
export CLUSTER_REGION=<your_cluster_region> # Config the
alibabacloud region
export ALIBABACLOUD_AK=<alibaba_cloud_access_key> # Config the
alibabacloud AK
export ALIBABACLOUD_SK=<alibaba_cloud_secret_key> # Config the
alibabacloud SK
export CLUSTER_ID=$(aliyun cs GET /clusters | jq -r --arg CLUSTER_NAME
"$CLUSTER_NAME" '.[] | select(.name == $CLUSTER_NAME) | .cluster_id')
export VSWITCH_IDS=$(aliyun cs GET /api/v1/clusters --header "ContentType=application/json;" | jq -r --arg CLUSTER_NAME "$CLUSTER_NAME"
'.clusters[] | select(.name == $CLUSTER_NAME) | .vswitch_ids[]')
export SECURITYGROUP_ID=$(aliyun cs GET /api/v1/clusters --header "ContentType=application/json;" | jq -r --arg CLUSTER_NAME "$CLUSTER_NAME"
'.clusters[] | select(.name == $CLUSTER_NAME) | .security_group_id')
- Tag 安全组和 vSwitch
# Tag the security group
aliyun tag TagResources --region ${CLUSTER_REGION} --RegionId
${CLUSTER_REGION} --ResourceARN.1
"acs:ecs:*:*:securitygroup/${SECURITYGROUP_ID}" --Tags "
{"karpenter.sh/discovery": "$CLUSTER_NAME"}"
# Tag the vswitch
IFS=' '
while IFS= read -r vs_id; do
aliyun tag TagResources --region ${CLUSTER_REGION} --RegionId
${CLUSTER_REGION} --ResourceARN.1 "acs:vpc:*:*:vswitch/${vs_id}" --Tags "
{"karpenter.sh/discovery": "$CLUSTER_NAME"}"
done <<< "$VSWITCH_IDS"
- 安装 Karpenter
helm repo add karpenter-provider-alibabacloud https://cloudpilot-ai.github.io/karpenter-provider-alibabacloud
helm upgrade karpenter karpenter-provider-alibabacloud/karpenter --install --version 0.1.4 \
--namespace karpenter-system --create-namespace \
--set "alibabacloud.access_key_id"=${ALIBABACLOUD_AK} \
--set "alibabacloud.access_key_secret"=${ALIBABACLOUD_SK} \
--set "alibabacloud.region_id"=${CLUSTER_REGION} \
--set controller.settings.clusterID=${CLUSTER_ID} \
--wait
- 创建 NodePool/ECSNodeClass
还可通过 nodepool 指定 instance-family 的⽅式,调度出所期望的不同规格实例类型(如下注释部分)。
cat > nodeclass.yaml <<EOF
apiVersion: karpenter.k8s.alibabacloud/v1alpha1
kind: ECSNodeClass
metadata:
name: defaultnodeclass
spec:
vSwitchSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
imageSelectorTerms:
# ContainerOS only support x86_64 linux nodes, and it's faster to initialize
- alias: ContainerOS
systemDisk:
categories:
- cloud_auto
performanceLevel: PL0
size: 20
EOF
kubectl apply -f nodeclass.yaml
cat > nodepool.yaml <<EOF
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: ecsnodepool
spec:
disruption:
budgets:
- nodes: 95%
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
template:
spec:
requirements:
# - key: karpenter.k8s.alibabacloud/instance-family
# operator: In
# values: [ "ecs.g5" ]
- key: kubernetes.io/arch
operator: In
values: [ "amd64" ]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
nodeClassRef:
group: "karpenter.k8s.alibabacloud"
kind: ECSNodeClass
name: defaultnodeclass
EOF
kubectl apply -f nodepool.yaml
4. 测试 Spark 作业弹性运行
4.1 修改 Spark-pi
为了最大程度降低运行成本,同时确保稳定性,将 driver 运行在 On-Demand 节点,Executor 运行在 Spot 节点。如下为具体原因:
1.Driver 的重要性与稳定性要求****
Driver 是 Spark 作业的核心,负责协调整个作业的执行,向 Executors 分配任务,监控任务执行状态,并且最终收集和输出结果。
如果 driver 运行在 Spot Instances 上,可能会在实例被中断时导致整个 Spark 作业失败或需要重新启动。
由于 Spot Instances 可能会被回收,因此 driver 的稳定性至关重要,为了防止作业因为 Spot 实例中断而失败,通常会将 driver 部署在 On-Demand Instances 上。
2.Executor 的容错性和弹性
Executor 是负责执行实际计算任务的工作单元,它们可以在作业执行期间动态启动和停止。
虽然 Spot Instances 具有较高的中断风险,但它们通常比 On-Demand Instances 便宜,适合用来处理计算密集型任务。如果⼀个 Executor 在 Spot Instance 上被回收,Spark 会自动将任务重新调度到其他 Executor。
这种容错机制保证了即使某些 Spot Instances 被中断,作业依然能够继续执行,因此在 Spot Instances 上运行 Executors 是可行的。
通过节点亲和性策略实现 Driver/Executor 差异化节点弹性&调度:
spec:
arguments:
- "5000"
deps: {}
driver:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: NotIn
values:
- spot
cores: 1
labels:
version: 3.5.3
memory: 512m
serviceAccount: spark-operator-spark
executor:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
cores: 1
instances: 20
labels:
version: 3.5.3
memory: 512m
4.2 查看 Karpenter 创建节点情况
kubectl get nodeclaim
NAME TYPE CAPACITY ZONE NODE READY AGE
ecsnodepool-n6b5h ecs.e-c1m2.2xlarge spot cn-shenzhen-f cn-shenzhen.172.16.4.94 True 55s
ecsnodepool-q4w5l ecs.u1-c1m2.4xlarge spot cn-shenzhen-f cn-shenzhen.172.16.4.95 True 45s
4.3 等待 Spark 作业运行结束
kubectl get sparkapplications spark-pi
NAME STATUS ATTEMPTS START FINISH AGE
spark-pi COMPLETED 1 2025-02-20T10:24:14Z 2025-02-20T10:26:18Z 45m
4.4 Instance 成本
本次 Spark 作业中,Karpenter 根据 Executor 资源需求自动创建 2 个 Spot 实例节点 (规格:ecs.ec1m2.2xlarge/ecs.u1-c1m2.4xlarge),作业完成后自动回收节点,避免资源闲置。
通过对比实验:
- Spot 实例成本:仅为按需实例的 10-30%(参见实时价格截图)
- 总成本对比:相比传统 Cluster Autoscaler 方案,Karpenter 通过机型选择算法 +碎片化资源整合,综合成本降低 80%+
- 包年包⽉场景:若原有集群采⽤固定资源,改用 Karpenter 弹性架构后,闲置时段资源归零,预估可再降低 40-60% 长期⽀出。
下方图片显示了 ecs.e-c1m2.2xlarge 及 ecs.u1-c1m2.4xlarge 的实时价格。

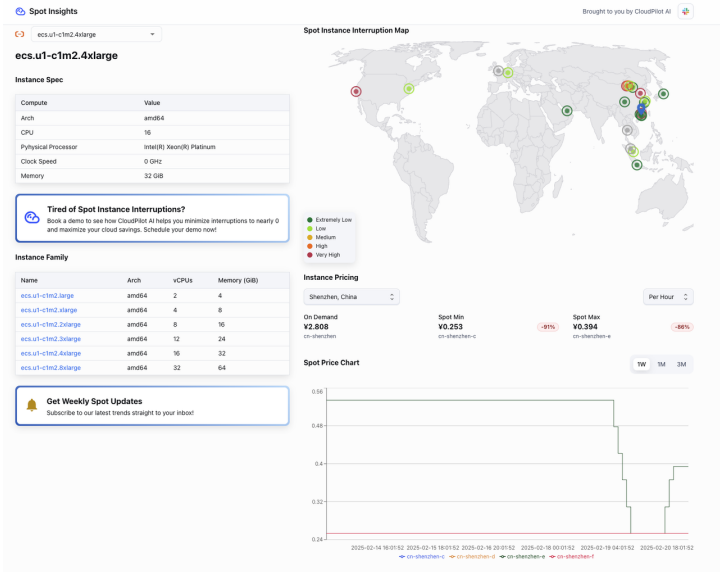
截取自 Spot 查询工具 Spot Insights(spot.cloudpilot.ai),目前支持阿里云和 AWS Spot 实例价格和中断率查询,欢迎访问!
5. (可选) 删除 Spark 作业
kubectl delete -f https://raw.githubusercontent.com/kubeflow/sparkoperator/refs/heads/master/examples/spark-pi.yaml
6. (可选) 卸载 Karpenter
helm uninstall karpenter --namespace karpenter-system
kubectl delete ns karpenter-system
总结
本⽂展示了如何将 Spark 作业与 Karpenter 相结合,通过动态调度阿里云 Spot 实例,实现超过 90% 的显著成本节省。我们详细探讨了从集群搭建、Spark Operator 部署、Karpenter 配置,到 Spark 作业弹性伸缩及成本优化的全过程。
通过具体的部署步骤和配置示例,展⽰了在 Kubernetes 环境中如何最⼤化利用 Kapenter 的弹性扩缩容能力,优化资源使⽤,并有效降低计算成本。这为重度使用 Spark 的企业提供了⼀种高效、经济的云计算解决方法。
相关开源项目(期待 Star):
- https://github.com/cloudpilot-ai/karpenter-provider-alibabacloud
- https://github.com/kubernetes-sigs/karpenter
推荐阅读
弹性工具选Karpenter还是Cluster Autoscaler?看这篇就知道啦!
posted on 2025-02-27 12:30 CloudPilotAI 阅读(158) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号