
kubeadm部署1.17.3[基于Ubuntu18.04]
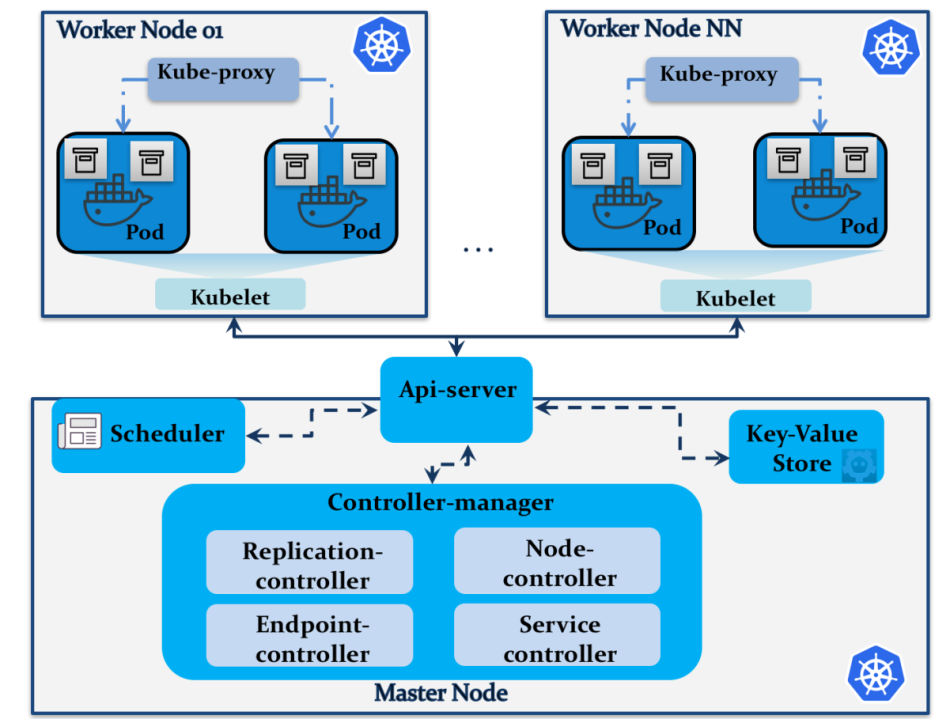
基于 Ubuntu18.04 使用 kubeadm 部署Kubernetes 1.17.3 高可用集群
环境
所有节点初始化
# cat <<EOF>> /etc/hosts
192.168.1.210 k8s-m1
192.168.1.211 k8s-node1
192.168.1.212 k8s-node2
EOF
# vm1
hostnamectl set-hostname k8s-m1
# vm2
hostnamectl set-hostname k8s-node1
# vm3
hostnamectl set-hostname k8s-node2
# 关闭Swap
swapoff -a && sysctl -w vm.swappiness=0
# 注释 fstab 中Swap 配置
sed -i 's/.*swap.*/#&/' /etc/fstab
cat /etc/fstab
# 设置路由转发以及bridge的数据进行处理
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
ls /proc/sys/net/bridge
# 资源配置文件
cat <<EOF >> /etc/security/limits.conf
* soft nofile 51200
* hard nofile 51200
EOF
cat <<EOF >> /etc/pam.d/common-session
session required pam_limits.so
EOF
echo "ulimit -SHn 51200" >> /etc/profile
# 修改时区
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0
# 所有节点创建相关目录
mkdir -p /opt/k8s/{bin,work} /etc/{kubernetes,etcd}/cert
cd /opt/k8s/bin/
# 环境变量
cat <<EOF >> environment.sh
#!/usr/bin/bash
# 集群各机器 IP 数组
export NODE_IPS=(192.168.1.210 192.168.1.211 192.168.1.212)
# 集群各 IP 对应的主机名数组
export NODE_NAMES=(k8s-m1 k8s-node1 k8s-node2)
# etcd 集群服务地址列表
export ETCD_ENDPOINTS="https://192.168.1.210:2379,https://192.168.1.211:2379,https://192.168.1.212:2379"
# etcd 集群间通信的 IP 和端口
export ETCD_NODES="k8s-m1=https://192.168.1.210:2380,k8s-node1=https://192.168.1.211:2380,k8s-node2=https://192.168.1.212:2380"
# kube-apiserver 的反向代理地址端口
export KUBE_APISERVER="https://192.168.1.213:16443"
# etcd 数据目录
export ETCD_DATA_DIR="/data/k8s/etcd/data"
# etcd WAL 目录,建议是 SSD 磁盘分区,或者和 ETCD_DATA_DIR 不同的磁盘分区
export ETCD_WAL_DIR="/data/k8s/etcd/wal"
# k8s 各组件数据目录
export K8S_DIR="/data/k8s/k8s"
EOF
安装Docker 19.03
# 安装基础组件
apt update && apt install -y apt-transport-https software-properties-common ntp ntpdate
# 添加源
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 更新
apt update
# 列出当前安装Docker版本
apt-cache madison docker-ce
# 安装指定版本 19.03.7
apt install docker-ce=5:19.03.7~3-0~ubuntu-bionic
配置docker使用systemd
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
systemctl daemon-reload
systemctl restart docker
指定版本1.17.3安装kubeadm/kubelet/kubectl
curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt install kubernetes-cni
apt --fix-broken install
## 安装指定版本1.17.2安装kubeadm kubelet kubectl
dpkg -i http://mirrors.aliyun.com/kubernetes/apt/pool/kubeadm_1.17.3-00_amd64_a993cfe07313b10cb69c3d0a680fdc0f6f3976e226d5fe3d062be0cea265274c.deb
dpkg -i http://mirrors.aliyun.com/kubernetes/apt/pool/kubelet_1.17.3-00_amd64_f0b930ce4160af585fb10dc8e4f76747a60f04b6343c45405afbe79d380ae41f.deb
dpkg -i http://mirrors.aliyun.com/kubernetes/apt/pool/kubectl_1.17.3-00_amd64_289913506f67535270a8ab4d9b30e6ece825440bc00a225295915741946c7bc6.deb
###
apt-mark hold kubelet kubeadm kubectl docker-ce
启用ipvs模块
apt install ipvsadm ipset -y
# ipvs作为kube-proxy的转发机制,开启ipvs模块支持
modprobe ip_vs && modprobe ip_vs_rr && modprobe ip_vs_wrr && modprobe ip_vs_sh
# 开机启用的ipvs
cat <<EOF >> /etc/modules
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs
EOF
创建证书
sudo mkdir -p /opt/k8s/cert && cd /opt/k8s/work
wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssl_1.4.1_linux_amd64
mv cfssl_1.4.1_linux_amd64 /opt/k8s/bin/cfssl
wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssljson_1.4.1_linux_amd64
mv cfssljson_1.4.1_linux_amd64 /opt/k8s/bin/cfssljson
wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssl-certinfo_1.4.1_linux_amd64
mv cfssl-certinfo_1.4.1_linux_amd64 /opt/k8s/bin/cfssl-certinfo
chmod +x /opt/k8s/bin/*
export PATH=/opt/k8s/bin:$PATH
# CA 配置文件用于配置根证书
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "876000h"
}
}
}
}
EOF
# signing:表示该证书可用于签名其它证书(生成的 ca.pem 证书中 CA=TRUE);
# server auth:表示 client 可以用该该证书对 server 提供的证书进行验证;
# client auth:表示 server 可以用该该证书对 client 提供的证书进行验证;
# "expiry": "876000h":证书有效期设置为 100 年;
# 创建证书签名请求文件
cat >> ca-csr.json <<EOF
{
"CN": "kubernetes-ca",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "opsnull"
}
],
"ca": {
"expiry": "876000h"
}
}
EOF
# CN:Common Name:kube-apiserver 从证书中提取该字段作为请求的用户名 (User Name),浏览器使用该字段验证网站是否合法;
# O:Organization:kube-apiserver 从证书中提取该字段作为请求用户所属的组 (Group);
# kube-apiserver 将提取的 User、Group 作为 RBAC 授权的用户标识;
# 注意:
# 不同证书 csr 文件的 CN、C、ST、L、O、OU 组合必须不同,否则可能出现 PEER'S CERTIFICATE HAS AN INVALID SIGNATURE 错误;
# 后续创建证书的 csr 文件时,CN 都不相同(C、ST、L、O、OU 相同),以达到区分的目的;
# 生成证书文件和私钥
cd /opt/k8s/work
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
ls ca*
# 分发证书文件
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /etc/kubernetes/cert"
scp ca*.pem ca-config.json root@${node_ip}:/etc/kubernetes/cert
done
安装etcd集群
# 下载和分发 etcd 二进制文件 ,到 etcd 的 relase 页面下载最新的版本。
cd /opt/k8s/work
wget https://github.com/coreos/etcd/releases/download/v3.4.5/etcd-v3.4.5-linux-amd64.tar.gz
tar -xvf etcd-v3.4.5-linux-amd64.tar.gz
# 分发二进制文件到集群所有节点:
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
scp etcd-v3.4.5-linux-amd64/etcd* root@${node_ip}:/opt/k8s/bin
ssh root@${node_ip} "chmod +x /opt/k8s/bin/*"
done
# 创建 etcd 证书和私钥
# 创建证书签名请求:
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.1.210",
"192.168.1.211",
"192.168.1.212"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "opsnull"
}
]
}
EOF
# O: system:masters:kube-apiserver 收到使用该证书的客户端请求后,为请求添加组(Group)认证标识 system:masters;
# 预定义的 ClusterRoleBinding cluster-admin 将 Group system:masters 与 Role cluster-admin 绑定,该 Role 授予操作集群所需的最高权限;
# 该证书只会被 kubectl 当做 client 证书使用,所以 hosts 字段为空;
# 生成证书和私钥:
cfssl gencert -ca=/opt/k8s/work/ca.pem \
-ca-key=/opt/k8s/work/ca-key.pem \
-config=/opt/k8s/work/ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
# 分发生成的证书和私钥到各 etcd 节点:
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p /etc/etcd/cert"
scp etcd*.pem root@${node_ip}:/etc/etcd/cert/
done
# 创建 etcd 的 systemd unit 模板文件
cat > etcd.service.template <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=${ETCD_DATA_DIR}
ExecStart=/opt/k8s/bin/etcd \\
--data-dir=${ETCD_DATA_DIR} \\
--wal-dir=${ETCD_WAL_DIR} \\
--name=##NODE_NAME## \\
--cert-file=/etc/etcd/cert/etcd.pem \\
--key-file=/etc/etcd/cert/etcd-key.pem \\
--trusted-ca-file=/etc/kubernetes/cert/ca.pem \\
--peer-cert-file=/etc/etcd/cert/etcd.pem \\
--peer-key-file=/etc/etcd/cert/etcd-key.pem \\
--peer-trusted-ca-file=/etc/kubernetes/cert/ca.pem \\
--peer-client-cert-auth \\
--client-cert-auth \\
--listen-peer-urls=https://##NODE_IP##:2380 \\
--initial-advertise-peer-urls=https://##NODE_IP##:2380 \\
--listen-client-urls=https://##NODE_IP##:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://##NODE_IP##:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=${ETCD_NODES} \\
--initial-cluster-state=new \\
--auto-compaction-mode=periodic \\
--auto-compaction-retention=1 \\
--max-request-bytes=33554432 \\
--quota-backend-bytes=6442450944 \\
--heartbeat-interval=250 \\
--election-timeout=2000
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# WorkingDirectory、--data-dir:指定工作目录和数据目录为 ${ETCD_DATA_DIR},需在启动服务前创建这个目录;
# --wal-dir:指定 wal 目录,为了提高性能,一般使用 SSD 或者和 --data-dir 不同的磁盘;
# --name:指定节点名称,当 --initial-cluster-state 值为 new 时,--name 的参数值必须位于 --initial-cluster 列表中;
# --cert-file、--key-file:etcd server 与 client 通信时使用的证书和私钥;
# --trusted-ca-file:签名 client 证书的 CA 证书,用于验证 client 证书;
# --peer-cert-file、--peer-key-file:etcd 与 peer 通信使用的证书和私钥;
# --peer-trusted-ca-file:签名 peer 证书的 CA 证书,用于验证 peer 证书;
# 创建各个节点的etcd.service
source /opt/k8s/bin/environment.sh
for (( i=0; i < 3; i++ ))
do
sed -e "s/##NODE_NAME##/${NODE_NAMES[i]}/" -e "s/##NODE_IP##/${NODE_IPS[i]}/" etcd.service.template > etcd-${NODE_IPS[i]}.service
done
ls *.service
# NODE_NAMES 和 NODE_IPS 为相同长度的 bash 数组,分别为节点名称和对应的 IP;
# 分发生成的 systemd unit 文件:
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
scp etcd-${node_ip}.service root@${node_ip}:/etc/systemd/system/etcd.service
done
# 启动 etcd 服务
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "mkdir -p ${ETCD_DATA_DIR} ${ETCD_WAL_DIR}"
ssh root@${node_ip} "systemctl daemon-reload && systemctl enable etcd && systemctl restart etcd " &
done
# 必须先创建 etcd 数据目录和工作目录;
# etcd 进程首次启动时会等待其它节点的 etcd 加入集群,命令 systemctl start etcd 会卡住一段时间,为正常现象
# 检查启动结果
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
ssh root@${node_ip} "systemctl status etcd|grep Active"
done
# 确保状态为 active (running),否则查看日志,确认原因:
journalctl -u etcd
# 验证服务状态
# 部署完 etcd 集群后,在任一 etcd 节点上执行如下命令:
source /opt/k8s/bin/environment.sh
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
/opt/k8s/bin/etcdctl \
--endpoints=https://${node_ip}:2379 \
--cacert=/etc/kubernetes/cert/ca.pem \
--cert=/etc/etcd/cert/etcd.pem \
--key=/etc/etcd/cert/etcd-key.pem endpoint health
done
# 预计输出:
>>> 192.168.1.210
https://192.168.1.210:2379 is healthy: successfully committed proposal: took = 36.897441ms
>>> 192.168.1.211
https://192.168.1.211:2379 is healthy: successfully committed proposal: took = 32.27599ms
>>> 192.168.1.212
https://192.168.1.212:2379 is healthy: successfully committed proposal: took = 33.600849ms
# 输出均为 healthy 时表示集群服务正常。
# 查看当前 leader
source /opt/k8s/bin/environment.sh
/opt/k8s/bin/etcdctl \
-w table --cacert=/etc/kubernetes/cert/ca.pem \
--cert=/etc/etcd/cert/etcd.pem \
--key=/etc/etcd/cert/etcd-key.pem \
--endpoints=${ETCD_ENDPOINTS} endpoint status
# output
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.1.210:2379 | d5740bc3edef9ec9 | 3.4.5 | 20 kB | true | false | 2 | 8 | 8 | |
| https://192.168.1.211:2379 | 31a320d3d5b93e94 | 3.4.5 | 20 kB | false | false | 2 | 8 | 8 | |
| https://192.168.1.212:2379 | 3fea22316cddd69a | 3.4.5 | 20 kB | false | false | 2 | 8 | 8 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
# leader 为 192.168.1.210
部署LB的ApiServer
# 各个节点安装
apt install -y keepalived haproxy
# 创建keepalived配置文件
cat > /etc/keepalived/keepalived.conf << EOF
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 250
advert_int 1
authentication {
auth_type PASS
auth_pass 2bba93d43c4495e0
}
virtual_ipaddress {
192.168.1.213
}
track_script {
check_haproxy
}
}
EOF
# killall -0 haproxy : 根据进程名称检测进程是否存活
# interface : VIP 绑定到的网卡名
# virtual_ipaddress : 虚拟的 VIP
# state : master-1节点为MASTER,其余节点(master-2和master-3)为BACKUP
# priority : 各个节点优先级相差50(直接设置相同,效果相同),范围:0~250(非强制要求)
# 设置开机启动并检测 keepalived 状态
systemctl enable keepalived.service
systemctl start keepalived.service
systemctl status keepalived.service
# 验证VIP是否生效
ip address show
# 添加hosts解析
echo "192.168.1.213 daemon.k8s.io">> /etc/hosts
# 创建haproxy配置文件
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server k8s-m1 192.168.1.210:6443 check
server k8s-node1 192.168.1.211:6443 check
server k8s-node2 192.168.1.212:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
# 只需要修改 server 即可
# haproxy 配置在其他 master 节点上相同
# 设置开机启动并检测 haproxy 状态
systemctl enable haproxy.service
systemctl start haproxy.service
systemctl status haproxy.service\
# 查看监听端口
netstat -anlt|grep -E "1080|16443"
使用 kubeadm 部署集群
# 创建 kubeadm-config.yaml 初始化配置文件
cat > kubeadm-config.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.17.3
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
controlPlaneEndpoint: "daemon.k8s.io:16443"
apiServer:
certSANs:
- daemon.k8s.io
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
networking:
dnsDomain: cluster.local
podSubnet: 10.240.0.0/16
serviceSubnet: 172.16.0.0/16
etcd:
external:
endpoints:
- https://192.168.1.210:2379
- https://192.168.1.211:2379
- https://192.168.1.212:2379
caFile: /etc/kubernetes/cert/ca.pem
certFile: /etc/etcd/cert/etcd.pem
keyFile: /etc/etcd/cert/etcd-key.pem
EOF
# 配置说明:
- kubernetesVersion: kubernetes 的版本号
- imageRepository: 镜像仓库,因为gcr.io 被墙,所以改用阿里云的镜像仓库
- controlPlaneEndpoint: 控制平面的端点,即为访问 apiserver 的地址
- podSubnet: pod 的地址池
- serviceSubnet: svc 的地址池
# 初始化命令
kubeadm init --config kubeadm-config.yaml
# output
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
# 配置 kubectl 的 config
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
# 其他 master 节点上进行初始化的命令
kubeadm join daemon.k8s.io:16443 --token o6cd4a.gvbrz7zioaykb8ma \
--discovery-token-ca-cert-hash sha256:5321fe113e21db8ffd0e8c81748e66b1c565abd3xxxxxx \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
# 在其它 node 节点上进行初始化的命令。
kubeadm join daemon.k8s.io:16443 --token o6cd4a.gvbrz7zixxxxx \
--discovery-token-ca-cert-hash sha256:5321fe113e21db8ffd0e8c81748e662222222
# 相关解释
- 第一组命令,配置 kubectl 的 config。
- 第二组命令,在其它 master 节点上进行初始化的命令。
- 第三组命令,在其它 work 节点上进行初始化的命令。
- 这里只需要运行第一组命令,配置好 kubectl 的配置文件,能使用 cli 控制集群。
# 执行一下配置命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
第二组和第三组命令需要记录一下。
安装 calico 网络插件
# rbac & daemonset
curl -LO https://docs.projectcalico.org/v3.11/manifests/calico.yaml
sed -i "s#192\.168\.0\.0/16#10\.240\.0\.0/16#" calico.yaml
kubectl apply -f calico.yaml
检查master初始情况
root@k8s-m1:~# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m1 Ready master 13h v1.17.3 192.168.1.210 <none> Ubuntu 18.04.3 LTS 4.15.0-91-generic docker://19.3.7
k8s-node1 Ready <none> 4h51m v1.17.3 192.168.1.211 <none> Ubuntu 18.04.3 LTS 4.15.0-91-generic docker://19.3.7
k8s-node2 Ready <none> 4h51m v1.17.3 192.168.1.212 <none> Ubuntu 18.04.3 LTS 4.15.0-91-generic docker://19.3.7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号