Linux开发人员玩转HDInsight集群上的MapReduce
HDInsight是Azure上基于Hadoop的大数据分析服务,后台使用的实际上是Hortonworks Data Platform。对于初次使用HDInsight的用户,或者从Cloudera转过来的开发人员,在刚开始使用HDInsight的时候,碰到的第一个问题是,创建完集群以后,如何提交经典的MapReduce Java程序到HDInsight集群上?总体上来说,有以下几种方式:
- 使用SSH登录到HDInsight头节点,scp需要提交的jar包,然后使用命令本地提交即可,头节点上各种环境已经配置好了,对于Linux 开发人员来说可能是最方便的,但对于团队来讲,存在安全风险,比如某个开发人员不小心改错了集群配置文件
- 使用curl命令行来提交,实际是调用HDInsight后面的REST API,将你的jar包提前上传到Azure storage,然后调用远端接口提交和查看任务即可,好处是在Linux/Mac/Windows上都可以提交,麻烦的地方时参数比较繁琐,需要自己上传jar包
- 使用PowerShell,对于Linux 开发者而言可能并不是特别习惯,而对于大家比较喜欢的Azure CLI 2.0来说,目前暂不支持HDInsight相关命令
对于企业级完整的权限控制,大家可以考虑Apache Ranger,在HDInsight上面目前支持Ranger+AD的方式提供细粒度的权限控制,当然,需要你的大数据配置管理人员比较了解Ranger的机制,配置相关的策略等等,本文介绍的一个场景是对于一个快速开发迭代的团队,选择Linux/Mac友好的第一种和第二种方式来提交MapReduce任务;在使用第一种场景的用户中,用户也希望可以使用一台单独的Linux客户机器,而不是集群头节点让开发人员提交任务,避免开发人员错误修改头节点配置导致集群问题。本文分别讨论两种方式
使用curl方式提交MapReduce任务
假设你已经在你的Linux机器,MacBook等本地开发机器上安装好了curl和准备好的Java MapReduce程序。
- 登录到HDInsight集群:
curl -u admin -G https://myhdp.azurehdinsight.net/templeton/v1/status
admin是你创建集群时的管理用户名,myhdp是你的集群名称,如果一切正常,会显示:

- 首先需要把你的jar包上传到Azure storage,上传你的MapReduce jar包,你可以使用Storage Exploer图形化界面,也可以使用Azure CLI来做,或者使用管理界面直接上传即可,相关软件的下载地址如下:
Azure Storage Explorer
https://azure.microsoft.com/en-us/features/storage-explorer/
Azure CLI 2.0
https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest
- 了解你的HDInsight的storage账号信息,可以登录到Azure Portal,点击你的HDInsight集群,选择存储账号,默认容器,你可以选择自建目录上传你的jar包,选择"上传"即可上传你的jar包:
![]()
如果你想使用命令行来做,本地我们使用Azure CLI来做;
az login
az storage blob upload -f ./hadoop-mapreduce-examples.jar -c myhdp-2018-03-31t14-12-22-220z -n myhdpstore
- 上传完成后,既可以开始提交你的MapReduce任务了,提交的任务命令行如下:
JOBID=`curl -u admin -d user.name=admin -d jar=/example/jars/hadoop-mapreduce-examples.jar -d class=wordcount -d arg=/example/data/gutenberg/davinci.txt -d arg=/example/data/output https://myhdp.azurehdinsight.net/templeton/v1/mapreduce/jar | jq .id`
echo $JOBID
![]()
- 提交完成后,可以检查任务状态:
curl -G -u admin -d user.name=admin https://myhdp.azurehdinsight.net/templeton/v1/jobs/job_1522506134287_0003 | jq .status.state
![]()
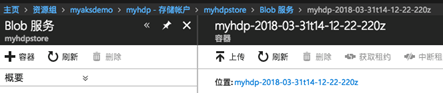
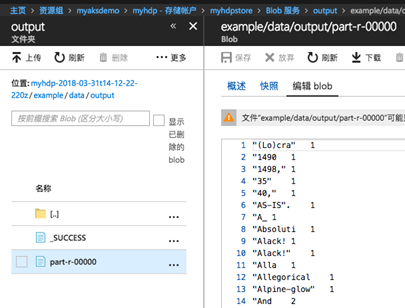
- 登录到管理界面上的HDInsight存储中,我们提交任务定义的输出目录是/example/data/output,那么我们可以检查这个工作目录,可以看到已经生成了SUCCESS和part-两个文件,word count'结果可以在part文件中检查:
![]()


HDInsight Linux客户机方式
如果想要执行完整的yarn,hdfs等功能,就需要一个完整的客户端进行操作,那么这个任务可以登录到头节点上执行,但就如之前讨论的结果,在头节点上执行不是很安全,开发运维人员容易误操作或者修改配置文件导致集群不工作,所以需要一个安全的客户机或者gateway来做;要实现这个目标,可以有几种做法,比如自己安装配置一台Linux虚拟机,从头开始安装配置Hadoop环境,依赖库,配置文件等等;或者直接从现有头文件服务器"克隆"一台客户端环境即可,本文采取第二种方式,下面详细介绍如何实现这种配置。
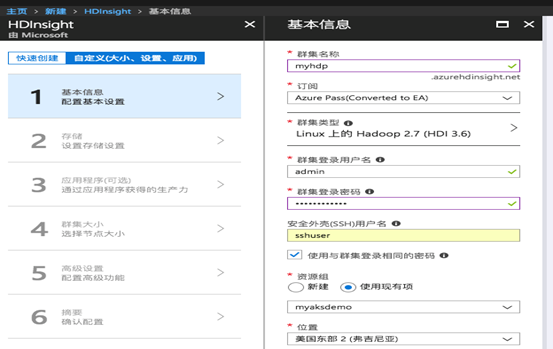
- 首先新建一套基于Linux的HDInsight集群,Hadoop 2.7,HDI 3.6,注意记住自己的用户名名,密码等:
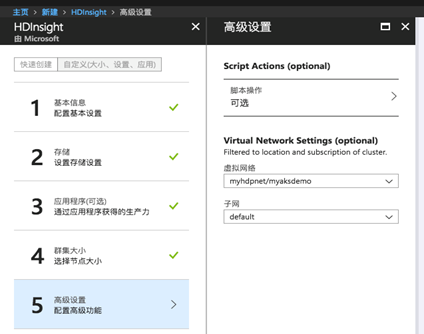
- 在第5步高级设置配置里面,选择配置到虚拟机网络,选择希望将你的集群部署进去的虚拟网络和子网,完成部署,这样可以在后续虚拟机访问的时候虚拟机和HDInsight在一个子网进行访问:
![]()
![]()
- HDInsight集群部署完成后,我们就需要部署一台Linux客户端虚拟机,这里我们选择一台Ubuntu Linux虚拟机进行部署,确保你的虚拟机和之前创建的Hadoop在一个虚拟网络之内,这里虚拟网络是myhdpnet:

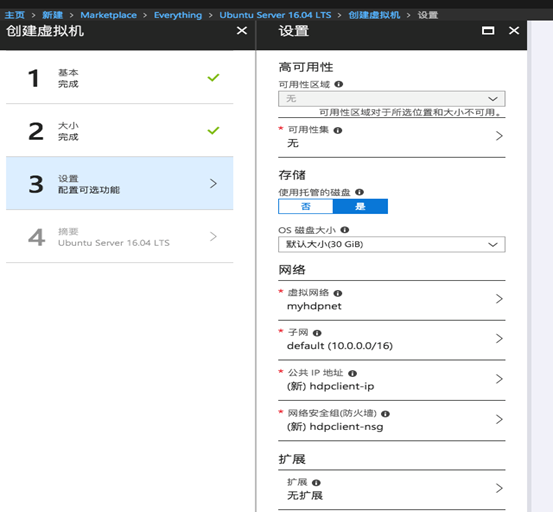
- 虚拟机部署完成后,ssh登录到这台Linux虚拟机,添加第三方的源,安装Oralce JDK,安装完成后,使用java -version测试版本:
安装OpenJDK
sudo apt-get install openjdk-8-jdk
或者安装Oracle JDK:
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer

- 登录到你的HDinsight集群的头节点,一般的链接地址类似于sshuser@myhdp-ssh.azurehdinsight.net,你可以在管理界面的你的总览部分,获得你的ssh登录信息:
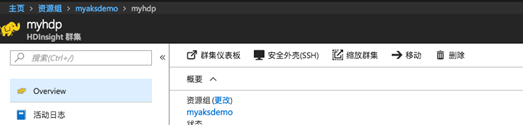
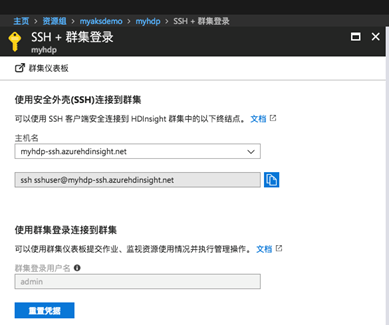
- 默认情况下,HDP的相关信息都安装在/usr/hdp下面,当前的版本是2.6.2.25-1,我们进入到这个目录,可以看到hadoop所有的需要的组件都在
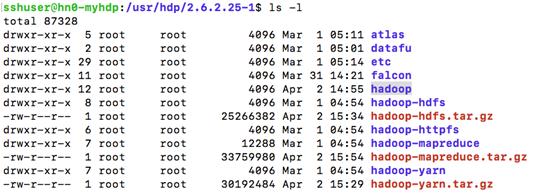
我们需要构建客户端,所以需要目录hadoop,hadoop-hdfs,Hadoop-mapreduce,Hadoop-yarn,使用tar命令分别打包,例如hadoop目录:
sudo tar -czvf hadoop.tar.gz Hadoop
7.打包配置文件,这个文件目录比较特殊,需要单独打包:
cd /usr/hdp/current/hadoop-client/conf
sudo tar -czvf conf.tar.gz ./
8. Scp你所打包的hadoop.tar.gz,hadoop-hdfs.tar.gz,hadoop-mapreduce.tar.gz,hadoop-yarn.tar.gz到你的Linux开发客户机器,创建相关目录并解压缩这些包:
sudo mkdir -p /usr/hdp/2.6.2.25-1
sudo chown -R steven:steven /usr/hdp/2.6.2.25-1
cp hadoop*.tar.gz /usr/hdp/2.6.2.25-1
tar -xzvf hadoop.tar.gz
其他的hdfs,yarn等等都是一样的方法解压缩
9. 进入到hadoop目录,删除conf链接,新建目录conf,拷贝conf.tar.gz并解压缩:

rm -rf conf
mkdir conf
cd conf
cp ~/conf.tar.gz ./
tar -xzvf conf.tar.gz
如果现在你去执行hadoop等命令,依然会报错,问题是缺少加密脚本和依赖的java库:


10.拷贝需要的依赖jar包以及安全脚本,jar包主要是微软的一些定制包,安全脚本等,需要登录到你的HDInsight头节点上:
cd /usr/lib
sudo tar -czvf hdinsight-common.tar.gz hdinsight-common/
sudo tar -czvf hdinsight-logging.tar.gz hdinsight-logging/
scp这两个tar到你的Linux客户机上,创建/usr/lib目录,并解压缩:
sudo tar -xzvf hdinsight-common.tar.gz -C /usr/lib
sudo tar -xzvf hdinsight-logging.tar.gz -C /usr/lib
sudo chown -R steven:steven /usr/lib/hdinsight-*
11.最后,为了方便在当前用户下执行hadoop等命令,将hadoop命令路径添加到当前bashrc文件中:
vi .bashrc
末尾增加一行:
export PATH=$PATH:/usr/hdp/2.6.2.25-1/hadoop/bin
source .bashrc
为了你的客户机可以根据DNS名称找到头节点,需要将头节点hosts文件里面的迪一行配置文件拷贝粘贴到你的/etc/hosts文件:
10.0.0.16 hn0-myhdp.zs5qwfxkanyefgbpqapxnhsite.cx.internal.cloudapp.net headnodehost hn0-myhdp.zs5qwfxkanyefgbpqapxnhsite.cx.internal.cloudapp.net. hn0-myhdp headnodehost.

12.好了,到现在为止,所有配置已经完成,你可以在当前虚拟机执行各种hadoop操作,比如:
hdfs dfs -ls /
hadoop fs -ls /example

使用word count测试文件提交MapReduce任务:
yarn jar hadoop-mapreduce-examples.jar wordcount /example/data/gutenberg/davinci.txt /example/data/wordcountout2
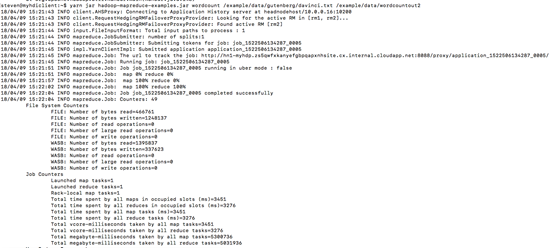
可以利用hdfs命令查看MapReduce结果文件:

posted on 2018-04-10 09:53 StevenLian 阅读(423) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号