
昇腾CANN论文上榜CVPR,全景图像生成算法交互性再增强!
近日,CVPR 2022放榜,基于昇腾CANN的AI论文《Interactive Image Synthesis with Panoptic Layout Generation》强势上榜。这为AI发烧友们开辟了一条新的图像生成之路随手选择几个类别的基础元素,并做大小和位置的拖动,便能自动生成一副摄影作品,堪比专业摄影师!
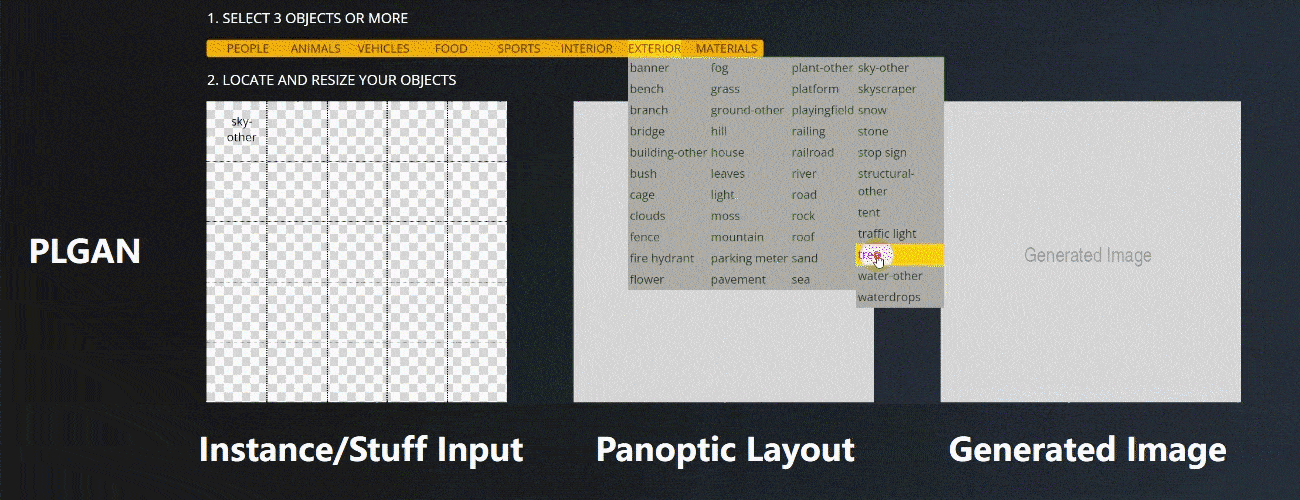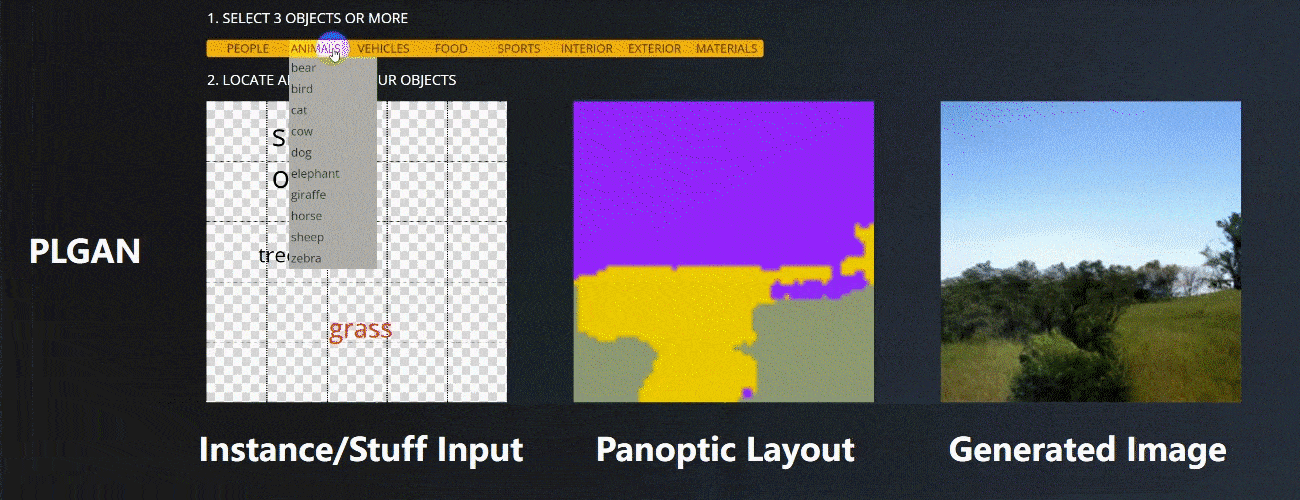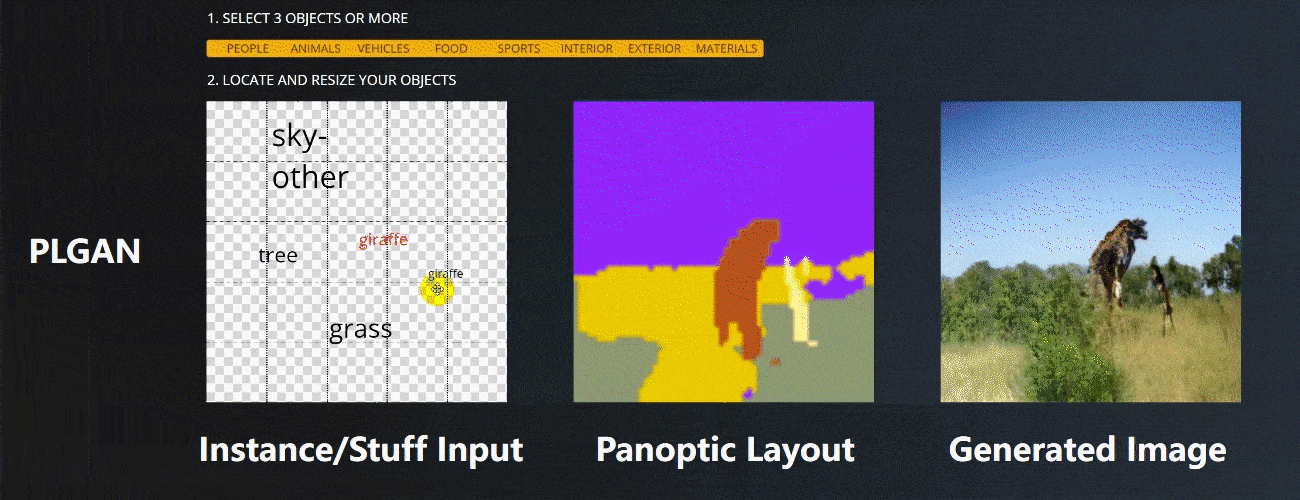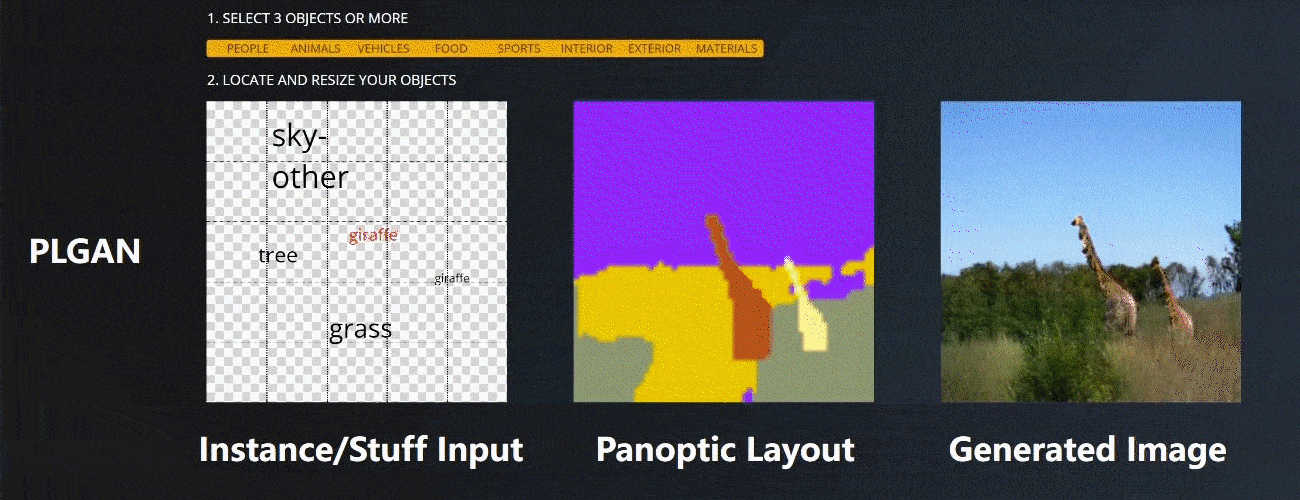
CVPR全称IEEE Conference on Computer Vision and Pattern Recognition,是计算机视觉领域三大顶会之一,并且是唯一一个年度学术会议。在快速更新迭代的计算机学科中,CVPR已然成为了计算机视觉领域的“顶流”。
本论文基于交互式的图像生成,提出基于全景布局(Panoptic Layout)辅助图像生成的方法,即PLGAN(Panoptic Layout Generation)算法,提高了交互场景下生成图像的质量及其稳定性。该论文在COCO-Stuff和VG两个公开数据集和自行收集的Landscape风景数据集上,进行了实验验证并取得了很好的效果。目前已经在华为Atlas系列服务器上实现了该算法,其配备了昇腾AI处理器提供算力支持,并借助异构计算架构CANN(Compute Architecture for Neural Networks)充分释放硬件澎湃算力,发挥极致AI性能。
论文链接:https://arxiv.org/abs/2203.02104

下面我们来看下对比交互式图像生成方法Grid2Im,本论文PLGAN算法的表现效果:
大多数交互式图像生成方法,都采用生成图像布局(Layout)为中间结果,来辅助最终的图像合成(例如 Grid2Im [1])。为了解决交互场景下图像生成质量稳定性问题,我们从图像布局(Layout)构建入手。通常的图像布局(Layout)有逐像素填充的语义图层(例如GauGAN),还有基于Bounding Box的实例图像布局(Instance Layout)。
语义图层在空间布局上逐像素对应生成的图像,可以很好的控制需要合成的图像,但其构建比较复杂,因此大多数多模态图像生成和交互场景采用实例图像布局(Instance Layout)。然而,实例图像布局(Instance Layout)本质上是采用由不同物体的位置方框(Bounding Box)和形状(Mask)组合而成的,不同物体的位置方框(Bounding Box)之间和形状边缘的不匹配,都会出现图像布局填不满的情况,在用户交互的场景下尤其明显,这使得以此为条件的条件生成模型,在最终生成图像中出现伪影和噪声,如图1所示。因此构建一个可以解决此“区域缺失”问题的图像布局(Layout),是我们所关注的重点。
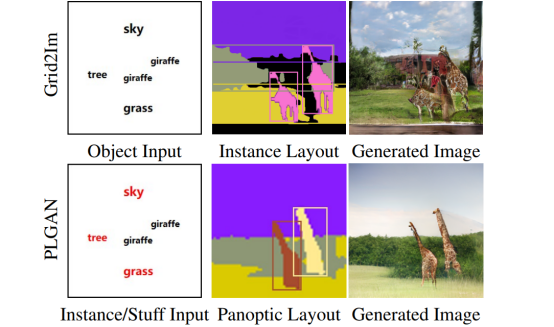
Figure 1. Scene-to-image synthesis by Grid2Im [1] vs. PLGAN
针对上述问题,引入全景分割[3]的概念,提出了基于全景布局(Panoptic Layout)的图像合成方法。在全景分割问题中[3],将物体类别分为了可数类(things)和不可数类(stuff),其中可数类(things)指有特定形状的前景类别,不可数类(stuff)指没有特定形状的背景类别。因此引入此概念,将通常的实例布局(Instance Layout)构建过程中分为Instance分支和Stuff分支分别处理可数类(things)和不可数类(stuff),如下图所示。
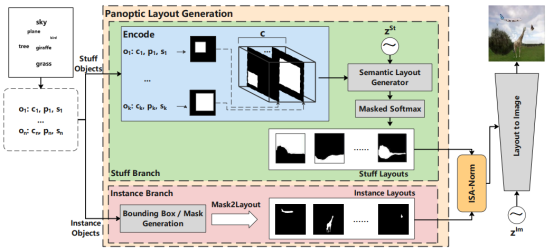
Figure 2. Overview of the PLGAN architecture
Instance分支采用通常的做法,先同时生成位置方框和形状,然后将其组合成实例布局(Instance Layout)。对于Stuff分支则使用全新的做法,直接生成填充布局(Stuff Layout),由于此结果是直接由模型通过Softmax层得到,其在整个图像空间上,不会有空缺部分,以此来解决“区域缺失”问题。因为对于不可数类别,其形状也不是固定的,这种整体生成的方式对于类别识别来说,不会带来很大的影响。分别生成的两个布局,可以通过ISA-Norm层来聚合到一起,形成最后的布局(Layout)。从布局(Layout)到最终的图像生成,我们采用SOTA模型CAL2I[2]方法,得到最终的合成图像。
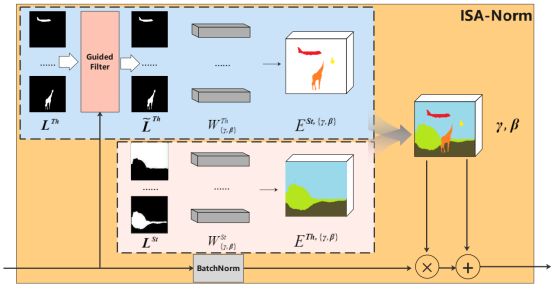
Figure 3. Illustration of Instance- and Stuff-Aware Normalization.
在实验设计上,采用对公开数据集的标注信息做扰动的方式,模拟交互式场景下的输入,在指标和视觉对比上,都得到了SOTA(state of the art)水平,尤其在输入扰动的情况下,生成图像的质量更加稳定。
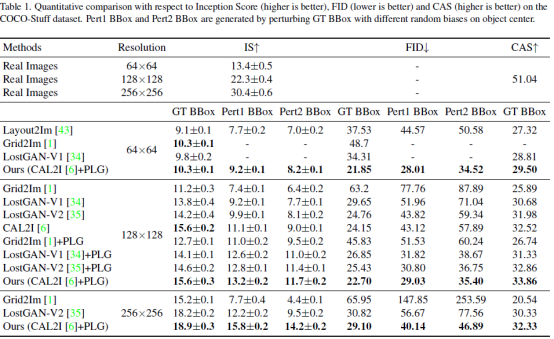

Figure 4. Visual comparison between sample images generated from perturbed BBoxes (Pert BBoxes) on the COCO-Stuff dataset

Figure 5. Visual comparison between instance layouts and panoptic layouts on the COCO-Stuff dataset
昇腾社区(hiascend.com)同步上新基于该论文的AI试玩应用,小伙伴们在给定的画布中,可以选择任意元素,大海、沙滩、天空,随心拼接拆合,然后通过华为Atlas 200 DK推理,可实时生成独一无二的真实AI风景画,扫描下方二维码即刻体验。

参考文献
[1] Oron Ashual and Lior Wolf. Specifying object attributes and relations in interactive scene generation. In Proceedings of the IEEE International Conference on Computer Vision, pages 4561–4569, 2019.
[2] Sen He, Wentong Liao, Michael Yang, Yongxin Yang, Yi-Zhe Song, Bodo Rosenhahn, and Tao Xiang. Context-aware layout to image generation with enhanced object appearance. In CVPR, 2021.
[3] Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Doll´ar. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9404–9413, 2019.
posted on 2022-03-17 14:21 Cynthia0110 阅读(158) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号