
[吴恩达机器学习笔记]11机器学习系统设计5数据量对机器学习的影响
11. 机器学习系统的设计
觉得有用的话,欢迎一起讨论相互学习~




参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广
11.5 数据量对机器学习的影响 Data For Machine Learning
问题引入
- 很多很多年前,我认识的两位研究人员 Michele Banko 和 Eric Brill 进行了一项有趣的研究,他们尝试通过机器学习算法来区分常见的易混淆的单词,他们尝试了许多种不同的算法,并发现数据量非常大时,这些不同类型的算法效果都很好
![]()
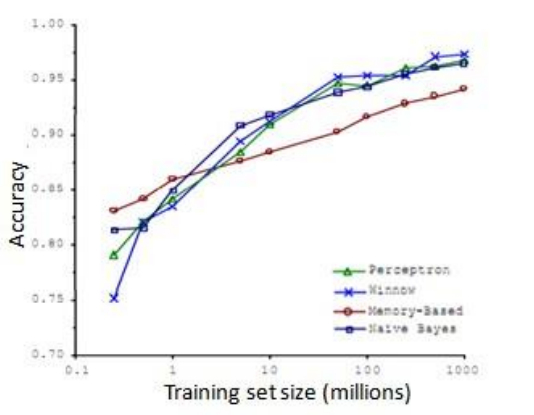
- 比如,在这样的句子中:早餐我吃了__个鸡蛋 (to,two,too),在这个例子中,“早餐我吃了 2 个鸡蛋”,这是一个易混淆的单词的例子。于是他们把诸如这样的机器学习问题,当做一类监督学习问题,并尝试将其分类,什么样的词,在一个英文句子特定的位置,才是合适的。他们用了几种不同的学习算法,这些算法都是在他们 2001 年进行研究的时候,都已经被公认是比较领先的。他们所做的就是改变了训练数据集的大小,并尝试将这些学习算法用于不同大小的训练数据集中,下面就是他们得到的结果:
![]()
- 这些趋势非常明显首先大部分算法,都具有相似的性能,其次,随着训练数据集的增大,在横轴上代表以百万为单位的训练集大小,从 0.1 个百万到 1000 百万,也就是到了 10 亿规模的训练集的样本,这些算法的性能也都对应地增强了
- 事实上,如果你选择任意一个算法,可能是选择了一个"劣等的"算法,如果你给这个劣等算法更多的数据,那么从这些例子中看起来的话,它看上去很有可能会其他算法更好,甚至会比"优等算法"更好。

具有大量参数的模型在大量数据中有更大的提升空间
- 假设特征值有足够的信息来预测y值,假设我们使用一种需要大量参数的学习算法,这些参数可以拟合非常复杂的函数,如果使用大量数据对其进行训练,这种算法能很好地拟合训练集,因此,训练误差就会很低了。
- 现在假设我们使用了非常非常大的训练集,在这种情况下,尽管我们希望有很多参数,但是如果训练集比参数的数量还大,甚至是更多,那么这些算法就不太可能会过度拟合,其还有很大的上升空间。
总结
- 如果你有大量的数据,而且你训练了一种带有很多参数的学习算法,那么这将会是一个很好的方式,来提供一个高性能的学习算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号