
[吴恩达机器学习笔记]11机器学习系统设计3-4/查全率/查准率/F1分数
11. 机器学习系统的设计
觉得有用的话,欢迎一起讨论相互学习~




参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广
11.3 偏斜类的误差度量 Error Metrics for Skewed Classes
偏斜类 Skewed Classes
- 类偏斜情况表现为训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例
示例
例如我们希望用算法来预测癌症是否是恶性的,在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有 0.5%。然而我们通过训练而得到的神经网络算法却有 1%的误差。这时,误差的大小是不能视为评判算法效果的依据的
查准率(准确率 Precision)和查全率(召回率 Recall)
- 正确肯定(True Positive,TP):预测为真,实际为真
- 正确否定(True Negative,TN):预测为假,实际为假
- 错误肯定(False Positive,FP):预测为真,实际为假
- 错误否定(False Negative,FN):预测为假,实际为真
- 查准率=TP/(TP+FP)例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
- 查全率=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
- 这样,对于总是预测病人肿瘤为良性的算法,其查全率是 0
11.4 查准率和查全率之间的权衡 Trading Off Precision and Recall
-
首先回顾 查准率(Precision) 和 查全率(Recall) 的定义,其中 $$Precision=\frac{true\ positives}{num\ of\ predicted\ positive}$$ $$Recall=\frac{true\ positives}{num\ of\ actual\ positive}$$
-
查准率(Precision)=TP/(TP+FP) 例,在所有预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
-
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好
-
继续沿用刚才预测肿瘤性质的例子。一般情况下算法输出的结果在 0-1 之间,表示患者得肿瘤的概率,并且使用阀值 0.5 来预测真和假。
![]()
-
如果 希望只在非常确信的情况下预测为真(肿瘤为恶性) ,即希望 更高的查准率 ,可以使用比0.5更大的阀值,如0.7,0.9。这样做可以减少错误预测病人为恶性肿瘤的情况,但同时会增加未能成功预测肿瘤为恶性的情况。
-
如果 希望提高查全率 ,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,可以使用比 0.5 更小的阀值 如 0.3。
-
对于同一个机器学习系统不同的阈值往往对应 不同的查准率和查全率 ,那如何选择阈值才能平衡查准率和查全率,使其都有较好的结果呢?
![]()

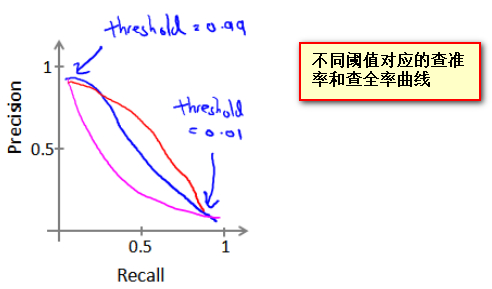
F1值
- 使用F1值: $$F1\ Score=2 * \frac{P * R}{P+R}$$ 其中P表示 查准率 ,R 表示 查全率 。 选择F1值最高的阈值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号