[DeeplearningAI笔记]序列模型3.9-3.10语音辨识/CTC损失函数/触发字检测
5.3序列模型与注意力机制
觉得有用的话,欢迎一起讨论相互学习~




3.9语音辨识 Speech recognition
- 问题描述 对于音频片段(audio clip)x ,y生成文本(transcript),人听见的或者麦克风捕捉的都是空气中细微的气压变化,语音识别系统能够根据这种微弱的气压变化将音频转化为文本字符。
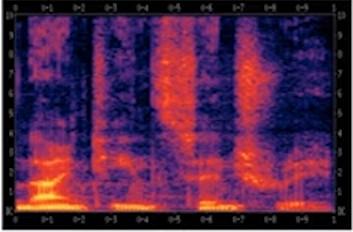
- 将空气中微弱的气压变化显示成频率图的形式,并输出音频的文本内容如下图所示:
![]()
- 考虑到人的耳朵并不会处理声音的原始波形,而是通过一种特殊的物理结构来测量不同的频率和强度的声波,音频的常见预处理方式就是生成这样的 声谱图 ,同样的 横轴是时间,纵轴是声音的频率,而图中不同的颜色显示了声波的能量,也就是在不同的时间和频率上这些声音有多大
![]()
- 音位 过去的语音识别系统是依据 音位 来进行分辨的,即通过人为制定的音位符号来表示一个特定的语言,使用音位的符号标记就能使用机器合成出指定的语言。
- 进展 但是在 深度学习 这种端到端的学习系统中使用 音位 来表示声音符号已经不再有必要,而是可以构建一个系统,通过向系统中输入音频,然后直接输出音频的文本。而不需要用这种人工设计的表示方法。所以语音识别使用的数据集特别巨大,往往可以长达300多个小时甚至3000个小时的文本音频数据集。大型的商业系统中也训练了1W或者10W个小时。

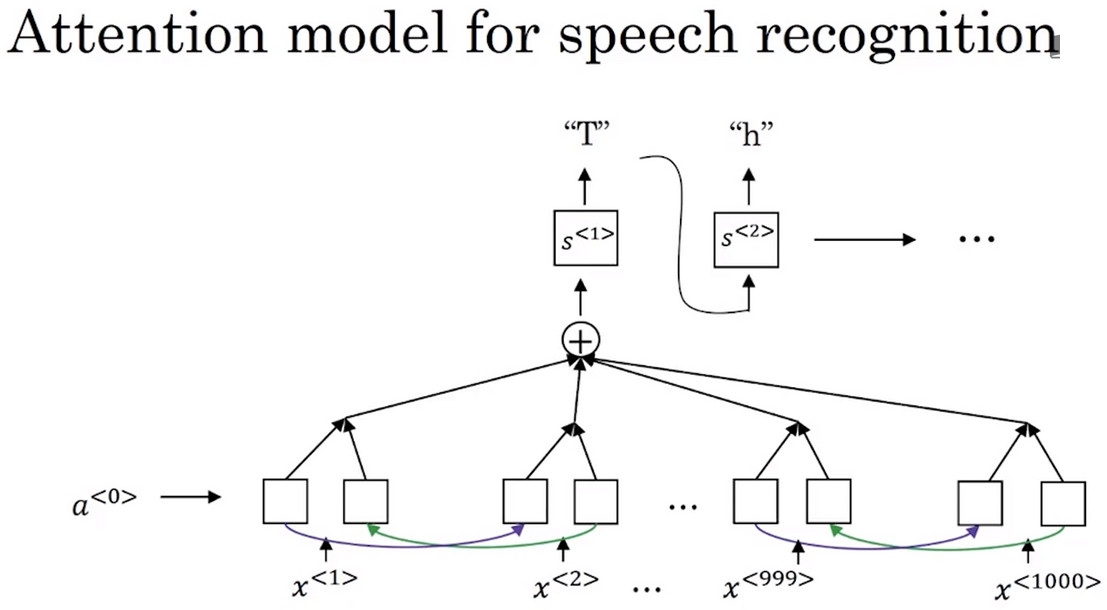
注意力模型在语音识别中的应用
- 输入语音文本数据集的不同时间帧上的数据,并使用一个注意力模型输出文本描述。
![]()
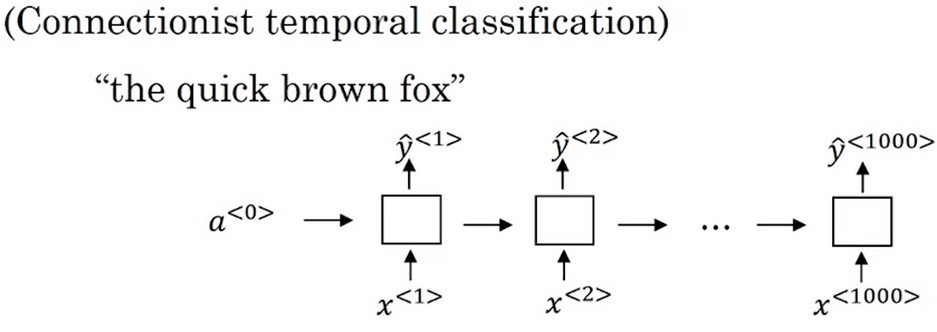
CTC损失函数语音识别(Connectionist temporal classification)
Graves A, Gomez F. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks[C]// International Conference on Machine Learning. ACM, 2006:369-376.
-
示例 假设输入音频为 the quick brown fox ,这时使用一个新的网络,在这个例子中 输入 和 输出 的数量相等,在这里使用一个简单的 单向循环神经网络 作为例子,而 实际应用使用的往往是一个很大很深的双向LSTM或GIU结构的循环神经网络 通常输入的数量往往比输出的数量要多很多 比如你有一段10秒的音频,并且特征是100HZ的,即每秒有100个样本,于是这段10s的音频片段,就会有1000个输入。
-
![]()
-
但是音频文本识别的输出肯定没有1W个,所以可以用 空白字符 和 重复字符 来对其进行填充,其中 重复字符 可以用来重叠,而 空白字符 可以用来占位。
-
例如 ttt_h_eee___\space____qqq__ \space 表示空格符,表示此处为单词的结尾,用来分割单词,而 “_ ” 表示用于占位的占位符,其中占位符中间的 重复字符 可以折叠。 ttt_h_eee___\space____qqq__ 可以被处理为 the q 三个t,e,q都可以被折叠为一个字母,而占位符可以被忽略。
3.10触发字检测 Trigger word detection
- 随着语音识别的发展,越来越多的设备可以被你的声音 唤醒 ,这被称为 触发字检测系统
![]()
- 有关于 触发字检测 的文献还处于发展阶段,对于 触发字检测 的最好算法目前还没有一个广泛的定论。

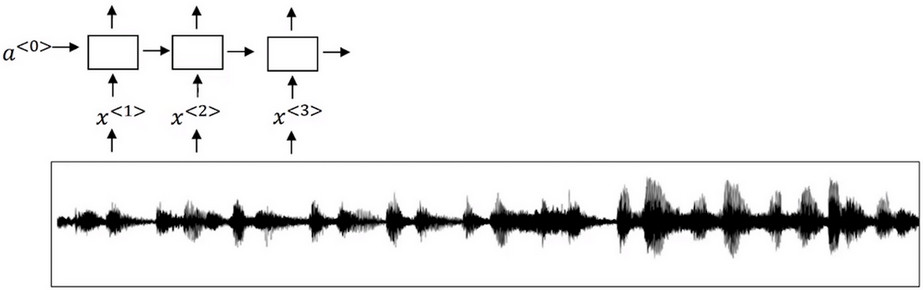
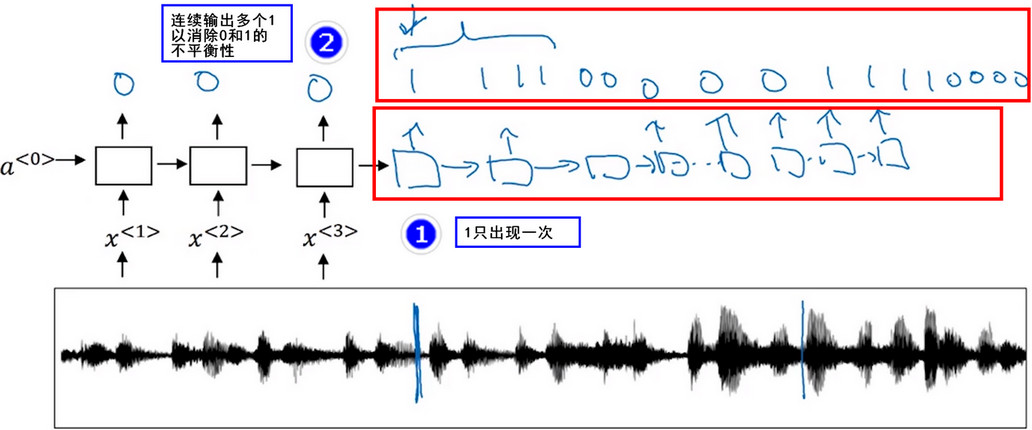
- 首先将音频文件输入到RNN中,然后定义目标标签y
![]()
- 假如音频片段的一点处刚说完一个触发字,那么你就可以在训练集中把目标标签都设为0,然后此点目标签设为1.然后此点之后恢复成0,持续这个过程,只要触发了关键词,就将目标标签设置为1.
- 缺点 该算法构建了一个很不平衡的训练集,即0的出现次数比1的出现次数多出了很多。 为了解决这个问题可以在 关键词被触发 后输出多个1,以消除这种不平衡性。
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号