
[DeeplearningAI笔记]序列模型3.7-3.8注意力模型
5.3序列模型与注意力机制
觉得有用的话,欢迎一起讨论相互学习~




3.7注意力模型直观理解Attention model intuition
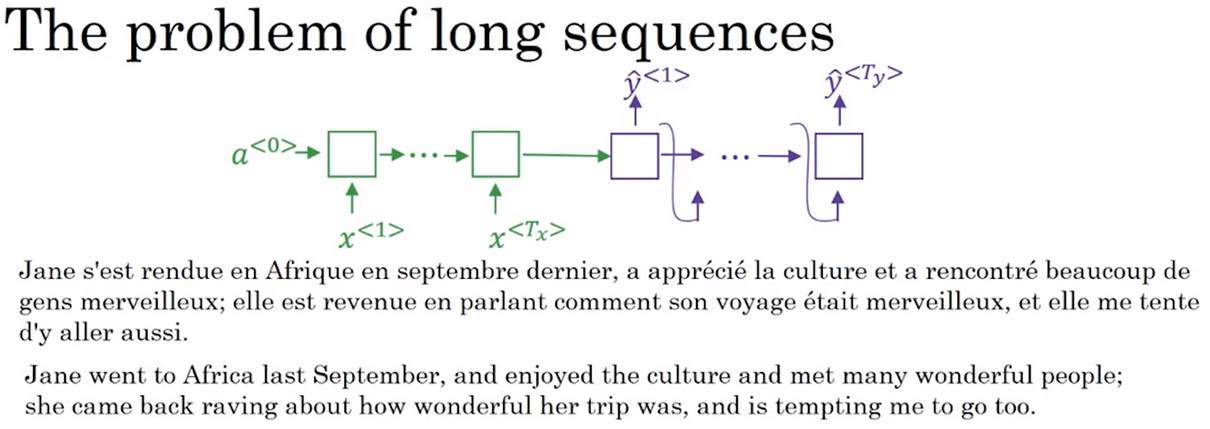
长序列问题 The problem of long sequences
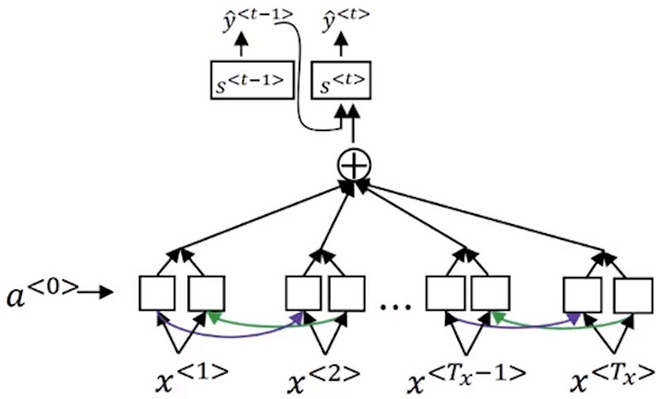
- 对于给定的长序列的法语句子,在下图中的网络中,绿色的编码器读取整个句子,然后记忆整个句子,再在感知机中传递,紫色的解码神经网络将生成英文翻译。
- 人工的方法不会通过读取在记忆整个句子中的内容,然后从零开始翻译成一个英语句子,人工翻译做的是先翻译出句子的部分,再看下一部分,并翻译这一部分,再看下一部分,然后翻译这一部分,一直进行下去。会一部分一部分的进行翻译,因为一次性看完并记忆所有句子是十分困难的。
![]()
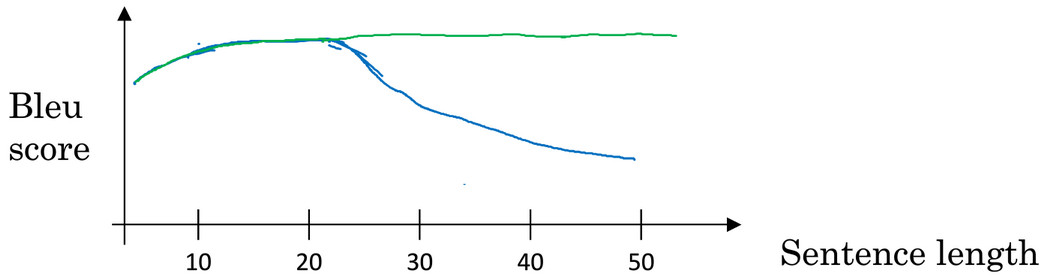
- 对于机器翻译的 编码解码 结构,对于短句子,其会有很高的Bleu得分,但是对于长句子 比如说大于30-40词 的句子而言,它的表现就会变差,而对于很短的句子由于很难从中学到有用的知识,翻译的性能也不太好。而对于长句子,注意力模型 会和人类翻译一样,每次翻译句子中的一部分,从而提高句子翻译长句子的能力。
注意力模型 Attention model intuition
Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.
- 这个模型一般使用在长句子上,此处使用短句子进行举例。 示例 Jane visite I'Afrique en Septembre ,假定使用一个双向的RNN网络:
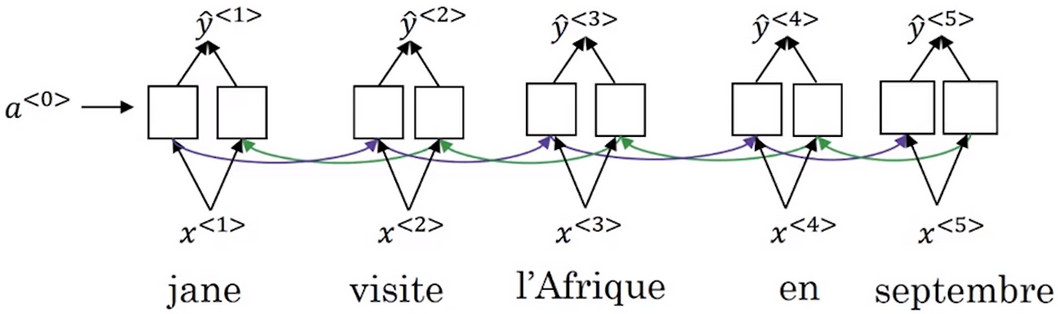
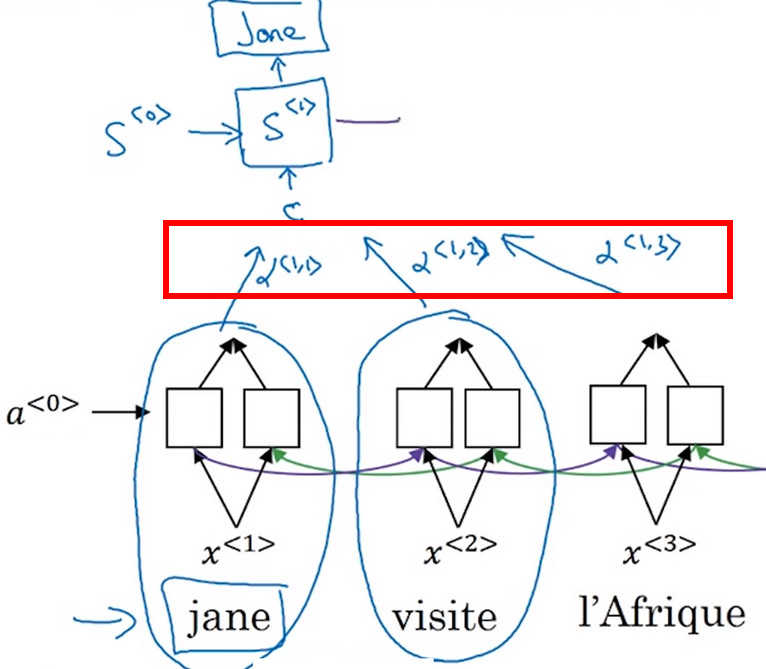
- 与普通的RNN不同的是,注意力模型不会看每一个输入的单词,而是对输入的每个单词选择一定的 注意力权重 用于 表示这个单词对于正在翻译的单词具有多大的影响 下图中的 \(\alpha^{<1,1>},\alpha^{<1,2>},\alpha^{<1,3>}\) 分别表示前三个单词对第一个词语的翻译具有的影响力。
![]()
- 对于第二个要翻译的单词,有 \(\alpha^{<2,1>},\alpha^{<2,2>},\alpha^{<2,3>}\) 用以表示在翻译第二个单词时,要分别放多少注意力在前三个单词上。并且前一步翻译的输出也会作为下一步的输入。
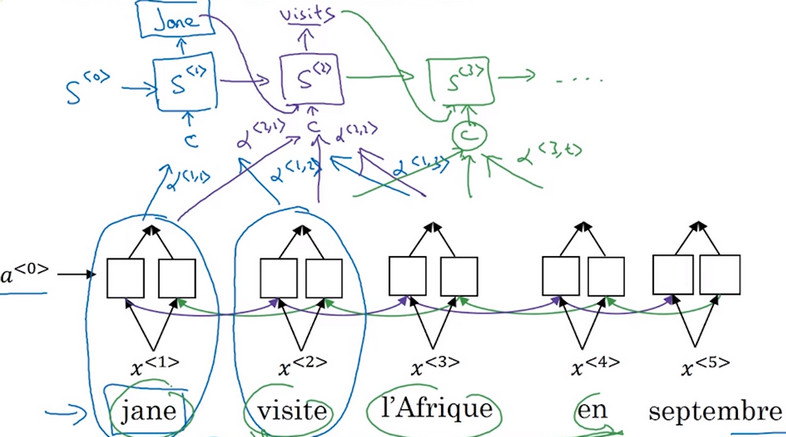
3.8注意力模型细节Attention model
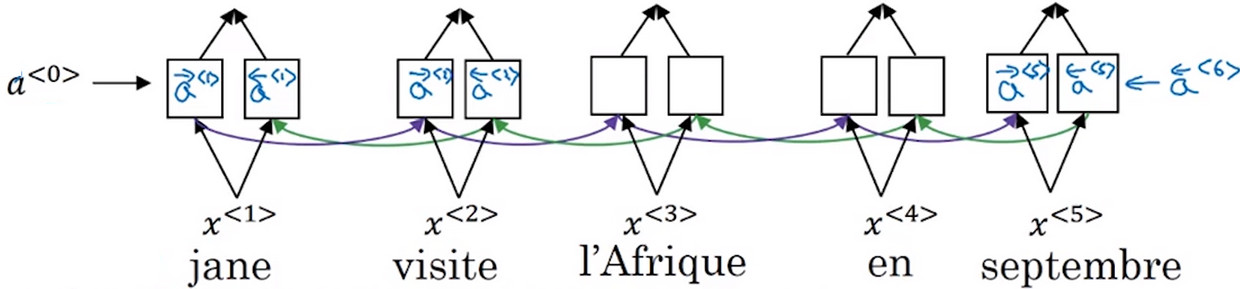
- 特征提取模型 使用的双向循环神经网络,这样其对于 前向传播 和 后向传播 分别有激活值\(\overrightarrow{a^{<t'>}}和\overleftarrow{a^{<t'>}}\) , 对于一个时间步,使用\(a^{<t'>}表示一组前向传播和后向传播的激活值 即 \overrightarrow{a^{<t'>}}和\overleftarrow{a^{<t'>}}\) ,即有 \(a^{<t'>}=(\overrightarrow{a^{<t'>}},\overleftarrow{a^{<t'>}})\)
![]()
- 翻译 使用的是一个单向循环神经网络,用状态S表示时间步序列,第一个时间步输出为\(y^{<1>}\),使用参数\(\alpha^{<1,t>}表示上下文的特征对状态S^{<t>}的翻译的影响\),使用\(C^{<t>}\)表示状态\(S^{<t>}\)时的输入。其中其满足以下公式:
\[<1> 注意力权重之和为1
\]
\[\sum_{t'}\alpha^{<1,t'>}=1
\]
\[<2> 特征步的激活值和注意力权重的乘积之和成为翻译RNN的输入
\]
\[C^{<1>}=\sum_{t'}\alpha^{<1,t'>}a^{<t'>}
\]
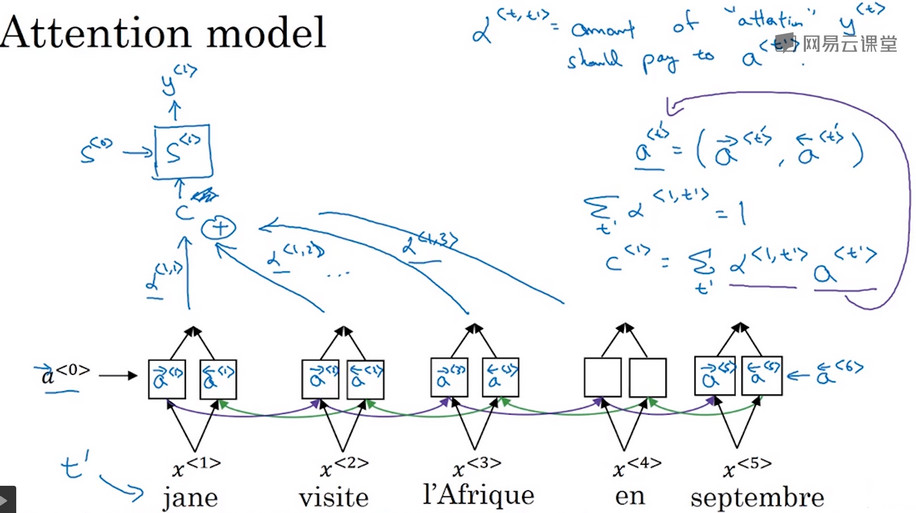
- 即当你在t处生成输出词时,你应该花多少注意力在第t'个输入词上
注意力计算方法 Computing attention \(\alpha^{<t,t'>}\)
[1] Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.
[2] Xu K, Ba J, Kiros R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention[J]. Computer Science, 2015:2048-2057.
- \(a^{<t,t’>}\) 是你应该在\(a^{<t'>}\)上的注意力数量,但你需要翻译第t个输出的翻译词。
- \(a^{<t,t'>}\)=amount of attention \(y^{<t>}\) should pay to \(a^{<t'>}\)
- 公式
![]()
- 要计算以上公式,重点是需要计算出\(e^{<t,t'>}\),而\(e^{<t,t'>}\)的计算需要通过上一个翻译状态的值\(s^{<t-1>}\)和上一个单项循环模块的输出值\(s^{<t-1>}\)
![]()
![]()
- 即如果你想要决定要花多少注意力在t'的激活值上,它会很大程度的取决于上一个时间步的隐藏状态的激活值,你没有当前状态的激活值,因为上下文会输入到这里,所以当前状态的激活值还没有被计算出来。
- 虽然我们能够知道\(a^{<t,t'>}\)的关键项和上一个状态的隐藏项\(s^{<t-1>}\)与特征提取模型中本状态的激活值\(a^{<t'>}\)有关,但并不知道明确的函数对应关系,这可以通过一个小型的神经网络进行学习这个函数。
![]()
缺点 这个算法的缺点是其算法的复杂度是\(O(n^{3})\),如果有\(T_x\)个输入单词和\(T_y\)个输出单词,于是注意力参数的总数就是\(T_x乘以T_y\)
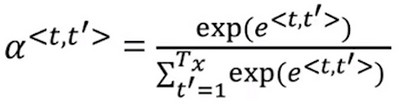

应用
- 这个算法不仅可以用于机器翻译,也可以被用于 图片加标题
- 日期标准化问题
- July 20th 1969-->1969-07-20;
- 23 April,1564-->1564-04-23
- 可视化不同输入输出的注意力权重 :
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号