[DeeplearningAI笔记]序列模型3.2有条件的语言模型与贪心搜索的不可行性
5.3序列模型与注意力机制
觉得有用的话,欢迎一起讨论相互学习~




3.2选择最可能的句子 Picking the most likely sentence
condition language model 有条件的语言模型
-
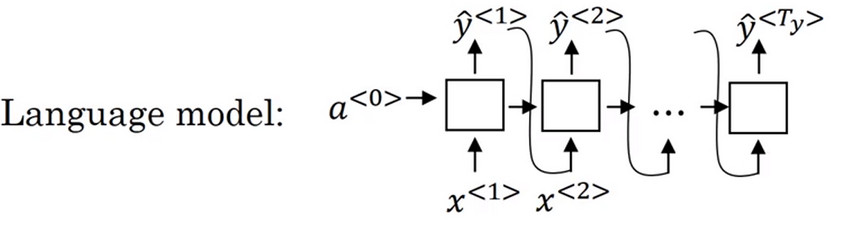
对于 语言模型 ,能够估计出这些单词是一个句子的可能性,也可以用其生成一个新的句子。
-
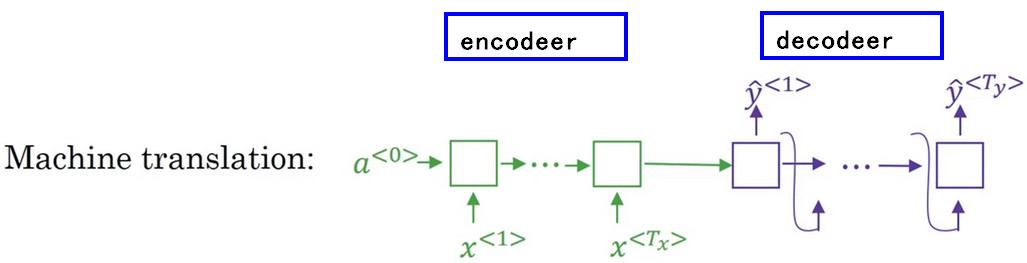
对于 机器翻译模型 使用绿色表示 编码网络 ,使用 紫色表示 解码网络。
![]()
-
会发现 解码网络 和 语言模型 几乎一模一样,只是在普通的语言模型中输入的向量 \(a^{<0>}\)是0向量,但是在机器翻译模型中 decoder 的输入是 encoder 的输出。所以称机器翻译中的 decoder 为 condition language model 有条件的语言模型
-
通过机器翻译模型,模型会告诉你各种翻译所对应的可能性--即 \(P(y^{<1>},...,y^{<T_{y}>}|x)\),其中x表示输入的法语句子,而y表示对应的机器翻译输出。但是通过随机取样后,每次输出的y不同。
![]()
目的就是找到一个y,使得\(P(y^{<1>},...,y^{<T_{y}>}|x)\) 的概率最大,此时最常用的算法为 束搜索(Bean Search)

贪心搜索(Greedy Search)的不可行性
-
生成第一个词的分布以后,它会根据你的条件语言模型挑选出最有可能的第一个词,进入机器翻译模型中,在挑选出第一个词后,它会继续挑选出第二个最有可能的词,然后继续挑选出第三个最有可能的词,这种算法就叫做 贪心搜索
-
但是你真正需要的是整个单词序列从\(y^{<1>},y^{<2>},...,y^{<T_{y}>}\),来使整体的概率最大化。所以 贪心搜索 算法不那么管用。
-
对于句子:
[1] “Jane is visiting Africa in September”
[2] "Jane is going to be visiting Africa in September"
很明显第一个句子的翻译更好,因为第一句话相对于第二句话来说更加简洁。 -
首先翻译出 Jane is 在英语中 going to 相对于 visiting 出现频率更多,如果使用 贪心搜索 方法,则有更高的概率会选择 going to 作为翻译的结果。这样得到的翻译结果并不是最佳的。
-
Note 所以此时应该考虑一种近似全局的搜索方式,从词典中挑选需要单词的组合近似的使 条件概率最大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号