[DeeplearningAI笔记]序列模型3.1基本的 Seq2Seq /image to Seq
5.3序列模型与注意力机制
觉得有用的话,欢迎一起讨论相互学习~




3.1基础模型
[1] Sutskever I, Vinyals O, Le Q V. Sequence to Sequence Learning with Neural Networks[J]. 2014, 4:3104-3112.
[2] Cho K, Van Merrienboer B, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Computer Science, 2014.
seq2seq
- 示例 对于法语句子: Jane visite l'Afrique en septembre 翻译成英语为 : Jane is visiting Africa in September
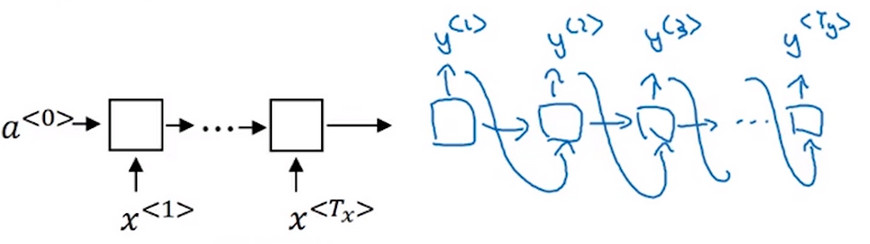
- 对于输入句子使用\(x^{<1>},x^{<2>},x^{<3>},x^{<4>},x^{<5>}\)来表示输入句子的单词,使用\(y^{<1>},y^{<2>},y^{<3>},y^{<4>},y^{<5>},y^{<6>}\)来表示输出句子的单词。
![]()
- 首先建立 编码网络encoder network 它是一个RNN结构,RNN的子结构可以是GRU或者LSTM,每次向网络中输入一个单词,将输入序列接收完毕后,这个RNN会输出一个向量来代表这个输入序列。
- 之后你可以建立一个 解码网络decoder network 它以编码网络的输出作为输入。 解码网络 可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记,解码网络工作结束。
- 和介绍RNN时一样,解码网络 将前一个时间步的输出作为输入进行该时间步的预测。
![]()
- 这个模型简单地使用一个编码网络对输入的法语句子进行编码,然后用一个解码网络来生成对应的英语翻译

[1] Mao J, Xu W, Yang Y, et al. Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN)[J]. Eprint Arxiv, 2015.
[2] Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015:3156-3164.
[3] Karpathy A, Li F F. Deep visual-semantic alignments for generating image descriptions[C]// Computer Vision and Pattern Recognition. IEEE, 2015:3128-3137.
Image captioning 图片描述 image to Sequence model
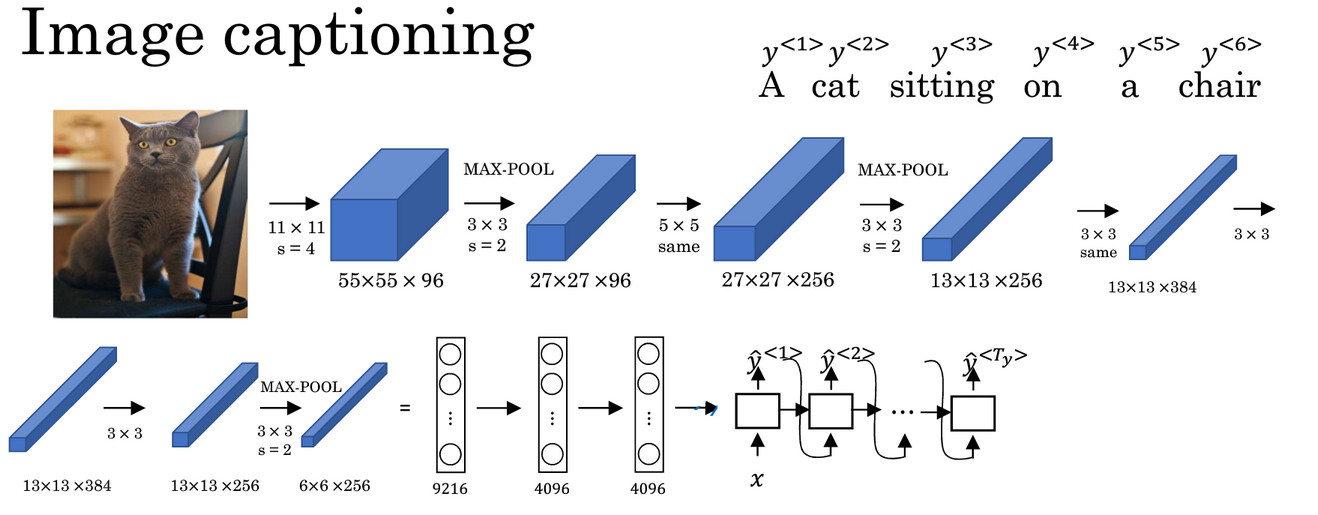
- 类似的结构也可以被用来做 图片描述(Image captioning) , 给出一张图片,他能自动地输出该图片的描述。
![]()
A cat sitting on a chair

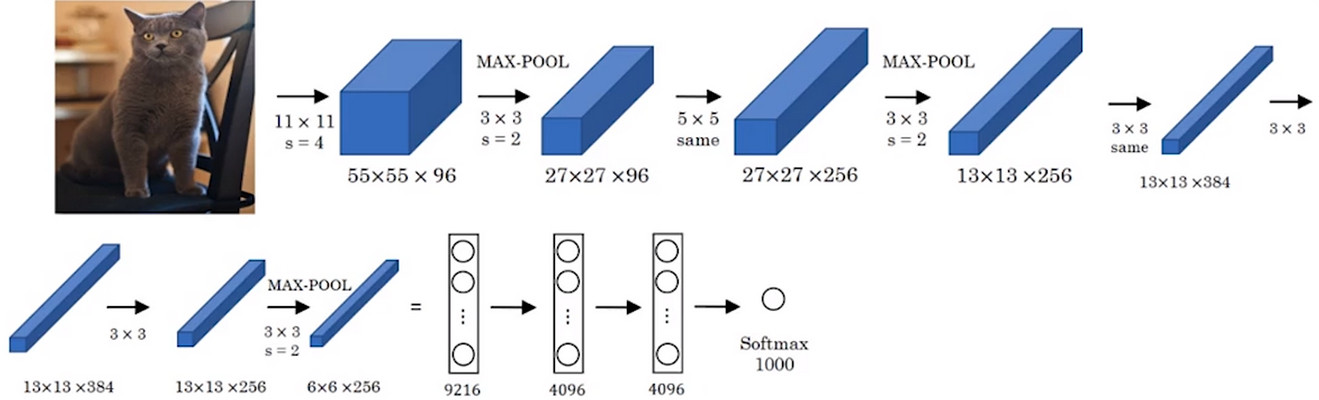
- 首先,使用CNN学习图片的一系列特征,并输出图片的编码。
![]()
- 去掉末端的softmax单元,可以得到一个4096维的向量来表示这张图片
- 接着可以把这个向量输入到RNN中,RNN通过每次生成一个单词的形式输出该图片的描述。事实证明,这种方法十分有效,特别是当输出的描述图片的句子不是特别长的时候

 浙公网安备 33010602011771号
浙公网安备 33010602011771号