[DeeplearningAI笔记]序列模型2.10词嵌入除偏
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~




2.10词嵌入除偏 Debiasing word embeddings
Bolukbasi T, Chang K W, Zou J, et al. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings[J]. 2016.
- 机器学习和人工智能算法正渐渐被信任用以辅助或是制定极其重要的决策,所以要确保人工智能系统不受非预期形式的偏见影响--比如说 性别歧视,种族歧视 本节将介绍在词嵌入技术中减少或消除这些形式的偏见的方法。
The problem of bias in word embeddings 词嵌入中的偏见问题
-
示例 当使用词嵌入系统做语言推断时:假如Man对应Woman,则King对应Queen.这是正确而显而易见的,但是当对系统输入Man对应Computer Programmer(程序员)时,系统对应的Woman显示为Homemaker(家庭主妇)--这涉及到 性别歧视 的问题。当Father对应Doctor时,Mother对应Nurse--这也是不对的。
-
因此,根据训练模型时使用的文本,词嵌入能够反映出性别,种族,年龄,性取向等其他方面的偏见。 由于机器学习人工智能正对人们的生活发挥着越来越重要的作用 所以修改这种 误差 至关重要。

Addressing bias in word embeddings
- 辨别出我们想要减少或想要消除的特定偏见的趋势,此处以 性别歧视 作为研究示例
- 首先将 性别相反的词嵌入向量的差求平均 即: \(Average((e_{he}-e_{she})+(e_{male}-e_{female})+(e_{boy}-e_{girl})+...)\) 得以求出一个 偏见趋势 --这个偏见趋势有可能是1维的也可能是更高维度的向量。而其余的维度则可以被认为是 无偏见趋势
- Note 在原论文中相对于此处使用的求平均值的算法,论文中使用的是更加复杂的算法--SUV奇异值分解
- 中和步(Neutralize) 对于那些定义不确切的词可以适当的处理以避免偏见,有些词语本质上就和性别有关 mother 和 father ,然而有些词汇例如 doctor 和 babysitter 在性别方向是中立的。 对于这些定义中立的词语,我们选择在 无偏见趋势 的轴方向上进行处理,以减少在 偏见趋势 方向上的差距。
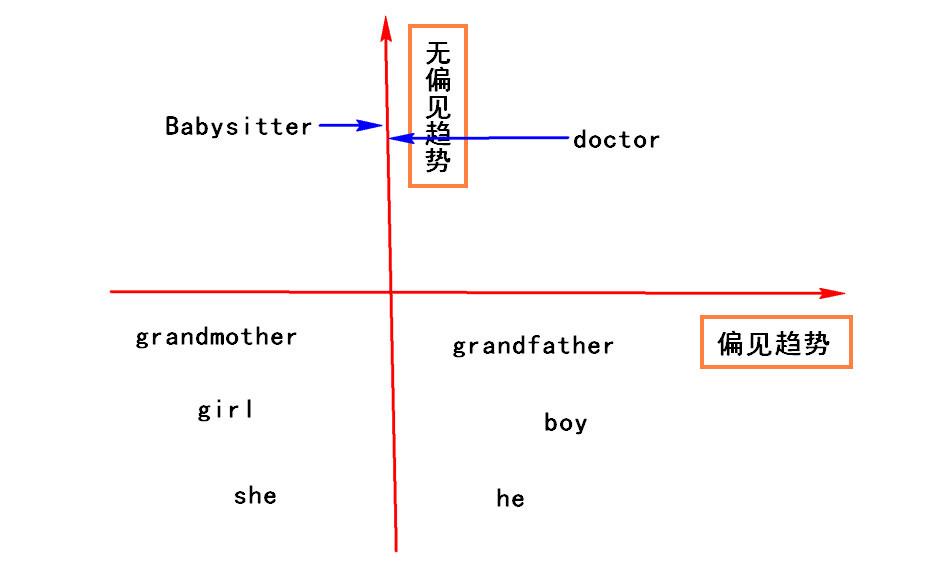
- 均衡步(Equalize pairs) 对于 偏见词对 例如 father 和 mather , boy 和 girl , 希望 偏见词对 对 babysitter 和 doctor 类型的词汇的影响相等,即将 偏见词对 向 无偏见趋势 相靠拢,使到 babysitter 这种中性词的距离相等。

- Note 怎样判断一个词汇是中性的, 类似于 beard(胡子) 这个词应该更靠近男性(male)一些。
- 论文作者 通过训练一个分类器来尝试解决哪些词是有明确定义的,哪些词是性别确定的,哪些词不是。
- Note 在实际使用中,需要平衡的 偏见词对 数其实并不多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号