
Tensorflow ActiveFunction激活函数解析
Active Function 激活函数
原创文章,请勿转载哦~!!
觉得有用的话,欢迎一起讨论相互学习~




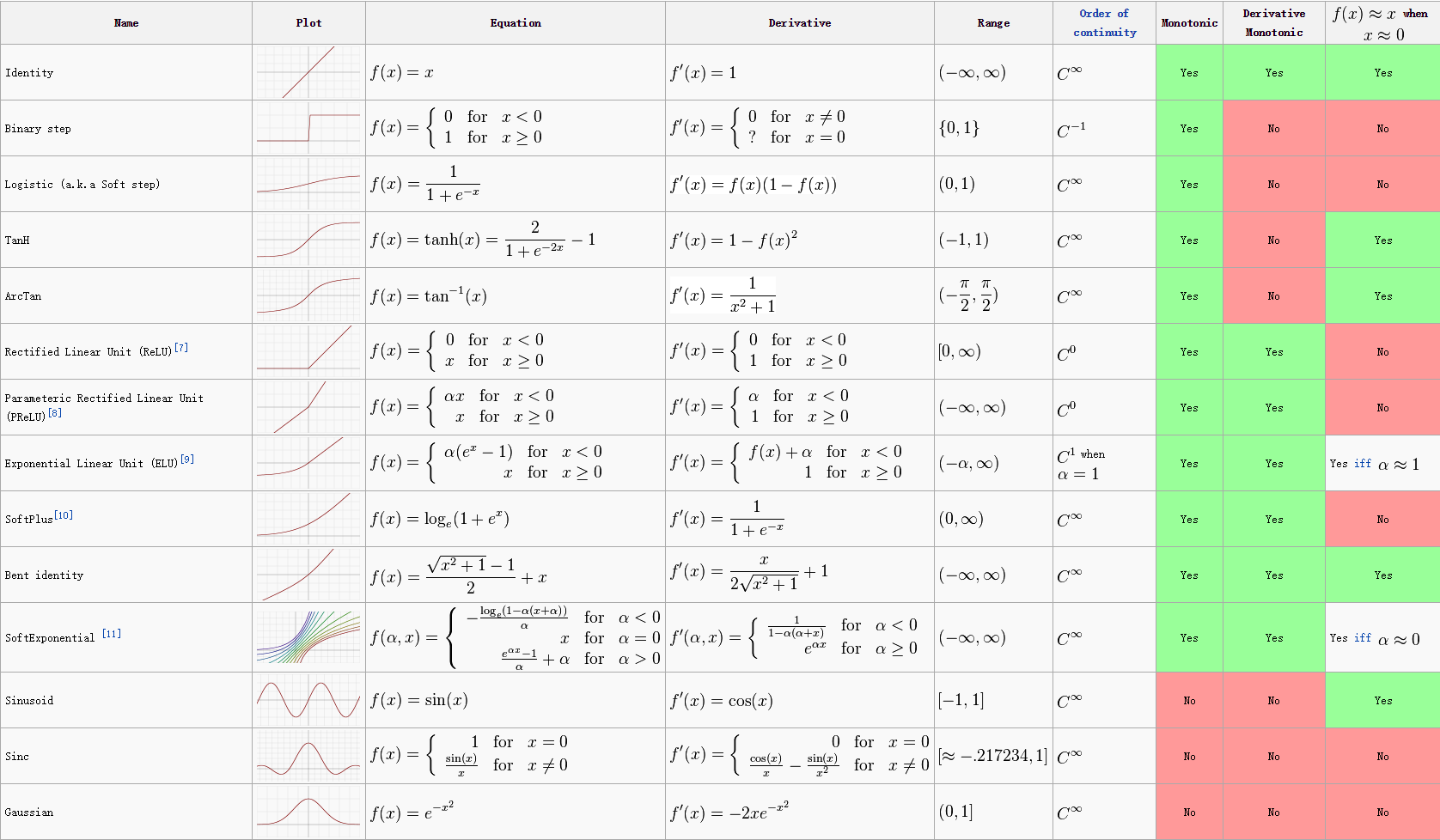
- Tensorflow提供了多种激活函数,在CNN中,人们主要是用tf.nn.relu,是因为它虽然会带来一些信息损失,但是性能较为突出.开始设计模型时,推荐使用tf.nn.relu,但高级用户也可创建自己的激活函数.评价某个激活函数是否有用时,需要考虑的因素有:
-
该函数应是单调的, 这样输出便会随着输入的增长而增长,从而使利用梯度下降法寻找局部极值点成为可能.
-
该函数应是可微分的,以保证该函数定义域内的任意一点上导数都存在,从而使得梯度下降法能够正常使用来自这类激活函数的输出.
tf.nn.relu
tf.nn.relu(features, name = None)
-
解释:这个函数的作用是计算激活函数relu,即max(features, 0)。
所有负数都会归一化为0,所以的正值保留为原值不变 -
优点在于不收"梯度消失"的影响,且取值范围在[0,+oo]
-
缺点在于使用了较大的学习速率时,易受达到饱和的神经元的影响
使用例子
import tensorflow as tf
a = tf.constant([-1.0, 2.0])
with tf.Session() as sess:
b = tf.nn.relu(a)
print(sess.run(b))
# [0. 2.]
输入参数:
● features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16,int8。
● name: (可选)为这个操作取一个名字。
输出参数:
● 一个Tensor,数据类型和features相同。
tf.sigmoid
tf.sigmoid(x, name = None)
-
解释:这个函数的作用是计算 x 的 sigmoid 函数。具体计算公式为 \(y = 1 / (1 + exp(-x))\)
-
函数的返回值位于区间[0.0 , 1.0]中,当输入值较大时,tf.sigmoid将返回一个接近于1.0的值,而当输入值较小时,返回值将接近于0.0.
-
优点在于对在真实输出位于[0.0,1.0]的样本上训练的神经网络,sigmoid函数可将输出保持在[0.0,1.0]内的能力非常有用.
-
缺点在于当输出接近于饱和或者剧烈变化是,对输出返回的这种缩减会带来一些不利影响.
-
当输入为0时,sigmoid函数的输出为0.5,即sigmoid函数值域的中间点
使用例子
import tensorflow as tf
a = tf.constant([[-1.0, -2.0], [1.0, 2.0], [0.0, 0.0]])
sess = tf.Session()
print(sess.run(tf.sigmoid(a)))
# [[ 0.26894143 0.11920292]
# [ 0.7310586 0.88079703]
# [ 0.5 0.5 ]]
输入参数:
● x: 一个Tensor。数据类型必须是float,double,int32,complex64,int64或者qint32。
● name: (可选)为这个操作取一个名字。
输出参数:
● 一个Tensor,如果 x.dtype != qint32 ,那么返回的数据类型和x相同,否则返回的数据类型是 quint8
tf.tanh
tf.tanh(x, name = None)
-
解释:这个函数的作用是计算 x 的 tanh 函数。具体计算公式为\(( exp(x) - exp(-x) ) / ( exp(x) + exp(-x) )\)
-
tanh和tf.sigmoid非常接近,且与后者具有类似的优缺点,tf.sigmoid和tf.tanh的主要区别在于后者的值为[-1.0,1.0]
-
优点在于在一些特定的网络架构中,能够输出负值的能力十分有用.
-
缺点在于注意tf.tanh值域的中间点为0.0,当网络中的下一层期待输入为负值或者为0.0时,这将引发一系列问题.
使用例子
import tensorflow as tf
a = tf.constant([[-1.0, -2.0], [1.0, 2.0], [0.0, 0.0]])
sess = tf.Session()
print(sess.run(tf.tanh(a)))
# [[-0.76159418 -0.96402758]
# [ 0.76159418 0.96402758]
# [ 0. 0. ]]
输入参数:
● x: 一个Tensor。数据类型必须是float,double,int32,complex64,int64或者qint32。
● name: (可选)为这个操作取一个名字。
输出参数:
● 一个Tensor,如果 x.dtype != qint32 ,那么返回的数据类型和x相同,否则返回的数据类型是 quint8 .
tf.nn.dropout
tf.nn.dropout(x, keep_prob, noise_shape = None, seed = None, name = None)
-
解释:这个函数虽然不是激活函数,其作用是计算神经网络层的dropout。一个神经元将以概率keep_prob决定是否放电,如果不放电,那么该神经元的输出将是0,如果该神经元放电,那么该神经元的输出值将被放大到原来的1/keep_prob倍。这里的放大操作是为了保持神经元输出总个数不变。比如,神经元的值为[1, 2],keep_prob的值是0.5,并且是第一个神经元是放电的,第二个神经元不放电,那么神经元输出的结果是[2, 0],也就是相当于,第一个神经元被当做了1/keep_prob个输出,即2个。这样保证了总和2个神经元保持不变。
-
默认情况下,每个神经元是否放电是相互独立的。但是,如果noise_shape被修改了,那么他对于变量x就是一个广播形式,而且当且仅当 noise_shape[i] == shape(x)[i] ,x中的元素是相互独立的。比如,如果 shape(x) = [k, l, m, n], noise_shape = [k, 1, 1, n] ,那么每个批和通道都是相互独立的,但是每行和每列的数据都是关联的,即要不都为0,要不都还是原来的值。一荣俱荣,一损俱损.
使用例子
import tensorflow as tf
# tf.nn.dropout(x, keep_prob, noise_shape = None, seed = None, name = None)
a = tf.constant([[-1.0, 2.0, 3.0, 4.0]])
with tf.Session() as sess:
b = tf.nn.dropout(a, 0.5, noise_shape=[1, 4]) # 第0维相互独立,第1维相互独立
print(sess.run(b))
b = tf.nn.dropout(a, 0.5, noise_shape=[1, 1]) # 第0维相互独立,第1维不是相互独立的
print(sess.run(b))
# 第一次
# [[-0. 4. 0. 0.]]
# [[-2. 4. 6. 8.]]
# 第二次
# [[-2. 0. 6. 8.]]
# [[-0. 0. 0. 0.]]
输入参数:
● x: 一个Tensor。
● keep_prob: 一个 Python 的 float 类型。表示元素是否放电的概率。
● noise_shape: 一个一维的Tensor,数据类型是int32。代表元素是否独立的标志。
● seed: 一个Python的整数类型。设置随机种子。
● name: (可选)为这个操作取一个名字。
输出参数:
● 一个Tensor,数据维度和x相同。
异常:
● 输入异常: 如果 keep_prob 不是在(0, 1]区间,那么会提示错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号