python垃圾回收和内存管理
在 Python 的世界里,高效的垃圾回收和精细的内存管理机制是确保程序稳定运行的关键。它们在幕后默默工作,自动处理内存的分配与回收,让开发者无需过多担忧内存泄漏等问题,从而能够专注于实现业务逻辑。让我们一同探索 Python 中这一强大而又神秘的领域。
目录
引用计数器
概念
在 Python 中,每个对象(比如列表、字符串等)都有一个与之关联的引用计数器(reference count)。引用计数器记录了有多少个变量或引用指向这个对象。每当一个新的引用指向该对象时,引用计数器就会增加;如果一个引用不再指向该对象(比如变量被删除或重新赋值),引用计数器就会减少。
示例
a = ["篮球", "足球", "乒乓球"]
b = a # 列表被引用了两次,引用计数器的值为2
对象的存放
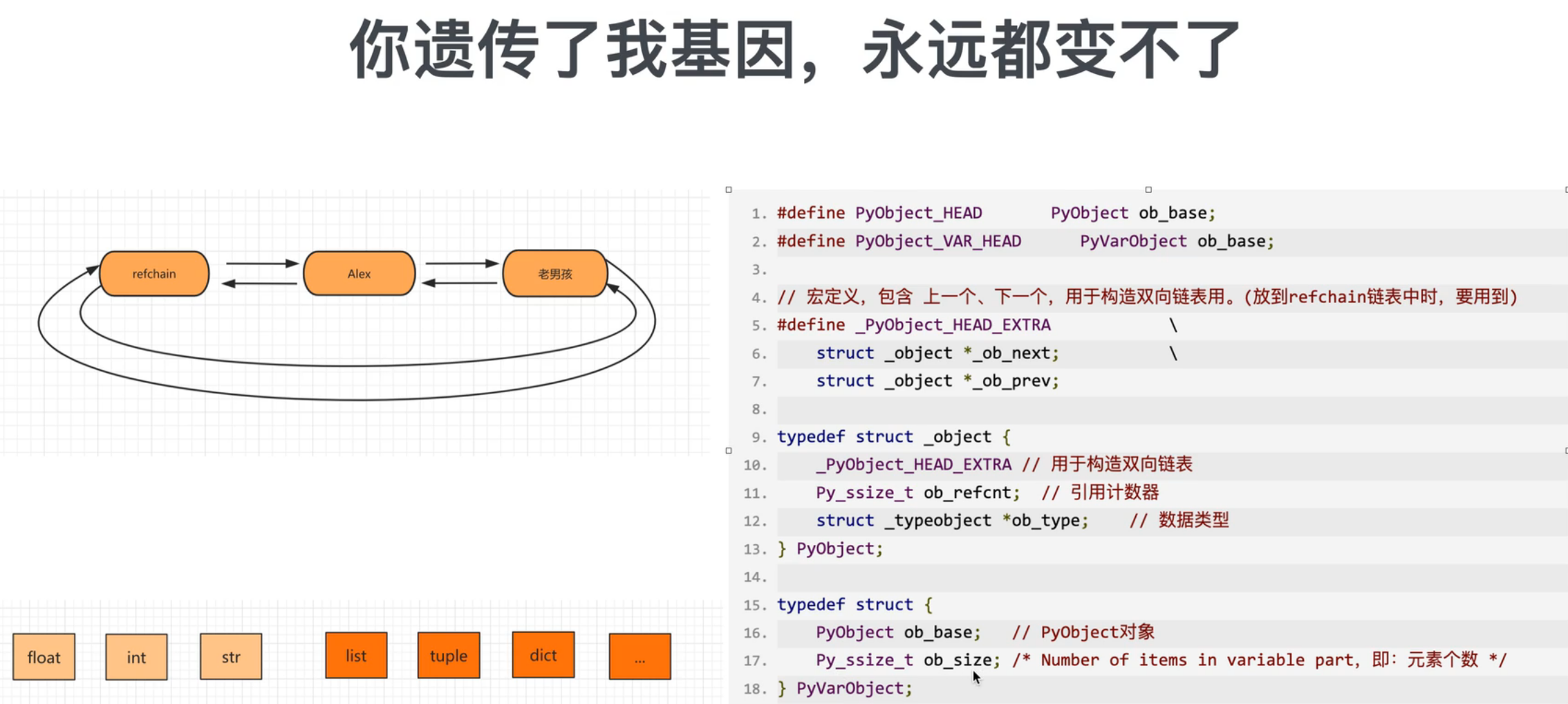
在python程序中创建的任何对象都会放在一个名为refchain的双向环状链表中。每创建一个新对象,都会加入该环状链表。
对象的定义
python中定义对象基于以下两个结构体,PyObject结构体与PyVarObject结构体。引用计数器是这两个结构体的成员之一,用于统计该对象被引用的个数。
// 代码位置:python源码文件/Include文件夹/object.h文件 第82行
// PyObject_HEAD defines the initial segment of every PyObject.
// PyObject_VAR_HEAD defines the initial segment of all variable-size
#define PyObject_HEAD PyObject ob_base;
#define PyObject_VAR_HEAD PyVarObject ob_base;
// 用于构造双向链表(放到refchain链表中时会用到)
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
typedef struct _object {
_PyObject_HEAD_EXTRA // 用于构造双向链表
Py_ssize_t ob_refcnt; // 引用计数器
PyTypeObject *ob_type; // 数据类型
} PyObject;
typedef struct {
PyObject ob_base; // PyObject对象
Py_ssize_t ob_size; /* Number of items in variable part,即:元素个数 */
} PyVarObject;
创建-销毁对象过程
在python中当创建一个对象时,python会将该对象加入双向环状链表refchain中,默认引用计数器ob_refcnt=1,如果该对象再次被引用,ob_refcnt + 1。当使用del销毁一个该对象的引用时ob_refcnt - 1,当ob_refcnt等于0时,意味着没有人在使用这个对象了,这个对象就是垃圾,进行垃圾回收。
回收:1.对象从refchain链表移除;2.将对象销毁,内存归还。
标记清除
循环引用问题
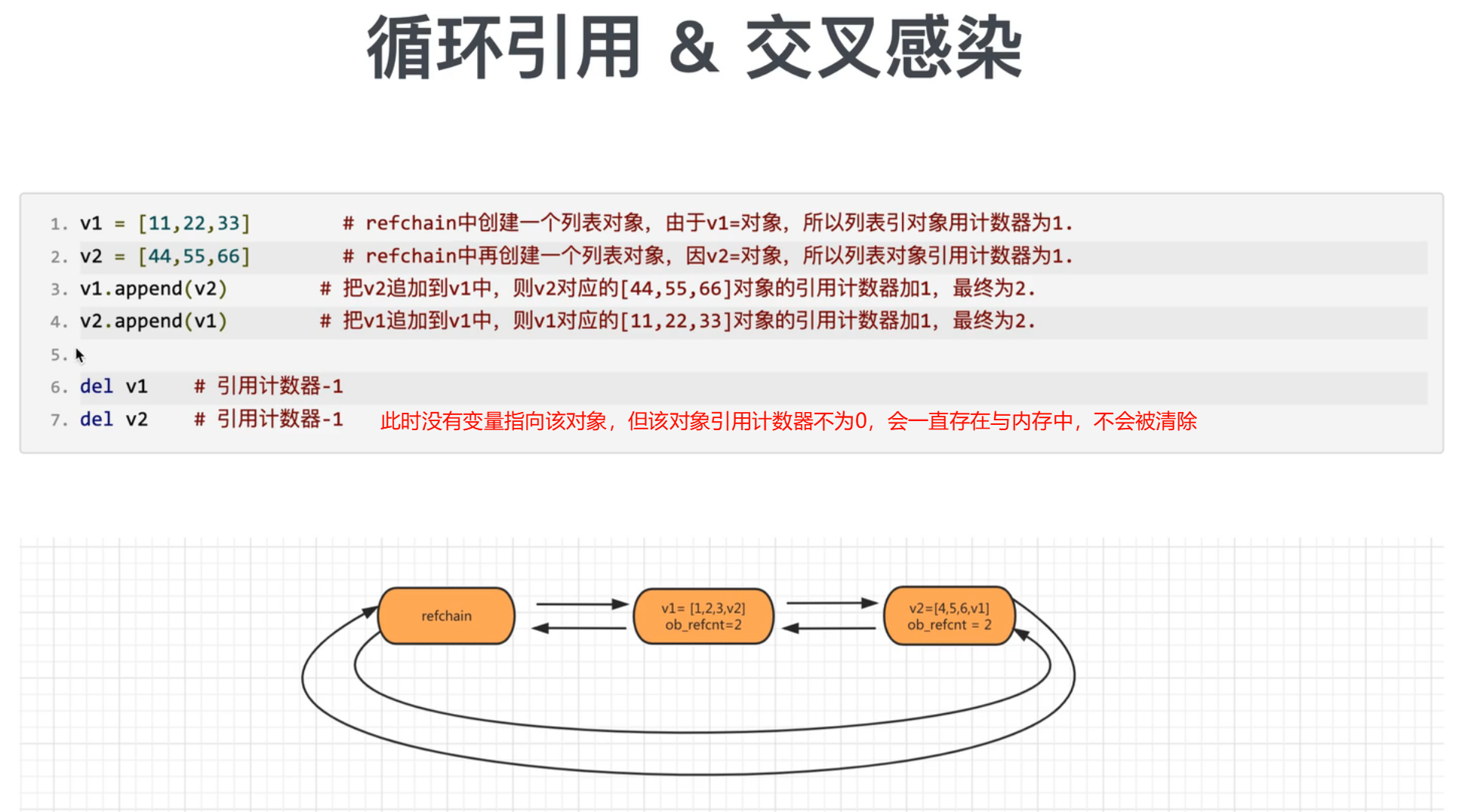
标记清除就是为了解决这个问题的
标记清除
目的:为了解决引用计数器循环引用的不足
实现:在python底层再维护一个链表,链表中专门放那些可能存在循环引用的对象(list/tuple/dict/set)
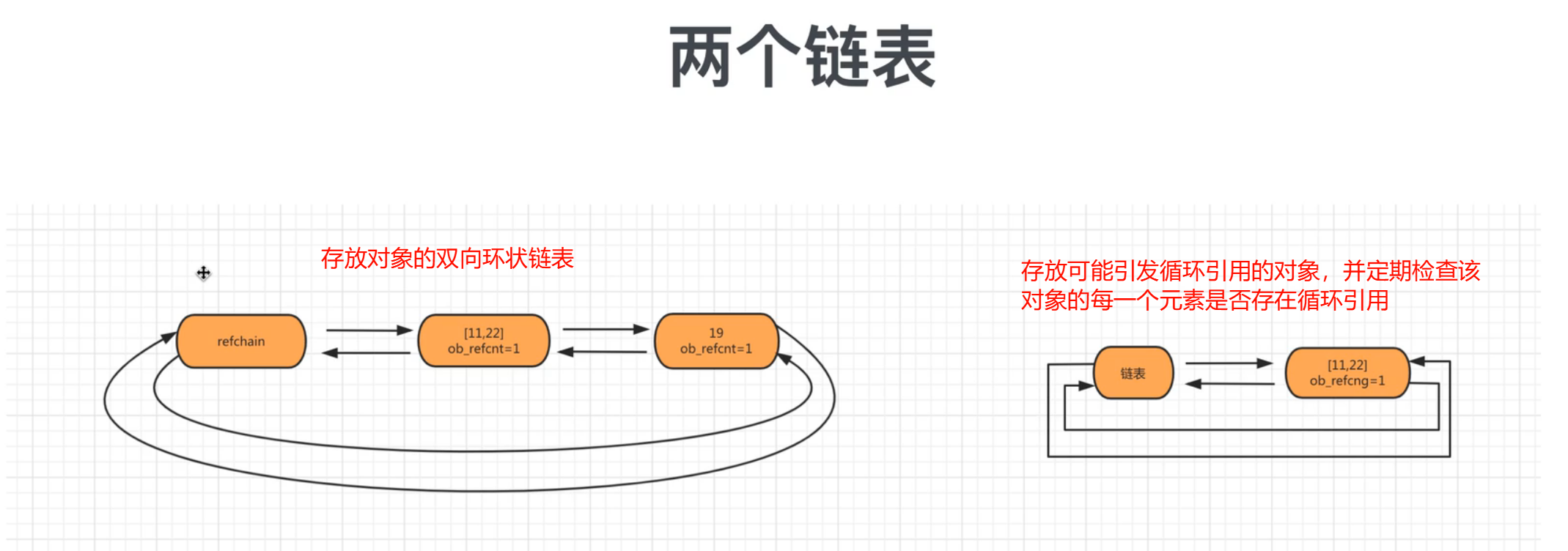
在python内部某种情况下触发,回去扫描可能存在循环应用的链表中的每个元素,检查是否有循环引用。如果有则让双方的引用计数器-1;如果是0则垃圾回收。
问题
- 标记清除什么时候扫描
- 可能存在循环引用的链表扫描代价大,每次扫描耗时久。
从而引出分代回收
分代回收
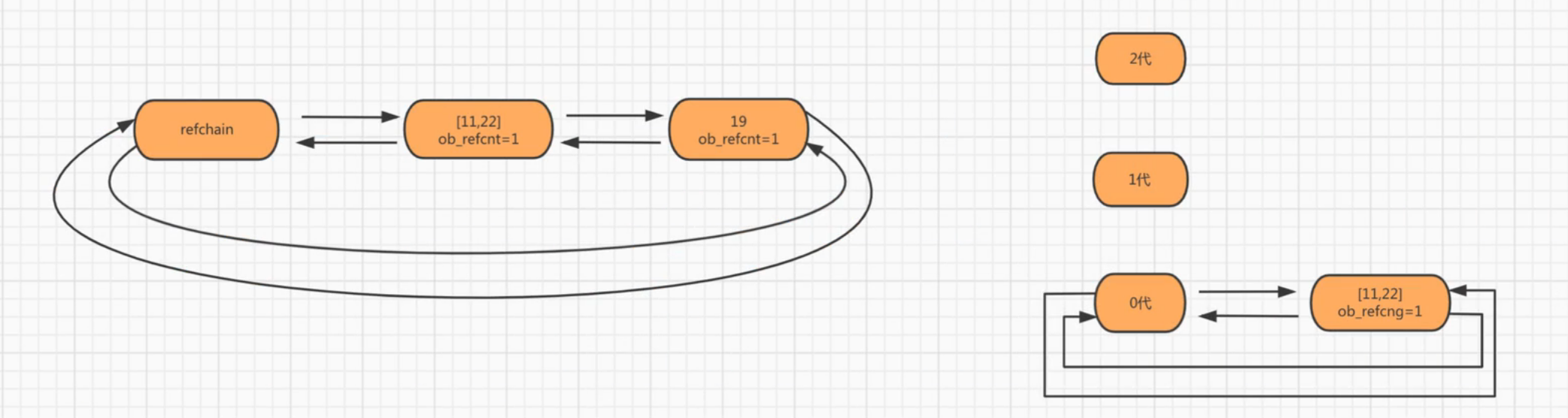
将可能存在循环应用的对象维护成3个链表:
- 0代:0代中对象个数达到700个扫描一次。
- 1代:0代扫描10次,则1代扫描一次。
- 2代:1代扫描10次,则2代扫描一次。
过程
当0代链表中对象个数达到700个会对每个对象中每个元素扫描一次,判断是否存在循环引用。如果有,则引用计数器-1;如果没有,则将其升级为1代,移动到1代的链表中。当0代扫描10次,则1代扫描一次。如果对象不存在循环引用,将其升级为2代,移动到2代的链表中。
缓存机制
python缓存是在上述的流程中提出的优化机制。其中包含池与free_list链表
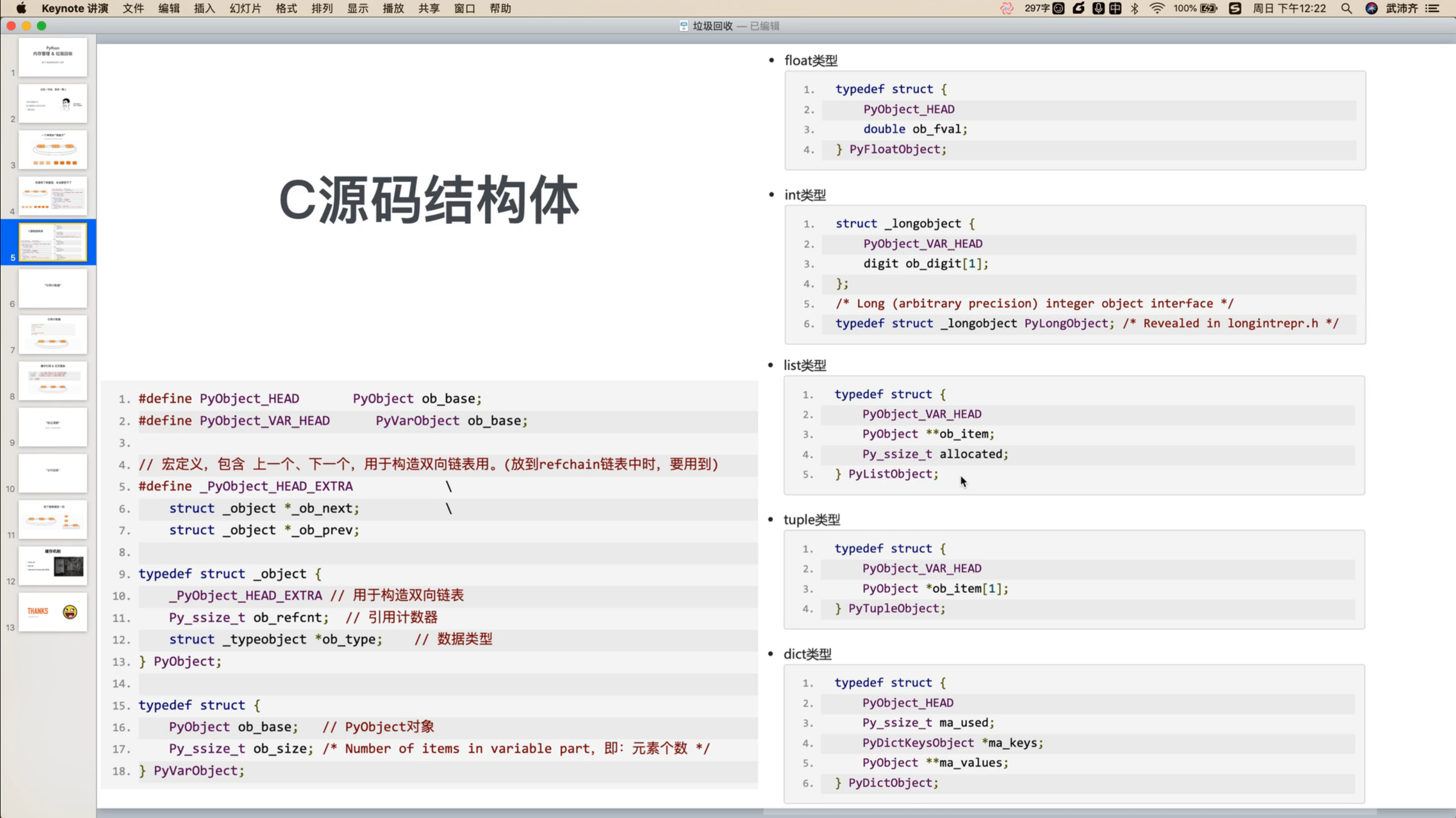
池(int)
为了避免重复创建和销毁一些常见对象,维护池。
# 启动解释器时,python内部帮我们创建:-5、-4、...、257
v1 = 7 # 内部不会开辟内存,直接去池中获取
v2 = 9 # 内部不会开辟内存,直接去池中获取
v3 = 9 # 内部不会开辟内存,直接去池中获取
print(id(v2), id(v3)) # 1862952577584 1862952577584
free_list(float/list/tuple/dict)
一个对象的引用计数器为0时,按理说应该回收,但python不会直接回收,而是将该对象添加到free_list链表中当缓存。以后再去创建对象时,不再重新开辟内存,而是直接使用freelist。
示例
v1 = 3.14 # 开辟内存,内部存储着上述结构体中定义的那几个值,存放到refchain中。
print(id(v1))
del v1 # 从refchain中移除,将对象添加到free_list中
v9 = 999.99 # 当再定义同种类型对象时,不会重新开辟内存,而是去free_list中获取该对象,给该对象初始化,再放到refchain中
print(id(v9))
问题
但经实操发现,上述示例打印结果如下:
2009985228016
2009985227728
AI解释
在 Python 中,当你使用 del 语句删除一个变量时,对象并不一定会立即被添加到 free_list 中并被后续的变量复用。Python 的内存管理机制较为复杂,不是简单地按照上述逻辑严格执行。
虽然理论上 Python 的垃圾回收机制可能会尝试将不再使用的对象放入 free_list 以便后续复用,但实际上这个过程受到多种因素影响,包括垃圾回收的时机、对象的类型和大小等。
另外,即使对象被放入了 free_list,也不能保证下一个创建的相同类型对象一定会从 free_list 中获取该对象。Python 的内存分配器可能会根据当前的内存状态和需求决定是从 free_list 中获取对象还是重新开辟新的内存空间。
所以,在你的代码中看到不同的对象地址是正常现象,不能简单地认为应该从 free_list 中获取对象就一定会得到相同的地址。
小结
垃圾回收
- python的底层是c语言
- python中维护着一个双向环状链表用来存储所创建的对象
- Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。为了解决引用计数器循环引用的不足引入了标记清除(mark and sweep)与分代回收(generation collection)
缓存机制
- 在 Python 中,缓存机制主要是为了提高程序的性能,避免重复计算和重复创建对象。为了避免重复创建和销毁一些常见对象,引出"池"(维护池)这个概念。
- 当一个对象的引用计数器为0时,按理说应该回收,内部不会直接回收,而是将对象添加到free_list链表中当缓存。以后再去创建对象时,不再重新开辟内存,而是直接使用free_list。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号