导入模块
import pandas as pd
案例数据
my_dict = {
'姓名':
['张三','李四','王二','六月','北海'],
'年龄':
[23,27,26,22,18],
'性别':
['男','女','女','男','男'],
'工作':
['剪辑师','蛋糕师','消防员','程序员','辅导员'],
'工龄':
[2,3,3,2,0]}
df = pd.DataFrame(data=my_dict, columns=['姓名', '年龄', '性别', '工作', '工龄'])
df
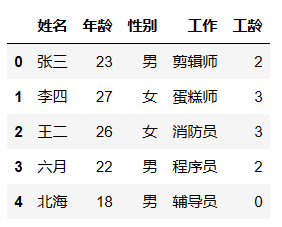
借助索引的筛选
行的筛选
df[1:4] # 筛选出第2行到第4行的数据,左闭右开。
列的筛选
df[['姓名','工作']]

df[['姓名','工作']][1:4]
行与列的筛选
df[1:4][['姓名','工作']] # 等价于:df[['姓名','工作']][1:4]

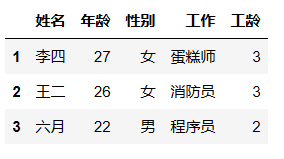
借助.loc函数,标签的筛选
行的筛选
df.loc[2:4] # 筛选出:行标签从2到4所有行数据,左闭右闭。
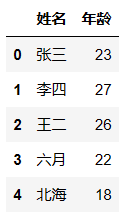
列的筛选
df.loc[:,['姓名','年龄']] # 仅对列筛选
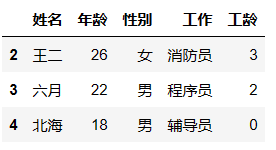
行与列的筛选
df.loc[1:3,['姓名','年龄']] # 第一个参数中:{1:3指的是索引为1~3的行,左闭右闭}。
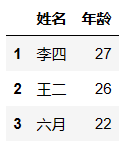
df.loc[[1,2,4],['姓名','年龄']] # 第一个参数中:[1,2,4]代表了指定行的标签。
按照条件筛选行数据
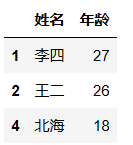
df.loc[df['年龄']==27] # 单纯地按条件筛选。

df.loc[df['年龄']==27, ['工作', '工龄']] # 进一步限制显示的列。

多条件筛选行数据
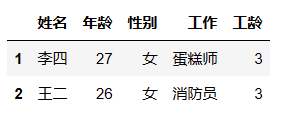
df.loc[(df['年龄']==27) | (df['性别']=='男'), ['工作', '工龄', '性别']]
借助.iloc函数,索引的筛选
行的筛选
df.iloc[1:3] # 左闭右开。行索引从0开始,所以会显示第2行到第3行的数据。
列的筛选
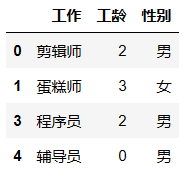
df.iloc[:,1:4] # 列索引从0开始。索引会筛选第2列到第4列的数据。
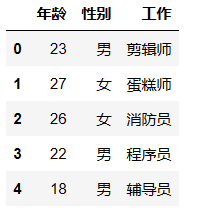
行与列的筛选
df.iloc[1:3,1:4] # 先选择第2行到第3行的数据,在此基础上再筛选第2列到第4列的数据。
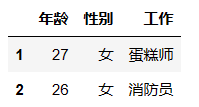
df.iloc[[1,3,4],[2,3]] # 先筛选出索引为1,3,4的行数据,然后在此基础上再筛选出列索引为2和3的列。

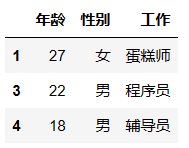
df.iloc[[1,3,4],1:4]
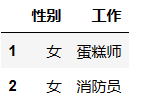
df.iloc[1:3,[2,3]]


 dataframe对数据的筛选
dataframe对数据的筛选

 浙公网安备 33010602011771号
浙公网安备 33010602011771号