

pandas库对数据的读写
 pandas库对数据的读写
pandas库对数据的读写
常用的数据编码格式
utf-8、gbk、gb18030、gbk2312
引入模块
import pandas as pd
import pymysql
from sqlalchemy import create_engine
读取.csv文件代码结构
pd.read_csv(filepath_or_buffer, sep=’ ,’ , header=’infer’, index_col=None, usecols=None, engine=None, skiprows=None, nrows=None)
filepath_or_buffer: 文件地址。
sep: 分隔符,默认‘, ‘。
header: 个人认为这个参数可以不考虑。当没有列名时,会自动将列命名为int列表:0、1、2...;当有列名时显示列名。
usecols: 选定表的列。例:['header1', 'header19']
nrows: 选定表的行数。例:10
index_col: 默认None,将不使用列索引下标。否则,例:['h2','h1''h3']会将原来的['h1','h2','h3']列重新排序。
skiprows: 跳过某些行。例:[1,24,26]
读取.csv数据案例
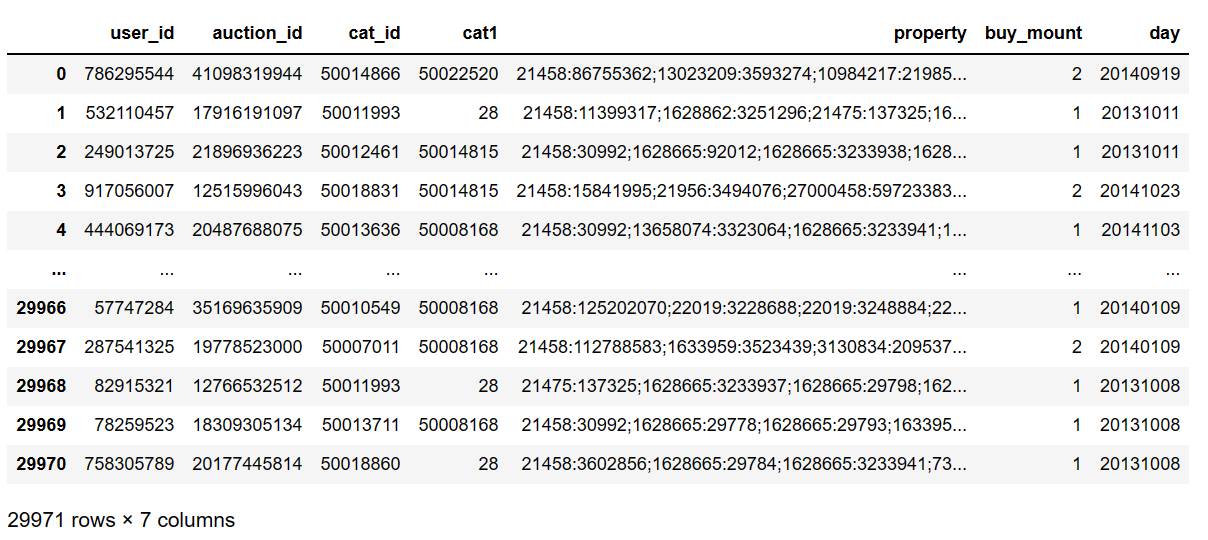
简单的全部读取
pd.read_csv(filepath_or_buffer='baby_trade_history.csv')
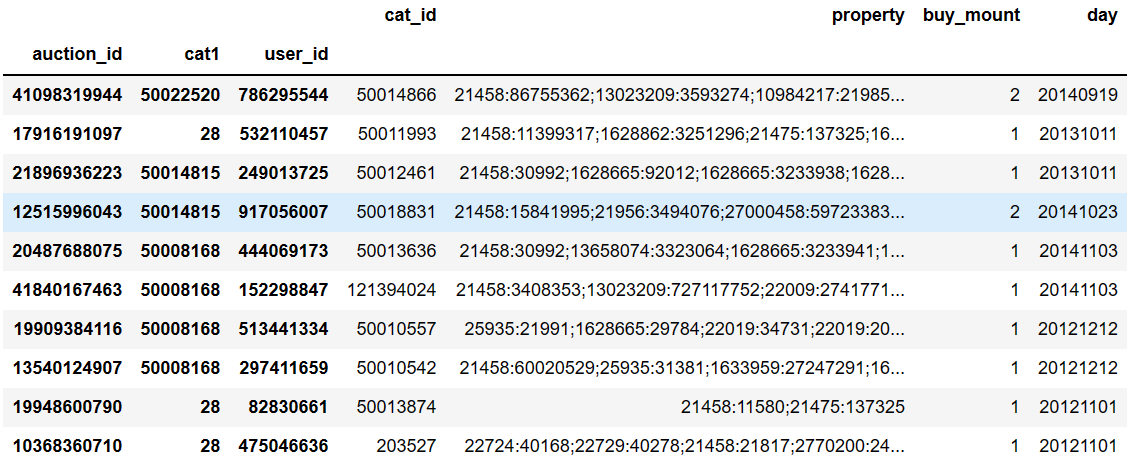
重新排序列
pd.read_csv(filepath_or_buffer='baby_trade_history.csv',nrows=10,index_col=['auction_id','cat1','user_id'])
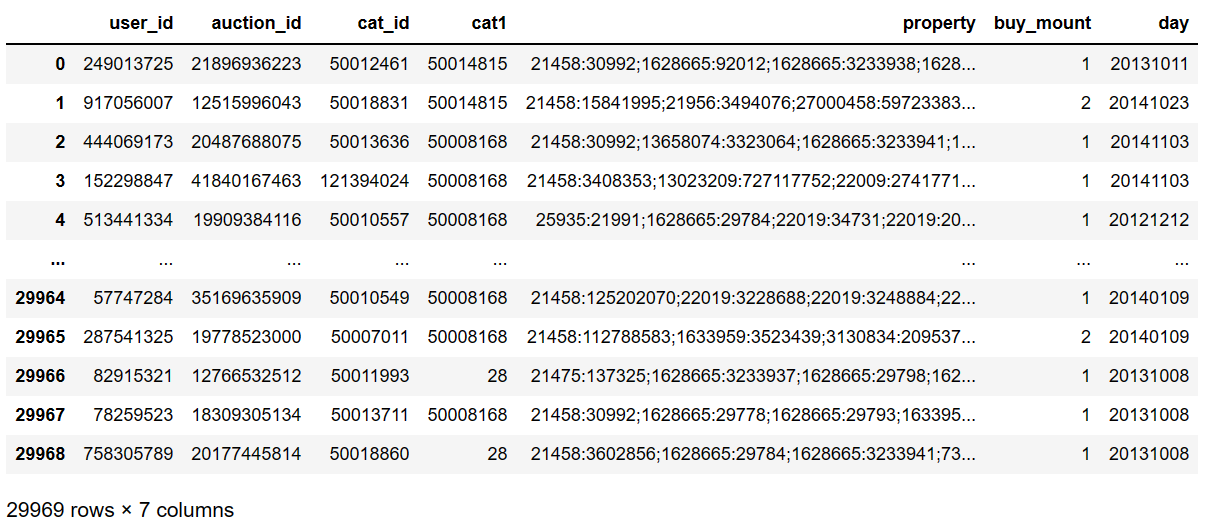
跳过第1、2行
pd.read_csv(filepath_or_buffer='baby_trade_history.csv',skiprows=[1,2])
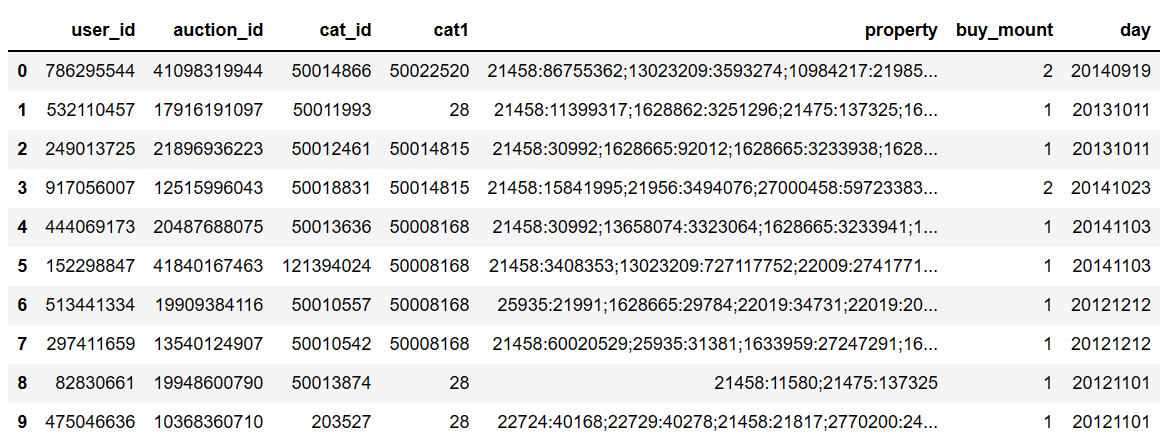
只返回前10行
pd.read_csv(filepath_or_buffer='baby_trade_history.csv',nrows=10)
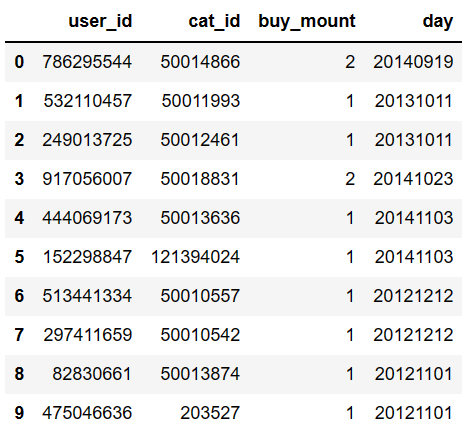
选择特定的列,且只显示前10行
pd.read_csv(filepath_or_buffer='baby_trade_history.csv',usecols=['user_id','cat_id','buy_mount','day'],nrows=10)
dataframe表格保存为.csv文件
df.to_csv('df_to_csv_file.csv',encoding='utf-8',index=False) # index=False表示不显示行索引
读取.xlsx文件代码结构
pd.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
参数讲解地址:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
直接读取.xlsx文件
pd.read_excel(io='meal_order_detail.xlsx')
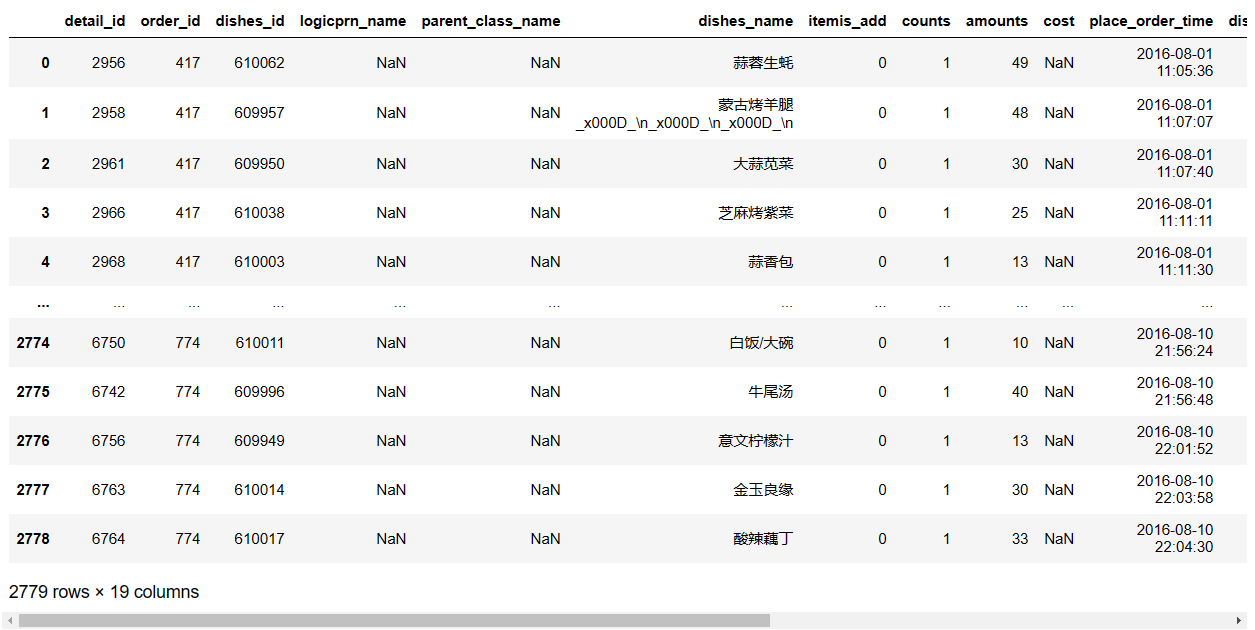
读取.xlsx文件中的指定sheet
pd.read_excel(io='meal_order_detail.xlsx',sheet_name='meal_order_detail2')
pd.read_excel(io='meal_order_detail.xlsx',sheet_name=1)
# 以上两种写法均表示读取第2个sheet,一个通过名称指定,一个通过索引指定。
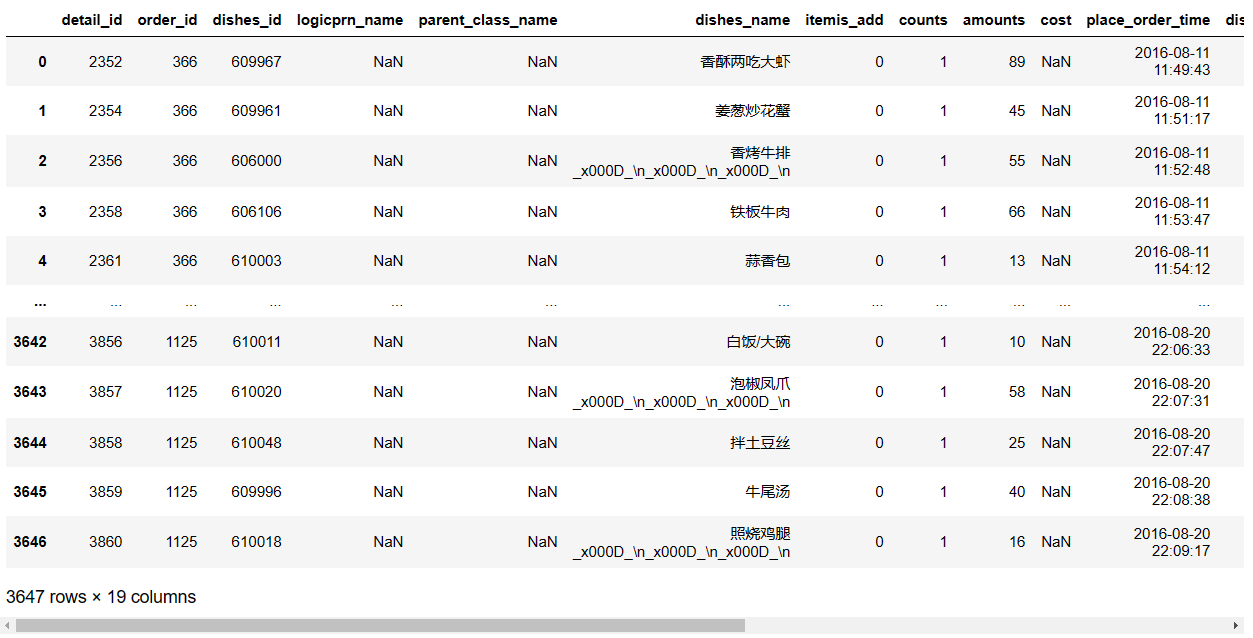
dataframe表格保存为.xlsx文件
df2.to_excel('excel_name.xlsx',sheet_name='sheet_name',index=False) # index=False表示不显示行索引
MySQL数据库的读写
读取数据库中指定表的内容(本地)
userName = 'root'
password = '**********'
dbHost = 'localhost'
dbPort = 3306
dbName = 'test'
conn = f'mysql+pymysql://{userName}:{password}@{dbHost}:{dbPort}/{dbName}?charset=utf8'
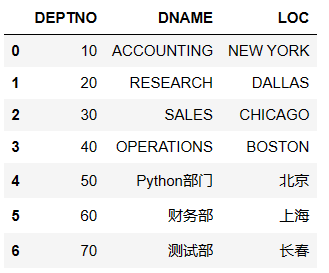
sql = 'select * from dept'
df = pd.read_sql(sql=sql,con=conn)
df
保存表到数据库中(本地)
df.to_sql('new_test', con=conn,index=False,if_exists='replace')
if_exits:
<1>'replace':替代原表。
<2>'append':添加数据。
<3>'fail':如果存在,存入失败。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号