

pandas库中dataframe数据结构的常用方法
 pandas库中dataframe数据结构的常用方法
pandas库中dataframe数据结构的常用方法
文章初衷
本文与文章pandas库中series数据结构的常用方法的总结初衷相同,即将dataframe的数据结构和常用方法提供给包括笔者在内的广大读者,以便大家快捷地使用和参考。dataframe这个数据结构被广泛应用于表的各种操作。在python数据分析中,几乎离不开dataframe这种数据结构。
案例引入包
import numpy as np
import pandas as pd
pandas.core.frame.DataFrame的代码组成
pandas.DataFrame(data,index,dtype,columns)
data:数据可以为list()、np.array()、dict()。
index:索引,其长度必须与数据长度相同。该参数默认行索引:0、1、2、...
dtype:数据类型。
columns:表的列名/列标签。该参数默认列标签:0、1、2、...
pandas.core.frame.DataFrame的创建方式
方式1
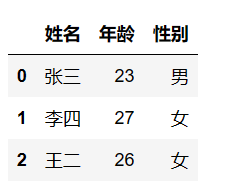
list1 = [['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']]
df1 = pd.DataFrame(data=list1, columns=['姓名', '年龄', '性别'])
df1
方式2
df2 = pd.DataFrame(data={'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']})
df2
方式3
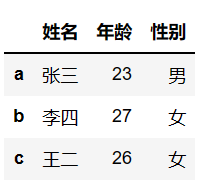
array1 = np.array([['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']])
df3 = pd.DataFrame(data=array1, columns=['姓名', '年龄', '性别'], index=['a','b','c'])
df3
方式N
# 在满足dataframe数据结构规则的情况下,创建所需的dataframe结构
获取行索引标签/行标题
df3.index
Index(['a', 'b', 'c'], dtype='object')
df3.index.tolist()
['a', 'b', 'c']
获取列标签/列标题
df3.columns
Index(['姓名', '年龄', '性别'], dtype='object')
df3.columns.tolist()
['姓名', '年龄', '性别']
获取dataframe表的各种信息
表的维度
df3.ndim
2
表的形状
df3.shape
(3, 3)
表的元素个数
df3.size
9
表中每列的数据类型
df1.dtypes
姓名 object
年龄 int64
性别 object
dtype: object
df2.dtypes
姓名 object
年龄 int64
性别 object
dtype: object
df3.dtypes
姓名 object
年龄 object
性别 object
dtype: object
强调事项
关于表的数据类型
- 问题的提出:虽然以上3种创建dataframe的表类似,但每列的数据类型会被承载它们的容器影响。
- 举个例子:df3的'年龄'这个列标签,由于承载它的容器是一个numpy数组,返回成表时被默认为object类型。而其他两种创建方式均将该列标签的数据类型默认成int64。
- 强烈建议:为了表格能够更准确地标注其数据类型,建议使用创建df2的方法。即使用
dict()作为容器创建dataframe。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号