正则表达式拾遗
1. 分组多次匹配
我们在正则表达式中使用"()"括号进行匹配,但是如果在括号里面使用"+"符合,那么分组只会匹配最后一次的匹配的结果。
例如:
正则表达式:
([abc]+.)+
测试字符串:
abcdabceabcfabcgggg
匹配的分组结果是:abcg
如图:
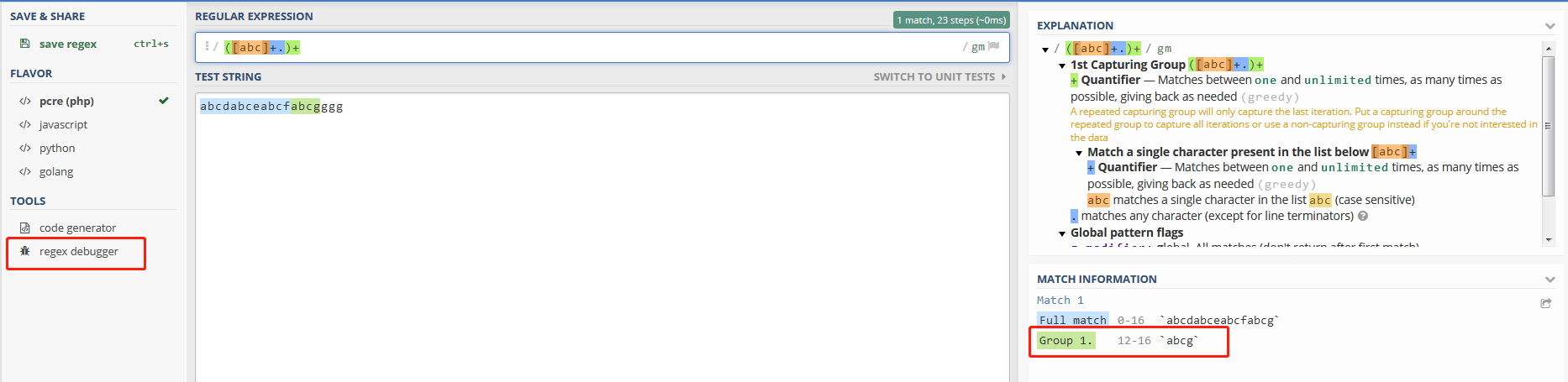
点击左侧的"Regex Debugger",可以看到程序的匹配过程:
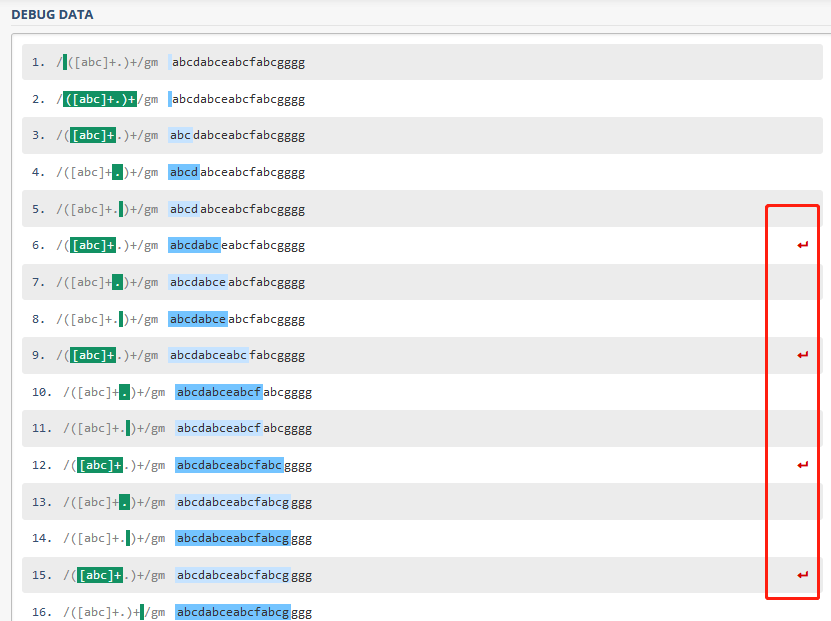
我们可以在右边看到4次的Backtrack,关于Backtrack的问题,我们稍后讲述。
2. 回溯的问题(Backtrack)
因为功能更加强大,大部分语言对正则表达式的实现使用的是NFA(Non-deterministic finite automaton不确定型有穷自动机),而不是DFA自动机。
2.1 NFA中的回溯问题
我们举一个例子:
正则表达式:
a{1,3}.
测试字符串:
aaa
regex debug的过程是:

因为正则表达式默认使用的是贪婪模式,所以a总是希望尽可能的匹配,我们在上图中的第2行可以看出这一点,但是我们看到在第3行那里产生了一次Backtrack,因为如果a匹配3次的话,那么后面的.无法匹配,因为解析器指针往前面走,只匹配2次a,然后将最后的a用于匹配.。
正则表达式不宜出现大量的"Blacktrack",因为这样比较消耗系统资源,容易出现CPU占用100%的情况。
2.2 三种模式:贪婪模式、懒惰模式、独立模式
贪婪模式
正则表达式模式使用的就是贪婪模式,也就是尽可能多的匹配,正如前面2.1举的例子那样,字符a是尽可能多的匹配。
懒惰模式
懒惰模式刚好和贪婪模式相反,就是尽可能少的匹配,我们还以2.1的例子为例。
正则表达式:
a{1,3}?.
测试字符串:
aaa
匹配结果是:
aa
因为第一个a匹配的是a{1,3}?,第二个a匹配的是.
独立模式
独立模式就是咋贪婪模式的基础上,删除了回溯功能(Blacktrack),例如:
正则表达式:
a{1,3}+.
测试字符串:
aaa
aaab
匹配结果:

大家可能惊讶aaa没有被成功匹配,原因是:当a{1,3}+进行尽可能多匹配的时候,就已经把aaa匹配上了,但是字符串至此已经结束,导致.无法匹配,因此导致最后aaa无法成功匹配。相反,aaab已经匹配了a{1,3}+后,b刚好可以用于.的匹配,因此aaab成功匹配。
备注:
?:表示以懒惰模式匹配
+:表示以独立模式匹配

 浙公网安备 33010602011771号
浙公网安备 33010602011771号