
前面学习的无监督学习模型:降维
另一种无监督学习模型:聚类算法。
聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型。
最简单最容易理解的聚类算法可能是 k-means聚类算法了。
k-means简介
在不带标签的多维数据集中 寻找确定数量 的簇。
最优的聚类结果需要符合以下俩个假设:
- 簇中心点 cluster center 是属于该簇的所有数据点坐标的算术平均值
- 一个簇的每个点到该簇中心点的距离 比 到其他簇中心点的距离 短。
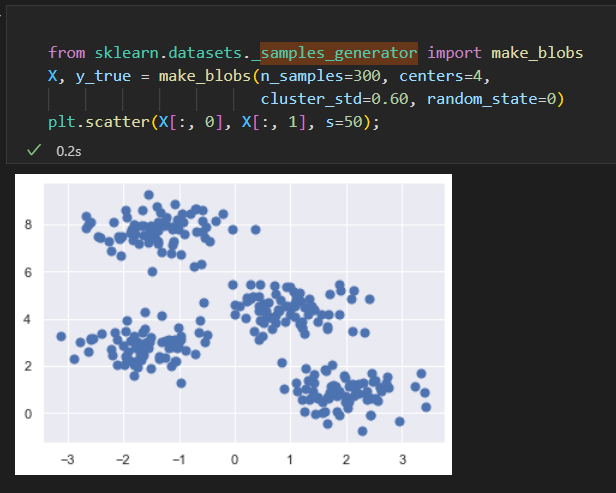
原始数据,包含4个明显的簇
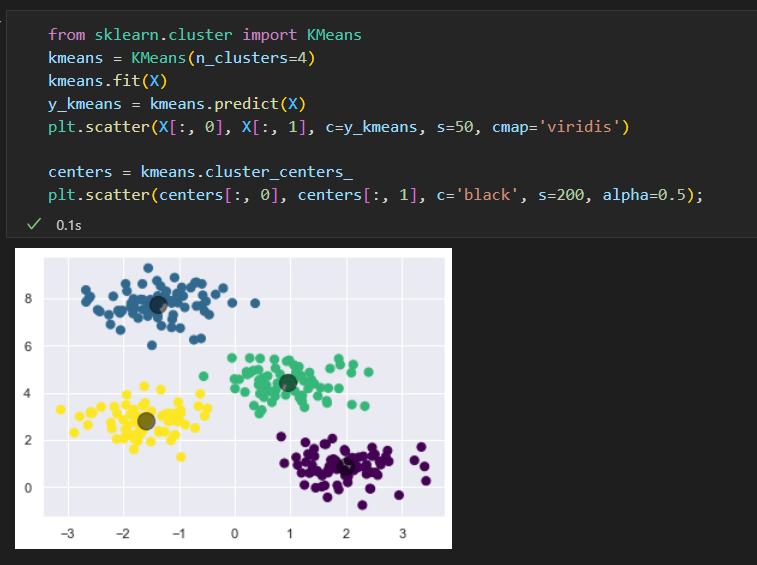
评估器拟合数据:
高斯混合模型
k-means的非概率性和它仅根据到簇中心点的距离来指派簇的特点将导致性能底下。
高斯混合模型被看作是k-means思想的一个扩展。也是一种非常强大的聚类评估工具。
可以通过比较每个点 与 所有 簇中心 点的距离来度量 簇分配 的不确定性。而不仅仅是关注最近的簇。
通过将簇的边界由圆形 放宽值椭圆型,从而得到非圆形的簇。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号