
朴素贝叶斯模型
朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集。因为运行速度快,可调参数少。是一个快速粗糙的分类基本方案。
naive Bayes classifiers
贝叶斯分类
朴素贝叶斯分类器建立在贝叶斯分类方法的基础上。数学基础是贝叶斯定理。 一个描述统计量条件概率关系的公式。
在贝叶斯分类中,我们希望确定一个具有某些特征的样本 属于 某类标签的概率。 通常记为 P(L|特征)
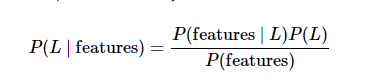
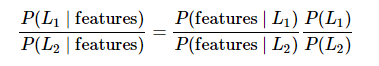
需要确定俩种标签,定义为L1和L2. 计算俩个标签的后验概率的比值
现在需要一种模型。帮我们计算每个标签的P(特征|Li).这种模型被称为生成模型。
因为它可以训练处生成输入数据的假设随机过程(概率分布)
为每中标签设置生成模型 是贝叶斯分类器训练过程的主要部分。
之所以称为朴素 。是因为 如果对每种标签的生成模型进行非常简单的假设,就能找到每种类型 生成模型的近似解,然后就可以使用贝叶斯分类。
不同类型的朴素贝叶斯分类器是有对数据的不同假设决定的。
高斯朴素贝叶斯
Gaussian naive Bayes 。 假设每个标签的数据都服从简单的高斯分布。
原始数据如下:
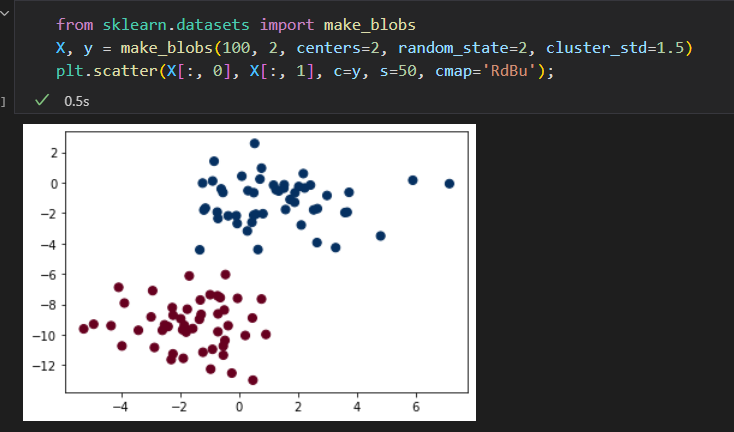
假设数据服从高斯分布,且变量无协方差 (线性无关)
只需要找出每个标签的所有样本点均值 和 标准差。再定义一个高斯分布。就可以拟合模型了。
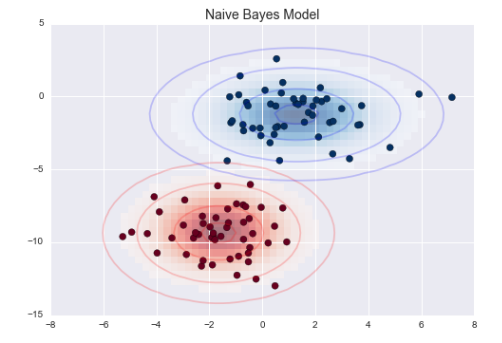
每个椭圆曲线表示每个标签的高斯生成模型。 越靠近椭圆中心的可能性越大。
通过每种类型的生成模型,可以计算出任意数据点的似然估计 P (特征|L1) 。
然后根据贝叶斯定理计算出 后验概率比值, 从而确定每个数据点可能性最大的标签。
评估器 GaussianNB实现:
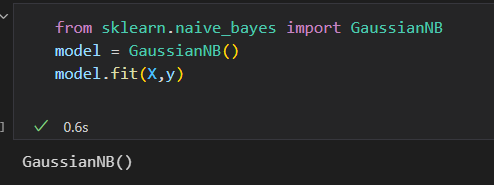
预测标签:
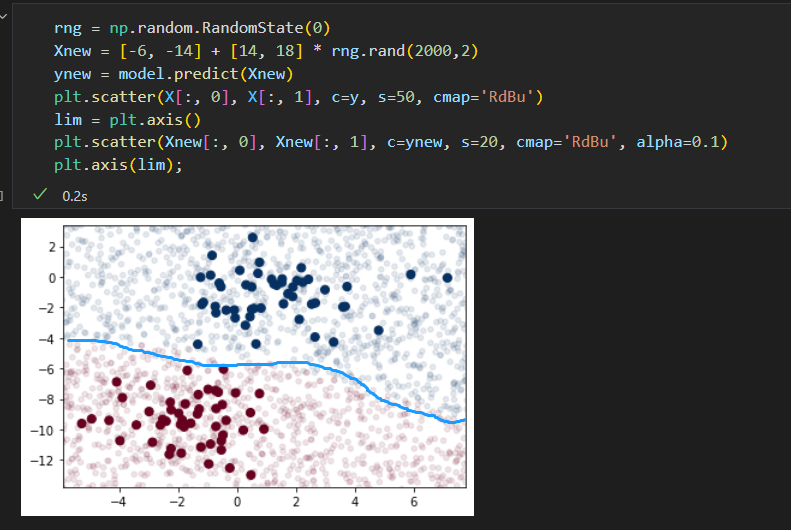
可以在分类结果中看到一条稍显 弯曲 的边界
通常:高斯朴素贝叶斯的边界 是二次方曲线。
多项式朴素贝叶斯
假设特征是由一个简单多项式分布 生成的。 多项分布式可以描述 各种类型样本 出现次数的概率。
- 文本分类
特征:分类文本的单词出现次数。
执行了15分钟。。。淦。
![image]()
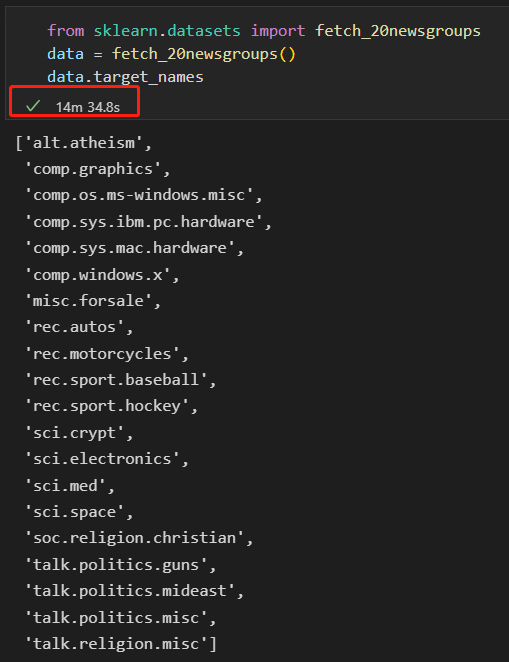
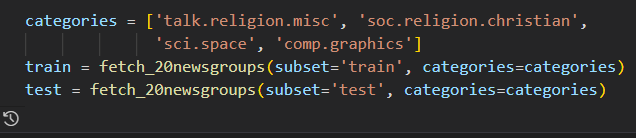
选择四类新闻,下载训练集和测试集
看其中一篇新闻:

为了让这些数据能用于机器学习,需要将每个字符串的内容转换成数值向量。
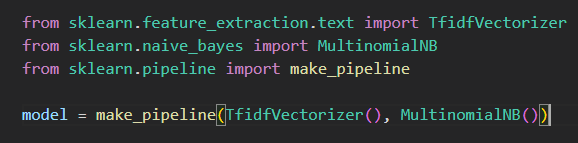
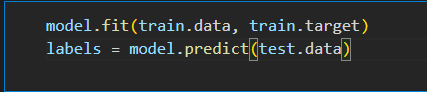
将模型应用到训练数据上。
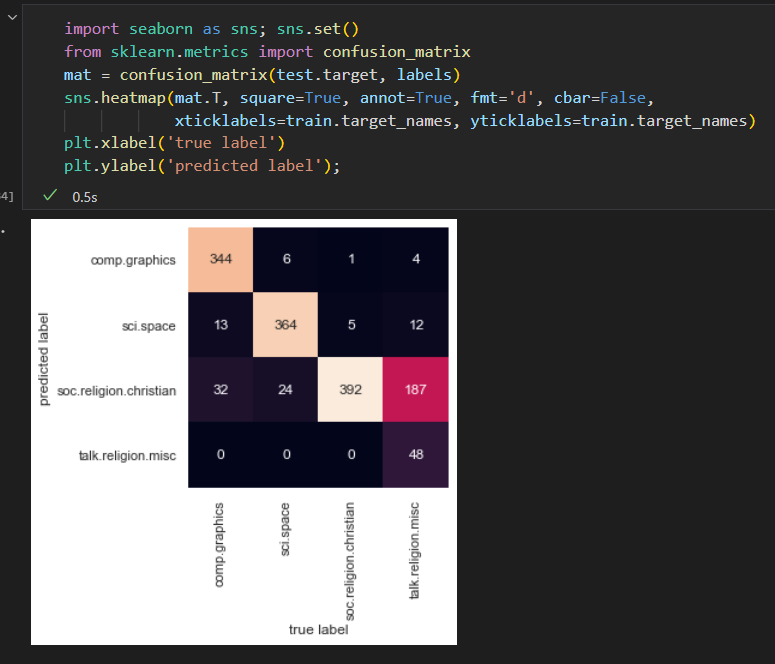
用混淆矩阵 统计 结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号