
模型验证 model validation 就是在选择 模型 和 超参数 之后。通过对训练数据进行学习。对比模型对 已知 数据的预测值和实际值 的差异。
错误的模型验证方法。
用同一套数据训练 和 评估 模型。 准确率总是100% 。
模型验证正确方法: 留出集。
从训练模型的数据中留出一部分。用这部分数据来验证模型的性能。
使用train_test_split 工具。
交叉检验
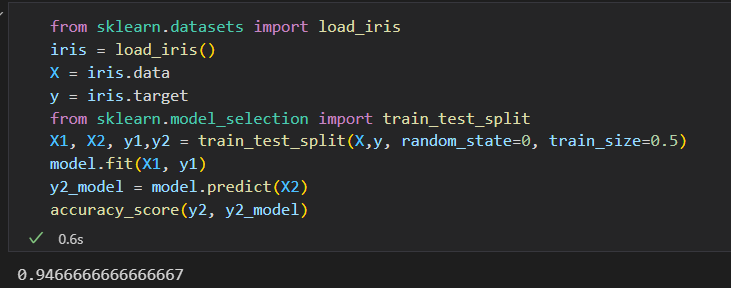
用留出集进行模型验证有一个缺点,就是模型失去了一部分训练机会。有一半数据都没有为模型训练做出贡献。
每个子集既是训练集,也是验证集。
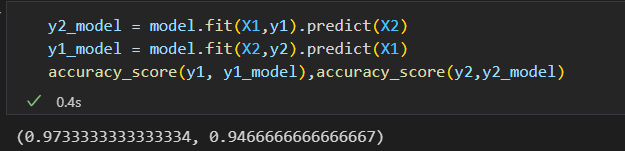
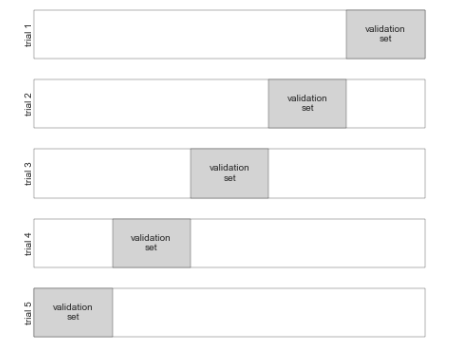
这就是俩轮交叉校验。 扩展一下,实现更多轮交叉校验。
使用cross_val_score 可以非常简单的实现。
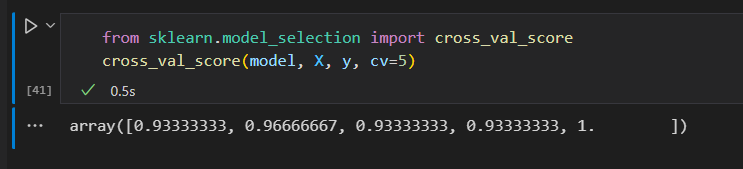
极端情况,只留一个样本左测试。这种交叉检验类型模型被称为 LOO leave-one-out .
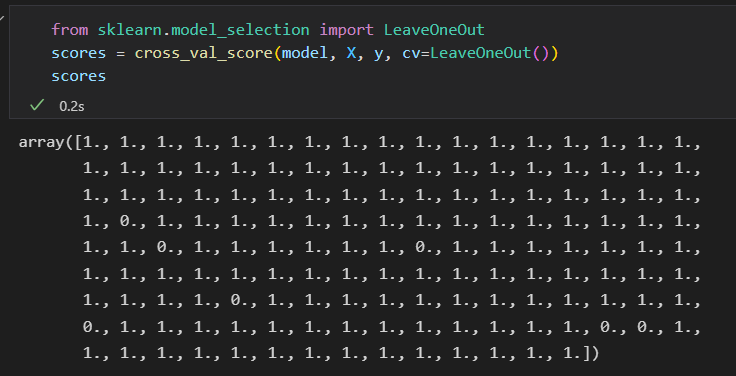
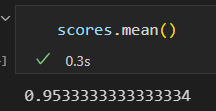
选择最优模型
如何选择模型和超参数
-
偏差与方差的均衡
“最优模型”的问题 基本可以看出是找出偏差 与方差平衡点的问题。 -
欠拟合
希望从数据中找到一条直线,但由于数据本质上比直线要复杂, 也就是说模型没有足够的灵活性来适应数据的所有特征。
也叫高偏差。
![]()
-
过拟合
希望用高阶多项式拟合数据,有足够的灵活性,完美地适应数据的所有特征。 十分准确的描述了训练数据,也过多的学习了数据的噪音。适应数据所有特征的同时,也适应了随机误差,
也叫高方差
![]()
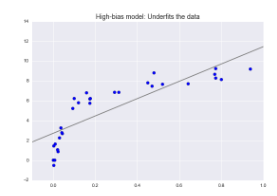
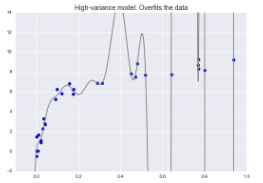
对于高偏差模型:模型在验证集的表现与训练集的表现类似
对于高方差模型:模型在验证集的表现远远不如训练集的表现。
如果我们有能力不断调整模型的复杂度,那么希望训练得分和验证得分如下
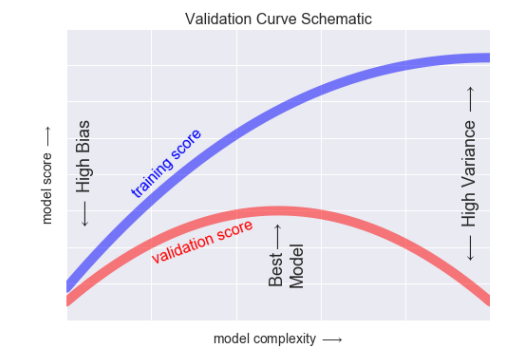
Scikit-Learn 验证曲线
用交叉校验计算一个模型的验证曲线。 用多项式 回归 模型。 多项式的次数是一个可调参数。
一次多项式: y = ax + b
三次多项式: y = ax^3 + bx^2 + cx + d
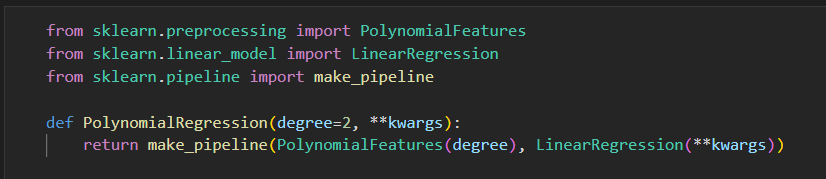
在Scikit-Learn 中,可以用一个带多项式预处理器 的 简单线性回归模型实现。
用一个管道命令 来组合 这 俩种操作。
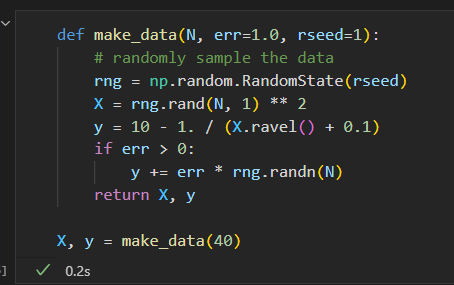
创建一些数据 给模型 拟合
数据可视化,将不同次数的多项式拟合曲线画出来
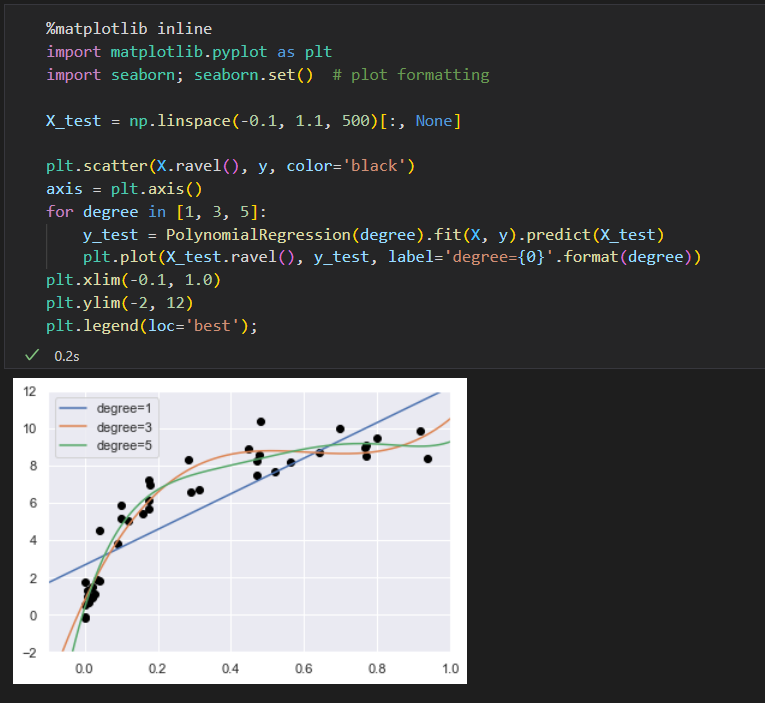
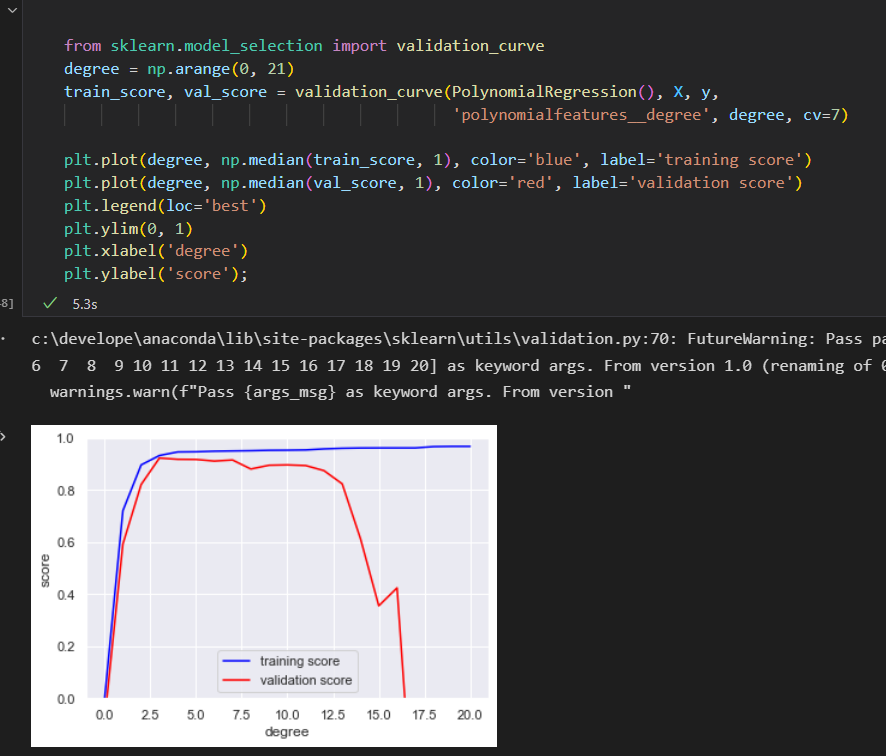
问题:究竟多项式的次数是多少,才能在 偏差 和 方差 间达到平衡。
可以通过可视化验证曲线来找答案。
利用Scikit-Learn的 validation_curve函数 可以非常简单的实现。 只提供模型、数据、参数名称和验证范围信息。
函数就会 自动计算验证范围 内的训练得分 和 验证得分。
学习曲线
英雄模型复杂度的另一个重要因素就是 最优模型 往往受到 训练数据量 的影响。
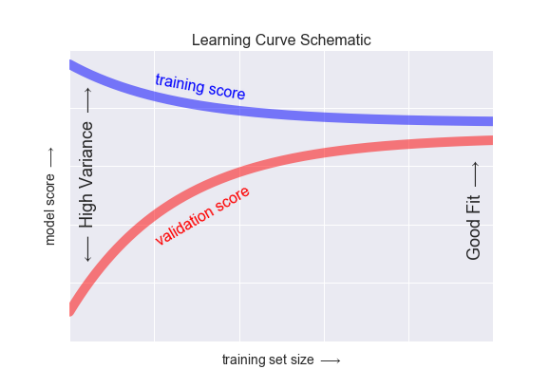
学习曲线的特征:
- 特定复杂度的模型 对较小的数据集 容易 过拟合:此时 训练得分较高,验证得分较低。
- 特定复杂度的模型 对较大的数据集 容易 欠拟合:随着数据的增大,训练得分会不断降低, 验证得分会不断升高。
- 模型的验证集得分永远不会高于 训练集得分: 俩条曲线一直在靠近,不会交叉
![]()
学习曲线最重要的特征,随着训练样本数量的增加,分数会收敛到定值,因此,一旦训练数据已经使模型收件,再增加训练数据 也无济于事, 只能通过换模型。
验证时间:网格搜索
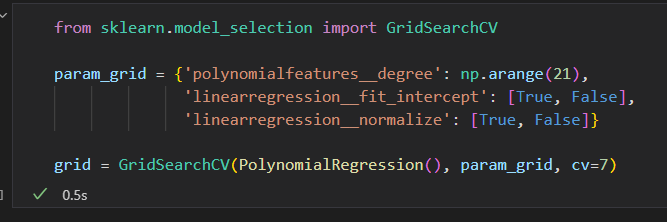
Scikit-Learn在grid_search提供了一个自动化工具来寻找最优多项式的回归模型。
GridSearchCV元评估器来设置这些参数。
然后调用fit()方法在每个网格上拟合模型。并同时记录每个点的得分
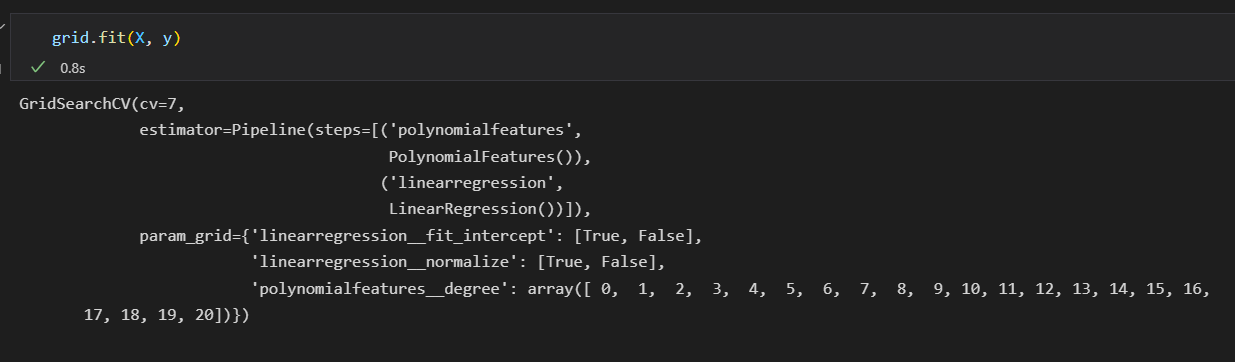
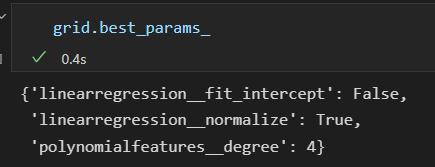
获取最优参数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号