
Numpy 的基本能力之一是快速对每个元素进行运算
Pandas 继承了Numpy的功能,也实现了一些高效技巧。
- 对于1元运算,(函数,三角函数)保留索引和列标签
- 对于2元运算,(加法,乘法),Pandas 会自动对齐索引进行计算。
通用函数:保留索引
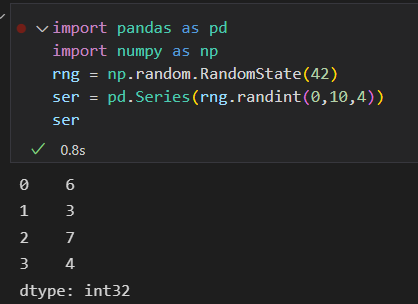
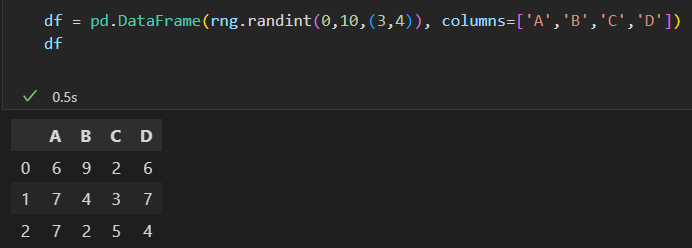
对ser对象或 df对象使用Numpy通用函数,生成的结果是另一个保留索引的Pandas对象。
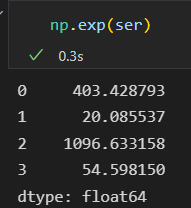
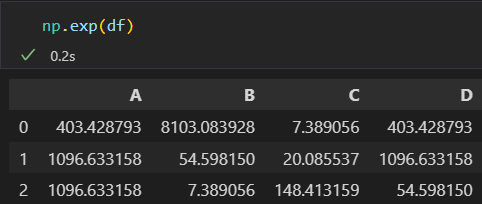
通用函数: 索引对齐
当Series 或 DataFram对象进行二元计算,会对齐俩个对象的索引
当处理不完整的额数据时,这一点非常方便
Series索引对齐
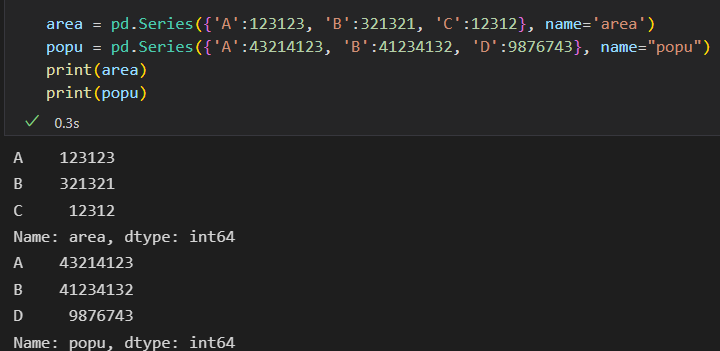
俩个相除
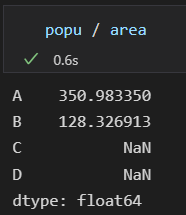
结果数组索引是:俩个输入数组索引的并集,
对于确实位置的数据,Pandas会用NaN填充,表示此处无数。
DataFrame索引对齐
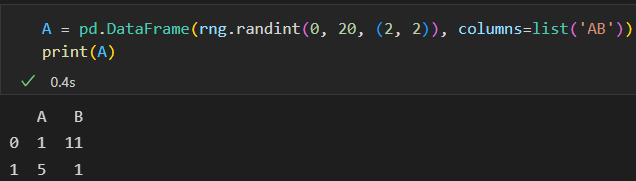
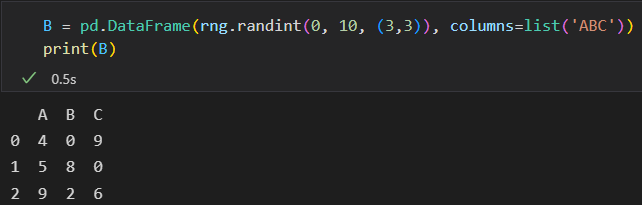
A + B
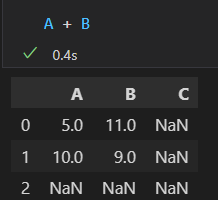
行列索引的顺序可以不同。结果的索引会自动按顺序排列。
可以通过fill_value 参数自定义缺失值,注意:fill_value填充在A上,然后与B相加,不是运算之后再填fill_value.
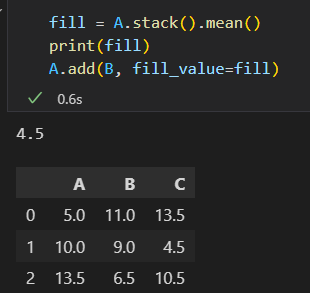
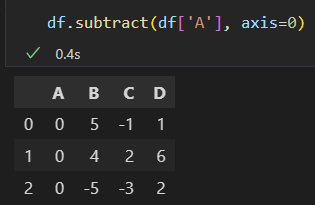
DataFrame 与 Series的运算
需要对一个DataFrame和一个Series运算,行列对齐方式与之前类似, 与Numpy 二维数组与一维数组的运算规则是一样的。
广播。
numpy 二维数组和一维数组计算
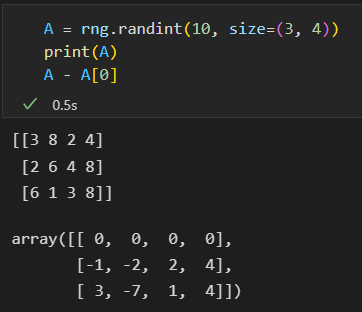
默认按行运算。
Pandas也是默认按行运算
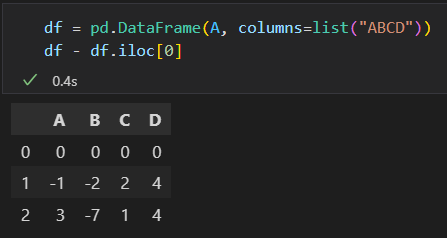
按列计算,使用axis参数。
处理缺失值
缺失值三种形式:null NaN NA
识别缺失值的方法:
1)覆盖全局的掩码
2)用一个标签值
Pandas的缺失值
综合考量:Pandas最终选择标签方法表示缺失值。 浮点数据类型的NaN值,以及None对象。
- None: Python对象类型的缺失值
由于None是一个Python对象,所以不能作为任何Numpy/Pandas数组类型的缺失值。
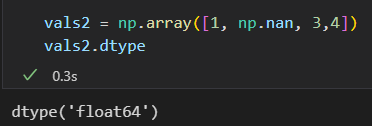
Python中没有定义None和整数之间的加法运算 - NaN:数值类型的缺失值
NaN: not a number. 任何系统中都兼容的特殊浮点数
![image]()
NaN是一个数据类病毒,会同化和它接触的数据, 进行何种操作,结果都是NaN
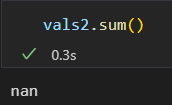
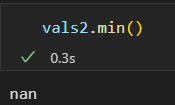
Numpy也提供了特殊的累计函数,可以忽略缺失值的影响
np.nansum() nanmin() nanmax()
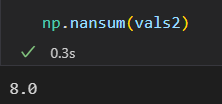
处理缺失值
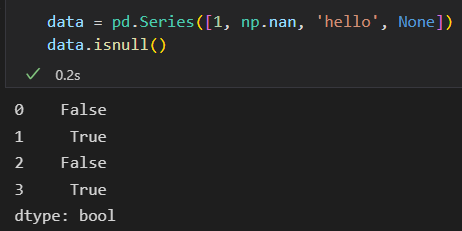
- 发现缺失值 isnull() notnull()
![image]()
isnull() 创建一个布尔类型的掩码标签 缺失值
![image]()
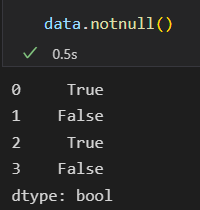
notnull() 与 isnull()相反
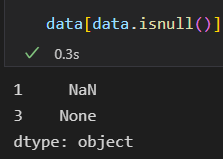
布尔类型掩码数组可以直接作为Series或DataFrame的索引使用
-
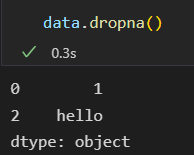
剔除缺失值 dropna()
![image]()
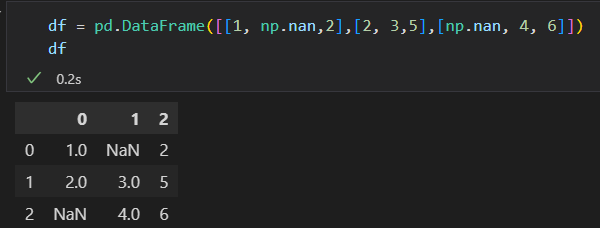
DataFrame 不太一样哦。
![image]()
我们没法从datafram单独剔除一个值。要么是整行,要么是整列。
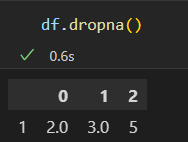
dropna()会剔除任何包含缺失值的整行数据
![image]()
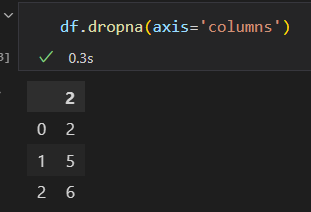
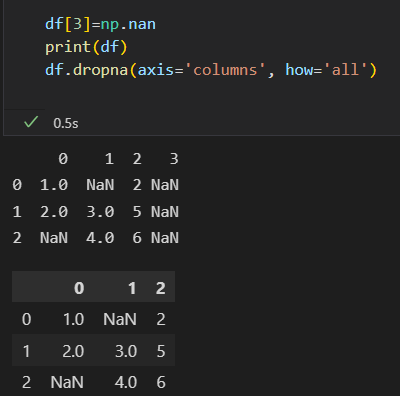
剔除列,axis=1 or axis = 'columns'
![image]()
行或列全部是缺失值 剔除使用how=any,
![image]()
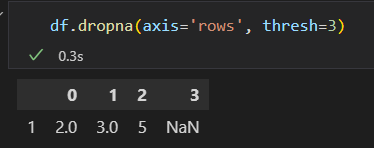
根据缺失值的数量 使用thresh 参数, 行或列中非缺失值的最小数量
![image]()
-
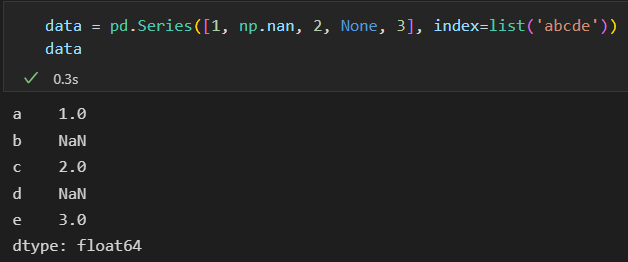
填充缺失值 fillna()
![image]()
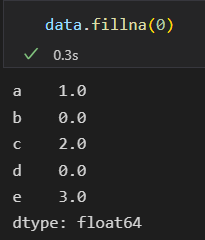
使用0来填充缺失值
![image]()
从前往后填充
![image]()
从后往前填充
![image]()
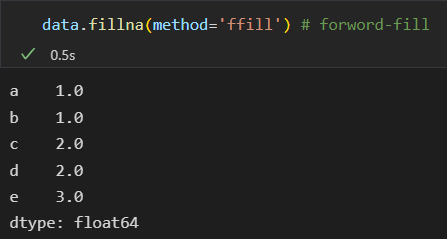
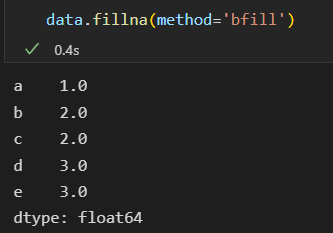
DataFrame一行。只是需要设置坐标轴参数
axis=1 代表行。
axis=0 代表列。 我去。。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号