
【Paper】Deep & Cross Network for Ad Click Predictions
背景
探索具有预测能力的组合特征对提高CTR模型的性能十分重要,这也是大量人工特征工程存在的原因。但是数据高维稀疏(大量离散特征one-hot之后)的性质,对特征探索带来了巨大挑战,进而限制了许多大型系统只能使用线性模型(比如逻辑回归)。线性模型简单易理解并且容易扩展,但是表达能力有限,对模型表达能力有巨大作用的组合特征通常需要人工不断的探索。深度学习的成功激发了大量针对它的表达能力的理论分析,研究显示给定足够多隐藏层或者隐藏单元,DNN能够在特定平滑假设下以任意的精度逼近任意函数。实践中大多数函数并不是任意的,所以DNN能够利用可行的参数量达到很好的效果。DNN凭借Embedding向量以及非线性激活函数能够学习高阶的特征组合,并且残差网络的成功使得我们能够训练很深的网络。
相关工作
由于数据集规模和维度的急剧增加,为了避免针对特定任务的大规模特征工程,涌现了很多方法,这些方法主要是基于Embedding和神经网络技术。
- FM将稀疏特征映射到低维稠密向量上,通过向量内积学习特征组合,也就是通过隐向量的内积来建模组合特征。
- FFM在FM的基础上引入Field概念,允许每个特征学习多个向量,针对不同的Field使用不同的隐向量。
- DNN依靠神经网络强大的学习能力,能够自动的学习特征组合,但是它隐式的学习了所有的特征组合,这对于模型效果和学习效率可能是不利的。
遗憾的是FM和FFM的浅层结构限制了它们的表达能力(两者都是针对低阶的特征组合进行建模),也有将FM扩展到高阶的方法,但是这些方法拥有大量的参数产生了额外的计算开销。Kaggle竞赛中,很多取胜的方法中人工构造的组合特征都是低阶的,并且是显性(具有明确意义)高效的。而DNN学习到的都是高度非线性的高阶组合特征,含义难以解释。是否有一种模型能够学习有限阶数的特征组合,并且高效可理解呢?本文提出的DCN就是一种。W&D也是这种思想,组合特征作为线性模型的输入,同时训练线性模型和DNN,但是该模型的效果取决于组合特征的选择。
主要贡献
交叉网络是个多层网络,能够有效的学习特定阶数的特征组合,特征组合的最高阶数取决于网络层数。通过联合(jointly)训练交叉网络和DNN,DCN保留了DNN捕获复杂特征组合的能力。DCN不需要人工特征工程,而且相对于DNN来说增加的复杂度也是微乎其微。实验表明DCN在模型准确度和内存使用方面具有优势,需要比DNN少一个数量级的参数。
- 支持稀疏、稠密输入,能够高效的学习特定阶数限制下的特征组合以及高阶非线性特征组合,并且不需要人工特征工程,拥有较低的计算开销;
- 交叉网络简单有效,特征组合的最高阶数取决于网络层数,网络中包含了1价到特定阶数的所有项的组合并且它们的系数不同;
- 节省内存并且易于实现,拥有比DNN低的logloss,而且参数量少了近一个数量级。
核心思想
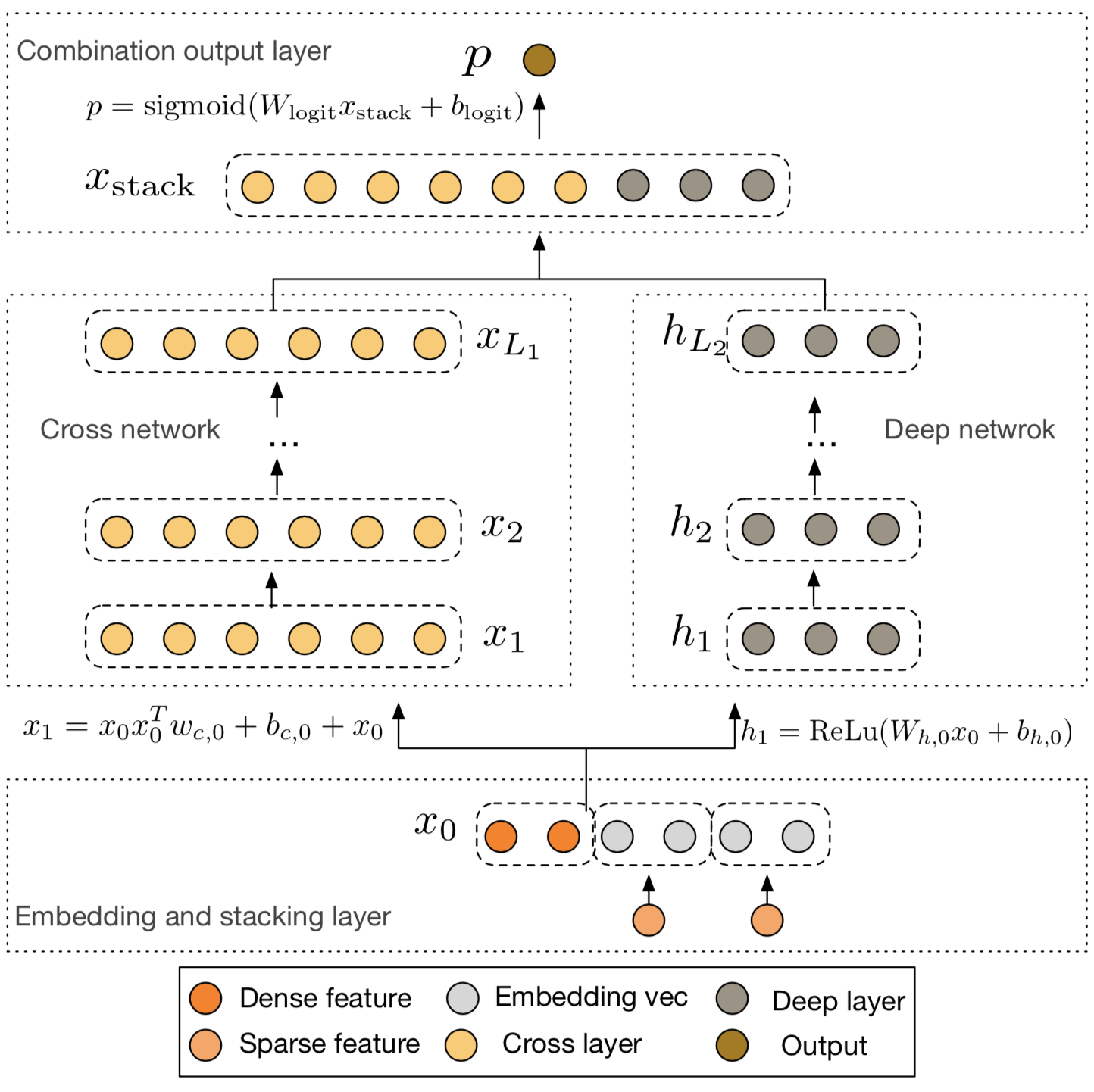
Embedding和Stacking层
模型的输入大部分是类别特征,这种特征通常会进行one-hot编码,这就导致了特征空间是高维稀疏的(比如ID特征经过one-hot编码之后)。为了降低维度,通常会利用Embedding技术将这些二值特征转变成实值的稠密向量(Embedding向量)。Embedding过程用到的参数矩阵会和网络中的其它参数一块进行优化。最后将这些Embedding向量和经过归一化的稠密特征组合(stack)到一起作为网络的输入。
交叉网络(Cross Network)

交叉网络的核心思想是以一种高效的方式进行显性的特征组合,每一层的神经元数量都相同而且等于输入向量\(X_0\)的维度,每一层都符合下面公式(都是列向量),其中函数\(f\)拟合的是\(X_{l+1}-X_l\)的残差。
\(l\)层的交叉网络组成了\((x_1,\dots,x_d)\)从1价到\(l+1\)价所有的特征组合。另\(L_c\)表示交叉网络的层数,\(d\)表示输入向量的维度,则交叉网络需要的参数为\(d \times L_c \times 2\),乘以2是因为每一层有两个长度为\(d\)的参数\(W\)和\(B\),从而交叉网络的时空复杂度为\(O(d)\),所以交叉网络相对于DNN引入的复杂度是微乎其微的。得益于\(X_0X_l^T\)的一阶性质,使得我们无需计算和存储整个矩阵就能够高效的生成所有交叉项。
深度网络(Deep Network)
交叉网络小规模的参数限制了模型的表达能力,为了获得高度非线性的组合特征,我们引入了DNN,该网络是一个全联接前馈神经网络,每一层都符合下面公式,其中\(H_l\)表示隐藏层,\(f(\cdot)\)是ReLU激活函数。
为了简单起见假设每个隐藏层的神经元数目相同,另\(L_d\)表示层数\(m\)表示每层的神经元个数,则第一层需要的参数量为\(d\times m + m\),剩余层需要的参数量为\((m^2 +m)\times (L_d -1)\)。
组合层(Combination Layer)
组合层将交叉网络和DNN的输出组合到一块,然后将组合向量输入标准的logits层,用下面的公式解决二分类问题,其中$\sigma (x)=1/(1+exp(-x)) $。
损失函数如下式,其中\(p_i\)是通过上式计算出来的正例的概率,然后通过联合训练(jointly)交叉网络和DNN,使得两个网络在训练阶段知道彼此的存在。
理论分析
多项式近似
根据Weierstrass逼近定理,在特定平滑假设下任意函数都可以被一个多项式以任意的精度逼近,所以可以从多项式近似的角度分析交叉网络。\(d\)元\(n\)阶多项式参数量为\(O(d^n)\),交叉网络只需要\(O(d)\)参数量就可以生成相同阶数多项式中出现的所有交叉项。
FM的泛化
交叉网络借鉴了FM共享参数的思想并将它扩展至更深的结构。FM模型中每个特征\(x_i\)都有一个相关的权重向量\(v_i\),交叉项\(x_ix_j\)的权重通过\(<v_i,v_j>\)计算得到。DCN中每个特征\(x_i\)都对应一个标量集\(\lbrace w_k^{(i)} \rbrace _{k=0}^l\),也就是每个交叉层权重向量\(W\)的第\(i\)分量组成的集合,这样交叉项\(x_ix_j\)的权重通过\(\lbrace w_k^{(i)} \rbrace _{k=0}^l\)和\(\lbrace w_k^{(j)} \rbrace _{k=0}^l\)计算得到。两个模型中每个特征对应的参数都是独立学习的,交叉项的参数通过对应的特征参数计算得到。参数共享不仅使得模型更高效而且对没见过的组合特征具有更好的泛化能力,同时对噪声更健壮。比如\(x_i\)和\(x_j\)在训练数据中没有同时出现过,\(x_ix_j\)对应的权重就无法学习到。FM是一个浅层结构,只能表示2价的特征组合。DCN能够学习高阶的特征组合,在特定阶数限制下能够构建所有的交叉项。而且同对FM的高阶扩展相比,DCN的参数量是输入向量维度的线性函数。
高效映射
每个交叉层都会创建\(X_0\)和\(X_l\)各元素之间的两两组合,生成\(d^2\)维度的向量,然后将该向量映射到\(d\)维的空间中。如果直接进行映射操作需要\(O(d^3)\),而DCN提供了一种高效的映射方式只需要\(O(d)\)即可。考虑\(X_p=X \tilde X^T W\),假设\(X\)和\(W\)都是2维列向量,如下所示上面公式是直接计算,下面公式是高效的计算法法。
其中\(W\)是一个列向量,可以拆开
总结及思考
- 交叉网络最终输出是什么?需要推导看一下和多项式的区别以及每个特征的参数?
- \(X_0X_l^T\)的一阶性质是秩为1吗?为什么会导致无需计算和存储整个矩阵?
- 多项式近似的理论证明?为什么需要的参数量少?
- 参数共享思想?FM和DCN到底怎么实现的参数共享?
- 高效映射高效体现在哪里?复杂度是\(O(d)\)吗?

