
(坚持每天写算法)算法复习和学习part1基础算法part1-14——离散化
直接上题目:

离散化描写的是题目,离散化题目都是像这种,被操作的数据是”某个数据在无限长的x里面“,它的数据范围都是比较广阔的,所以被称为离散化。对于这种题目,我们要将数据以某种方式用连续的形式排到一个容器里面。(这就是映射)(ps:这里讲的是容器是为了提醒我自己)
这道题或许有人说使用哈希表,但是求区间和哈希表的遍历是真的两端点之间全遍历一次吧,那还是没有解决问题,嗯,离散化的缺点就是存储的下标太大了,不说空间,某些操作的时间复杂度可能要爆掉。
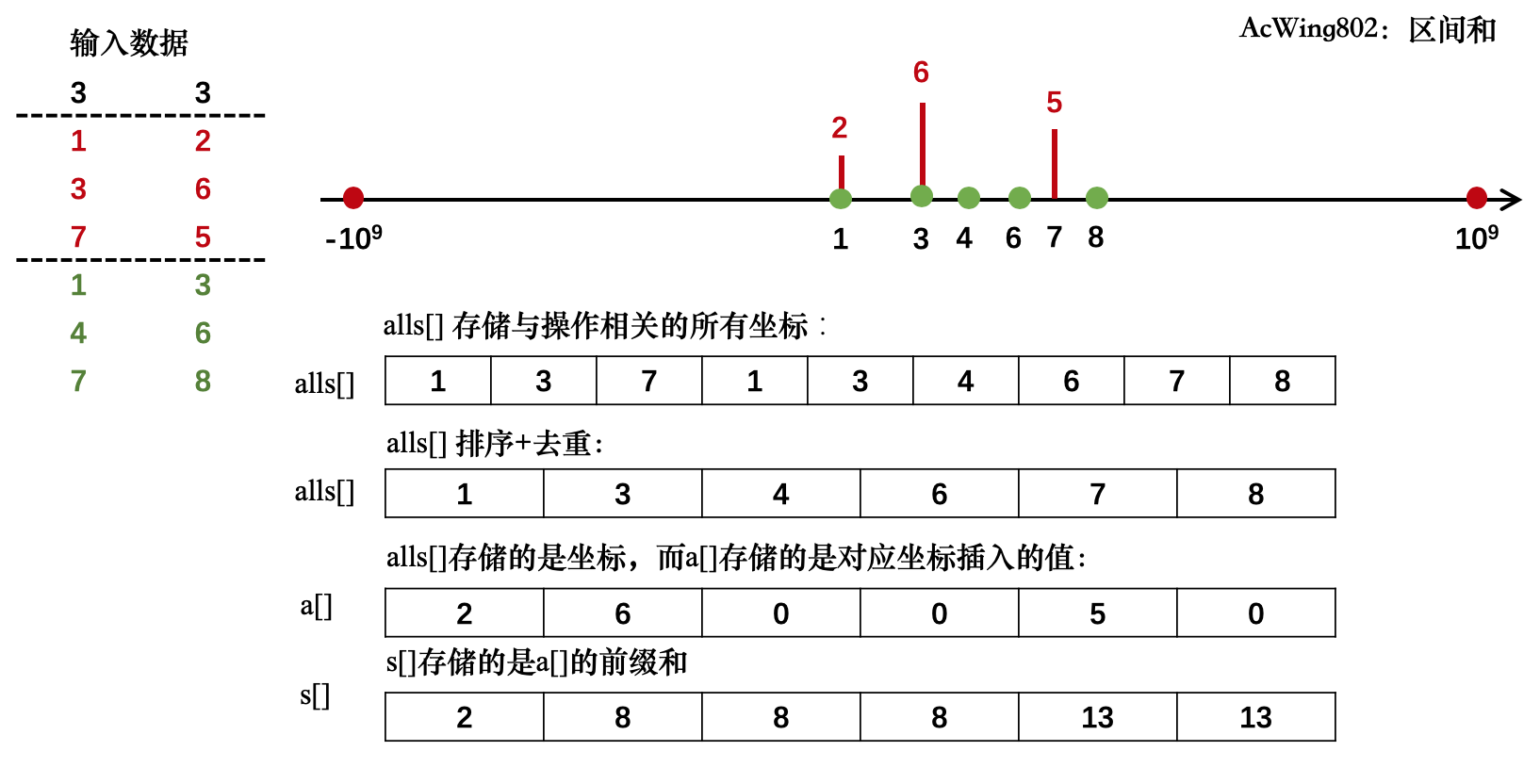
这一道题的思路是,其实我重新做这一道题的时候不是说没有头绪,只能说在思考我之前是怎么做的哈哈哈,我们看题目,有说到区间和,那么考虑使用前缀和,因为醋包了一盘饺子,使用前缀和的话我们需要有序数组,也就是说要排序,对哪些进行排序?对坐标,让坐标和下标的意义一样,而且题目给出的坐标有的时候是重复的,那么排序前要去重。
存放数据的我们设置成容器vector,容器就是放东西的(主要是输入数据中输入了坐标和想要加的数值,互有联系,使用pair封装成一个数据类型(?),放到容器里面)(ps:不用数组是因为数轴坐标可能是负的,难道可以用数组下标去存坐标?),至于这些容器装什么,我会借用大佬的图。
由于这些坐标并不是连续的数字,所以需要一个find函数来定位(查找,二分查找)她们在容器里的定位。
除了装数据的容器,为了简便(当然不建议在装数据的容器里面放结果,会混的),我们需要一个装结果的数组。
这个是大佬的图解:

这里是代码:

#include <iostream> #include <cstdio> #include <cstring> #include <algorithm> using namespace std; const int N = 300010;//重写的时候并没有想清楚这个为什么要取n + 2m来着,然后模拟了一下过程发现,all容器除了存放x还要存放l+r,而all容器就是聚集化的核心代码 //前缀和数组要考虑到all容器 typedef pair<int , int> PII; int a[N] , s[N]; vector<int> all;//c++放东西的就只用vector就行了,<int , int >只是一种数据类型,之所以add和query都放进去,感觉这个不用解释欸, vector<PII> query; vector<PII> add; int find(int x){//查找在哪里,直接使用二分法锁数值,因为要拿到的是x在all的下标,所以r跨步会大点,也就是左边界二分法 int l = 0 , r = all.size() - 1; while(l < r){ int mid = (l + r) >> 1; if(all[mid] >= x) r = mid ; else l = mid + 1; } return l + 1;//前缀和的数组都是要注意边界问题(衍生的差分也是同样的问题) } int main(){ int n , m; cin >>n >>m; //分别记录存放的和查询的 , 并将它们分别放进all和add里面 for(int i = 0 ; i < n ; i ++){ //重写了一下,果然我忘记怎么将数据存进pair了 int x ,c ; cin >> x >> c; add.push_back({x , c}); all.push_back(x); } for(int i = 0 ; i < m ; i ++){ int l , r; cin >> l >> r; query.push_back({l , r}); all.push_back(l); all.push_back(r); } //一个重要的点,因为查询给的区间是可能重复的,但是我们为了聚集化也一起放进去了,所以要去重,总结:聚集化注意去重 sort(all.begin() , all.end());//sort只是为了上下限 all.erase(unique(all.begin() , all.end()) , all.end()); //这个时候应该是相加了,那么应该先赋值给a数组,因为x和数组的连续的123等是不搭配的,比如x为5不代表在a数组里面下标是5 for(auto item : add){ int i = find(item.first);//item.first也就是x,find返回的是x在all的下标是多少 a[i] += item.second; } for(int i = 1 ; i <= all.size() ; i ++) s[i] = s[i -1] + a[i]; //是all.size而不用add.size的原因是,在all里面是这么排的,a是add的,b是all的,c是add的,a b c是完全有可能的,然后add又要全部加上,所以是all.size for(auto item : query){ int l = find(item.first) , r = find(item.second);//同样的是找对应的区间,如果有些区间超过了add的范围,由于s初始化为0,所以也没问题 cout <<s[r] - s[l - 1] << endl; } return 0; } //微微总结一下,c++放东西的就只用vector就行了,<int , int >只是一种数据类型;二分本质是查找,可以锁数值;vector的begin和end方法,以及back方法,pair的first和second等类似的属性;聚集化要注意排序查重
参考链接:AcWing 802. 画个图辅助理解~ - AcWing
AcWing 802. 区间和(离散化,代码解释非常详细) - AcWing
本文作者:程序计算机人
本文链接:https://www.cnblogs.com/clina/p/18004853
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探