
egrep 及扩展正则表达式
grep -E 表示支持扩展的正则表达式
grep -E = egrep
一、字符匹配:
扩展模式下的字符匹配与基本正则表达式的字符匹配相同,如:
. 表示任意单个字符
[] 表示范围内人任意单个字符,如[0-9],表示任意单个数字
[^] 表示范围外的任意单个字符,如[^0-9],表示出数字外的任意单个字符
二、次数匹配:
上述字符匹配中,基本正则表达式与扩张表达式完全相同,但次数匹配就有些不一样了。
* 匹配前面字符任意次,与基本正则表达式意义相同
? 匹配其前字符0次或1次,其前面不需要 \ 转义
+ 匹配其前字符至少一次,等于基本正则表达式的 \{1, \} ?+ = *
{m,n} 匹配其前字符至少m次,最多n次,等于基本正则表达式的\{m,n\}
三、位置锚定
与基本正则表达式完全意义,请参考上一篇。
与基本正则表达式完全意义,请参考上一篇。
四、分组
基本正则表达式中支持分组,而在扩展正则表达式中,分组的功能更加强大,也可以说才是真正的分组,用法如下:
():分组,后面可以使用\1 \2 \3...引用前面的分组
除了方便后面引用外,分组还非常方便的可以使用上述次数匹配方法进行匹配具有相同条件的数据。

如:grep '^(int).*\1' *.txt 搜索文件*.txt中以int开头,而后面还存在int的行

所以,要加上grep -E参数

如:grep '^(barlow).*\1' /etc/passwd 搜索/etc/passwd中以barlow开头,而后面还存在barlow的行

五、或者
| 表示或,如 : a|b 表示匹配a或者b
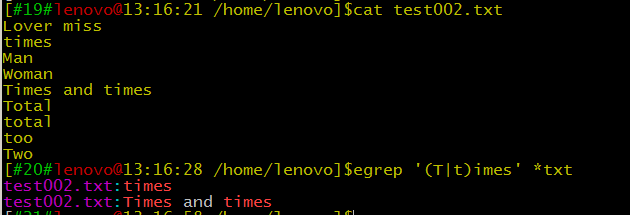
E|times 匹配E或times,即 | 匹配的是其整个左边或者右边

同样效果:

$egrep '(T|t)imes' *txt
六、应用实例
大家可以自己手动测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号