爬虫,部署介绍,文档树,bs4搜索文档树,css选择器,selenium基本使用,无界面浏览器,selenium其他用法
内容回顾
requests高级用法
解析json:发送http请求,返回的数据,可能是xml格式,json格式,如果是json则可以直接调用json方法进行转换
requests.get().json
ssl认证
http和https的区别
https实际上是http +ssl/tsl
http版本之间的区别
0.9 基于tcp/ip的应用层协议,每发一次请求建立一个tcp链接,经过三次握手,请求结束需要四次挥手
1.1 新增加了keep-alive,当第一次链接发送完毕后,不会立即断开连接,后续短时间内的请求会走上次建立的连接
2.x 新增了多路复用,这个多路复用与网络模型的多路不太一样,他这个意思是,多个请求使用同一个数据包
代理
发送请求如果使用自己的ip,可能会被封(加黑名单)需要使用代理ip
如果使用了代理ip就不能访问本地django项目了,因为本地如果没有公网ip那么就无法进行访问了
res = requests.post('https://www.cnblogs.com',proxies={'http':'27.79.236.66:4001'})
高匿,透明
http请求头:
x-forword-for,user-agent,cookie,referer,contenType
http:
请求协议:
请求首行:请求方式,请求头地址,http的版本
请求头:key-value
换行
请求体
响应协议:响应头,响应字符串描述
响应头:key-value
响应体
代理池搭建:
开源的:原理
爬取免费代理》验证》存到redis中
起了个flask服务,监听5001断开访问地址随机返回一个代理
自己的django测试使用代理
超时
异常
上传文件
内网穿透
花生壳
樱花frp
爬取视频网站
请求头中的数据
请求回来的数据,不一定能直接用
爬取新闻
bs4:fand_all,find
内容详情
bs4介绍,遍历文档树
beautifulsoup4 从HTML或XML文件中提取数据的python库
用它来解析爬取回来的xml
安装
pip install beautifulsoup4
解析库
pip install lxml
使用
soup=BeautifulSoup('要解析的内容str类型','html.parser/lxml')
bs4的遍历文档树
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
lqz
<b>The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1" name='lqz'>Elsie</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# 美化,不是标准xml,完成美化
print(soup.prettify())
# 2 遍历文档树---》通过 . 来遍历
# print(soup.html.body.p) # 一层一层找
# print(soup.p) # 跨层 只找第一个
#2、获取标签的名称
# print(soup.a.name)
#3、获取标签的属性 ---》属性字典
# print(soup.a.attrs['href'])
# print(soup.a.attrs.get('class')) # class 会有多个 ['sister']
# print(soup.a.attrs.get('name'))
#4、获取标签的内容
# text 获得该标签内部子子孙孙所有标签的文本内容
# print(soup.p.text)
# # string p下的文本只有一个时,取到,否则为None
# print(soup.p.string)
# # strings
# print(list(soup.p.strings)) # generator
# #5、嵌套选择
# print(soup.html.body)
# ---- 了解
#6、子节点、子孙节点
# print(soup.body.contents) #p下所有子节点,只取一层
# print(list(soup.p.children)) #list_iterator得到一个迭代器,包含p下所有子节点 只取一层
# print(list(soup.body.descendants) ) # generator 子子孙孙
#7、父节点、祖先节点
# print(soup.a.parent) #获取a标签的父节点 直接父亲
# print(list(soup.a.parents) )#找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
# print(soup.a.next_sibling) #下一个兄弟
# print(soup.a.previous_sibling) #上一个兄弟
#
# print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
print(list(soup.a.previous_siblings)) #上面的兄弟们=>生成器对象
bs4搜索文档树
find find_all
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
五种过滤器:字符串,正则表达式,列表,True,方法
字符串,查询条件是字符串
# res=soup.find_all(name='p')
# res=soup.find_all('p')
# print(res)
# 类名叫sister的所有标签
# res=soup.find_all(class_='sister')
# print(res)
# id 叫link1的标签
# res=soup.find_all(id='link1')
# print(res)
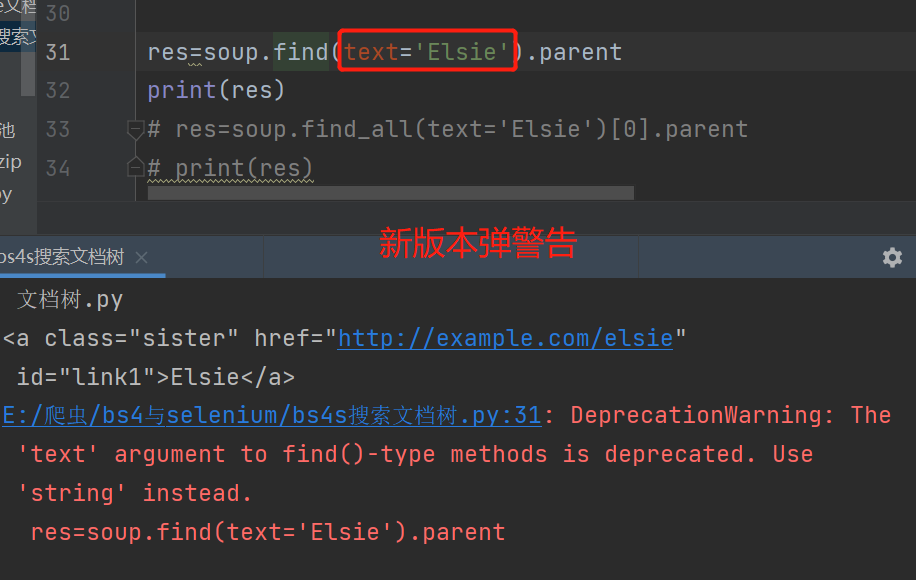
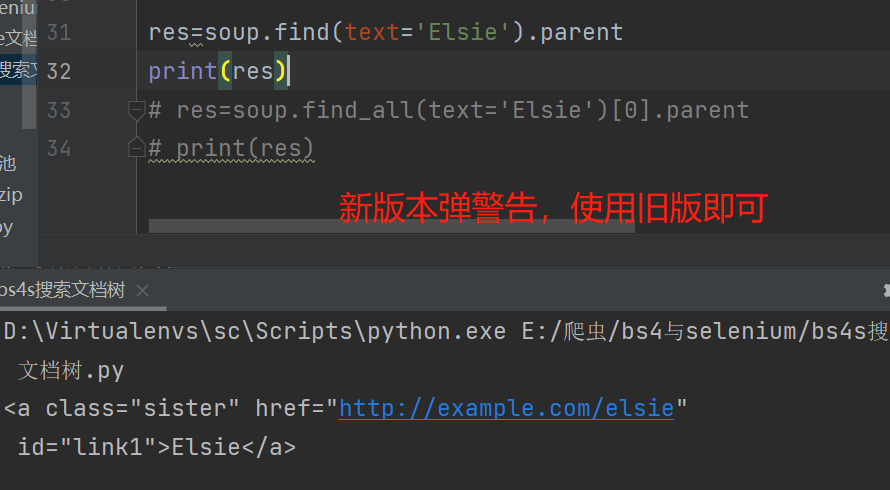
# 文本内容叫Elsie的父标签
# res=soup.find(text='Elsie').parent
# print(res)
# 另一种方式
# # res=soup.find_all(attrs={'class':'sister'})
# res=soup.find_all(attrs={'id':'link1'})
# print(res)
text=‘值’
正则表达式
import re
res = soup.find_all(id=re.compile('^l'))
print(res)
res = soup.find_all(class_=re.compile('o'))
print(res)
res = soup.find_all(text=re.compile('ls'))
print(res)
res = soup.find_all(attrs={'id': re.compile('^l')})
print(res)
列表
res=soup.find_all(id=['link1','link2'])
print(res)
print(soup.find_all(name=['a','b']))
print(soup.find_all(['a','b']))
True
# res=soup.find_all(id=True) # 所有有id的标签
# res=soup.find_all(href=True)
# res=soup.find_all(class_=True)
# print(res)
res = soup.find_all(text=True)
print(res)
for i in res:
print(i.parent.name)
方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(name=has_class_but_no_id))
find的其他参数
name
class_
text
attrs
id
limit:限制条数,find_all用的 find本质是find_all limit=1
recursive:查找的时候 默认True找子子顺孙孙
# limit 参数
# res=soup.find_all(href=True,limit=2)
# print(res)
# recursive 查找的时候,是只找第一层还是子子孙孙都找
# res=soup.find_all(name='b',recursive=False)
# res=soup.find_all(name='b')
# 建议遍历和搜索一起用
res=soup.html.body.p.find_all(name='b',recursive=False)
print(res)
css选择器
学过的css选择器,可以很复杂
.类名
#id
标签名
我们使用bs4或其他解析器(lxml)他们都会支持css选择器,也会支持xpath
# html_doc = """
# <html><head><title>The Dormouse's story</title></head>
# <body>
# <p class="title">
# <b>The Dormouse's story</b>
# Once upon a time there were three little sisters; and their names were
# <a href="http://example.com/elsie" class="sister" id="link1">
# <span>Elsie</span>
# </a>
# <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
# <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
# <div class='panel-1'>
# <ul class='list' id='list-1'>
# <li class='element'>Foo</li>
# <li class='element'>Bar</li>
# <li class='element'>Jay</li>
# </ul>
# <ul class='list list-small' id='list-2'>
# <li class='element'><h1 class='yyyy'>Foo</h1></li>
# <li class='element xxx'>Bar</li>
# <li class='element'>Jay</li>
# </ul>
# </div>
# and they lived at the bottom of a well.
# </p>
# <p class="story">...</p>
# """
from bs4 import BeautifulSoup
# soup=BeautifulSoup(html_doc,'lxml')
# select内写css选择器
# print(soup.select('.sister'))
# print(soup.select('#link1'))
# print(soup.select('#link1 span'))
终极大招如果不会写css选择器,可以复制
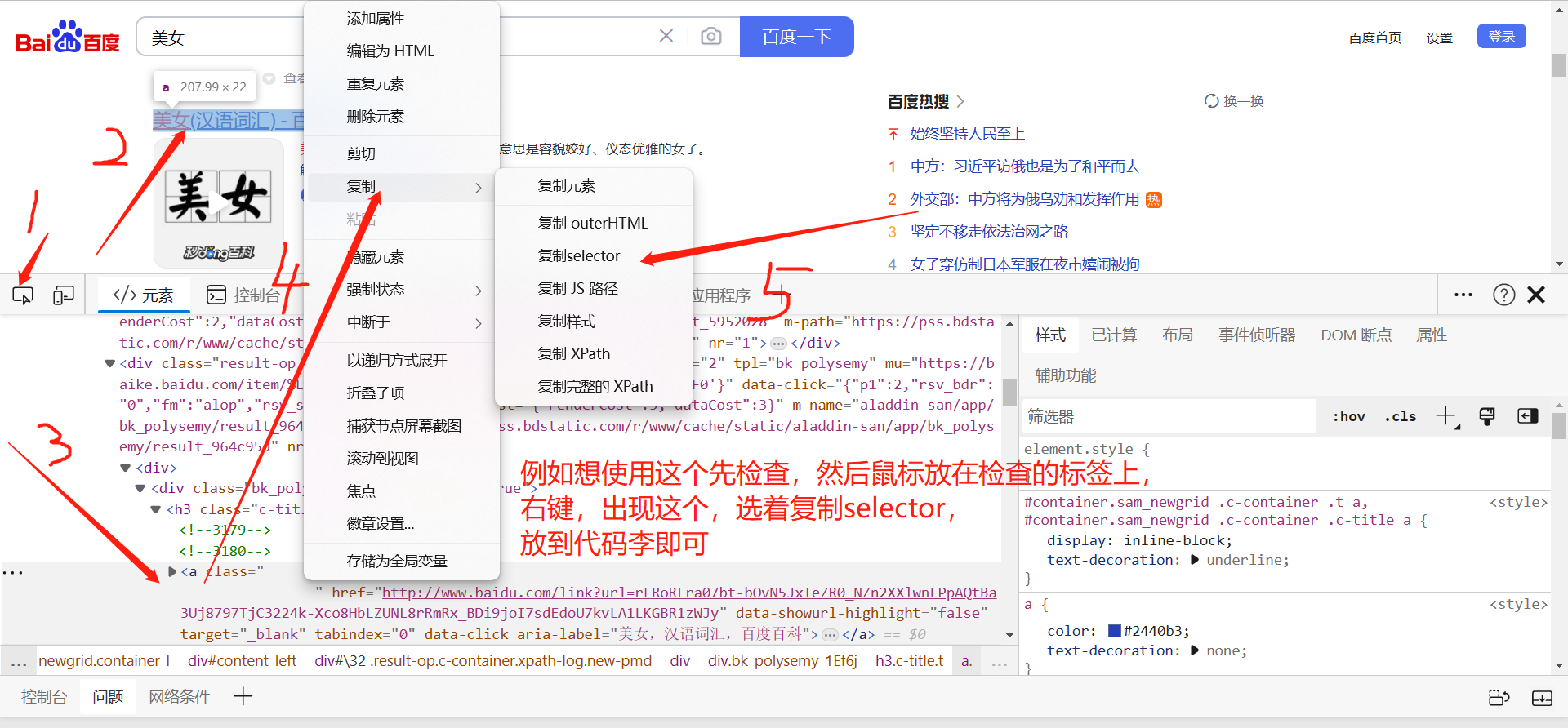
import requests
res=requests.get('https://www.w3school.com.cn/css/css_selector_attribute.asp')
soup=BeautifulSoup(res.text,'lxml')
# print(soup.select('#intro > p:nth-child(1) > strong'))
print(soup.select('#intro > p:nth-child(1) > strong')[0].text)
selenium基本使用
https://www.cnblogs.com/liuqingzheng/p/16005872.html
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行javascript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转,输入,点击,下拉等,来拿到网页渲染之后的结果,可以支持多种浏览器
使用步骤
下载selenium
pip install selenium
操作浏览器:分不同浏览器,需要下载不同浏览器的驱动
我选着谷歌,因为比较好用》谷歌浏览器驱动:
https://registry.npmmirror.com/binary.html?path=chromedriver/
跟自己电脑中的谷歌浏览器大版本要对应,最后小版本如果没有选择最接近的版本即可
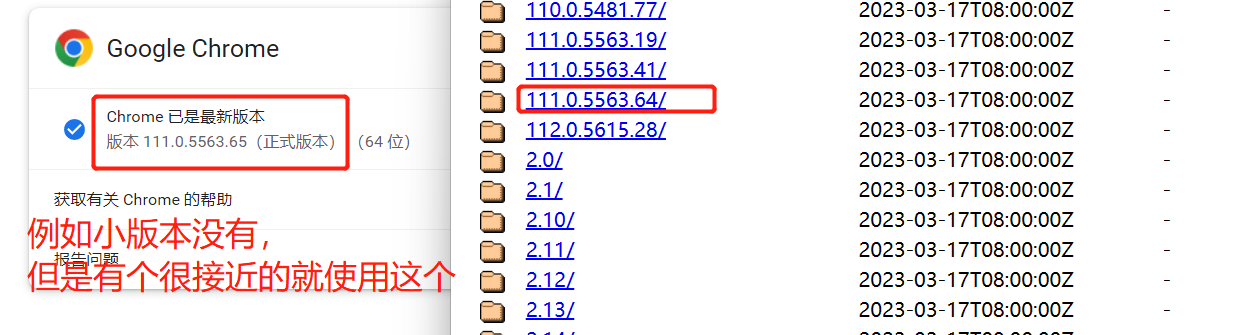
下载完的驱动,放在项目路径下
写代码,控制谷歌浏览器
from selenium import webdriver
import time
bro = webdriver.Chrome(executable_path='chromedriver.exe') # 打开一个谷歌浏览器
bro.get('https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3') # 在地址栏中输入地址
print(bro.page_source) # 当前页面的内容 (html格式)
with open('1.html','w',encoding='utf-8') as f:
f.write(bro.page_source)
time.sleep(5)
bro.close() # 关闭浏览器
无界面浏览器(linux可能会用到)
from selenium import webdriver
import time
from selenium.webdriver.chrome.options import Options
# 隐藏浏览器的图形化界面,但是数据还拿到
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #手动指定使用的浏览器位置
bro = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options) # 打开一个谷歌浏览器
# 隐藏浏览器的图形化界面,但是数据还拿到
bro.get('https://www.cnblogs.com/') # 在地址栏中输入地址
print(bro.page_source) # 当前页面的内容 (html格式)
time.sleep(5)
bro.close() # 关闭浏览器
模拟登录百度
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
bro = webdriver.Chrome(executable_path='chromedriver.exe') # 打开一个谷歌浏览器
bro.get('https://www.baidu.com')
# 加入等待:找标签,如果找不到,就等待 x秒,如果还找不到就报错
bro.implicitly_wait(10) # 1 等待
# 从页面中找到登录 a标签,点击它
# By.LINK_TEXT 按a标签文本内容找
btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# 点击它
btn.click()
# 找到按账号登录的点击按钮,有id,优先用id,因为唯一 TANGRAM__PSP_11__changePwdCodeItem
btn_2 = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__changeSmsCodeItem')
btn_2.click()
time.sleep(1)
btn_2 = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__changePwdCodeItem')
btn_2.click()
time.sleep(1)
name = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__userName')
password = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__password')
name.send_keys('306334678@qq.com')
password.send_keys('1234')
time.sleep(1)
submit=bro.find_element(by=By.ID,value='TANGRAM__PSP_11__submit')
submit.click()
time.sleep(2)
bro.close() # 关闭浏览器
selenium其他用法
查找标签
两个方法
bro.find_element 找一个
bro.find_elements 找所有
可以按id,标签,name属性名,类名,a标签的文字,a标签的文字模糊匹配,css选择器,xpath
input_1=bro.find_element(by=By.ID,value='wd') # 按id找
input_1 = bro.find_element(by=By.NAME, value='wd') # name属性名
input_1=bro.find_element(by=By.TAG_NAME,value='input') # 可以按标签名字找
input_1=bro.find_element(by=By.CLASS_NAME,value='s_ipt') # 可以按类名
input_1=bro.find_element(by=By.LINK_TEXT,value='登录') # 可以按a标签内容找
input_1=bro.find_element(by=By.PARTIAL_LINK_TEXT,value='录') # 可以按a标签内容找
input_1 = bro.find_element(by=By.CSS_SELECTOR, value='#su') # 可以按css选择器
获取位置属性大小,文本
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.amazon.cn/')
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'cc-lm-tcgShowImgContainer')))
tag=browser.find_element(By.CSS_SELECTOR,'#cc-lm-tcgShowImgContainer img')
#获取标签属性,
print(tag.get_attribute('src'))# 用的最多
tag.text # 文本内容
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
browser.close()
等待元素被加载
代码执行很快,有的标签还没来的及加载,直接查早就会报错,设置等待
隐士等待:所以标签,只要去找,找不到遵循等待10s的规则
bro.implicitly_wait(10)
显示等待:需要给每一个标签绑定一个等待,麻烦
元素操作
# 点击
tag.click()
# 输入内容
tag.send_keys()
# 清空内容
tag.clear()
# 浏览器对象 最大化
bro.maximize_window()
#浏览器对象 截全屏
bro.save_screenshot('main.png')
执行js代码
bro.execute_script('alert("美女")') # 引号内部的相当于 用script标签包裹了
# 可以干的事
-获取当前访问的地址 window.location
-打开新的标签
-滑动屏幕--》bro.execute_script('scrollTo(0,document.documentElement.scrollHeight)')
bro.execute_script('scrollTo(0,document.body.clientHeight)')
-获取cookie,获取定义的全局变量
切换选项卡
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) #获取所有的选项卡
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(2)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
浏览器前进加后退
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/')
browser.back()
time.sleep(2)
browser.forward()
browser.close()
异常处理
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
try:
except Exception as e:
print(e)
finally:
browser.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号