爬虫介绍request介绍,request使用
内容详情
爬虫介绍
爬虫是什么
爬虫就是程序》从互联网中,各个网站上,爬取数据【我们能够浏览的页面才能爬】,做数据清洗,入库
爬虫的本质
模拟http请求获取数据》入库
网站
app:抓包
百度其实就是一个大爬虫
百度有个叫百度蜘蛛的东西,他在一刻不停的在互联网中爬取各个页面》爬取完后》保存到百度的数据库中
我们在百度搜索框中搜索》百度自己的数据库查询关键字》返回回来
点击某个页面》跳转到真正的地址上
seo:优化搜索关键字,尽可能的让百度蜘蛛爬取你的页面,让你的关键字搜的排到前面
sem:充钱会把你的网站放在搜索关键字前面
我们学的
模拟发送http请求
requests模块
selenium
反扒:封ip:ip代理,封帐号:cookie池
解析数据:bs4
入库:mysql,redis,文件中
爬虫框架:scrapy
requests模块介绍
使用python如何发送http请求
模块requests模块,封装了python内置模块urllib
使用requests可以模拟浏览器的请求(http),比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
安装
pip install requests
requests发送get请求
import requests
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
print(res.text)
如果有的网站,发送请求,不返回数据,人家做了反扒》拿不到数据,学习如何反扒
res = requests.get('https://dig.chouti.com/')
print(res.text)
requests携带参数
方式1直接拼接到路径中
import requests
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html?name=lqz&age=19')
方式2使用params参数
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',params={'name':"lqz",'age':19})
print(res.text)
print(res.url)
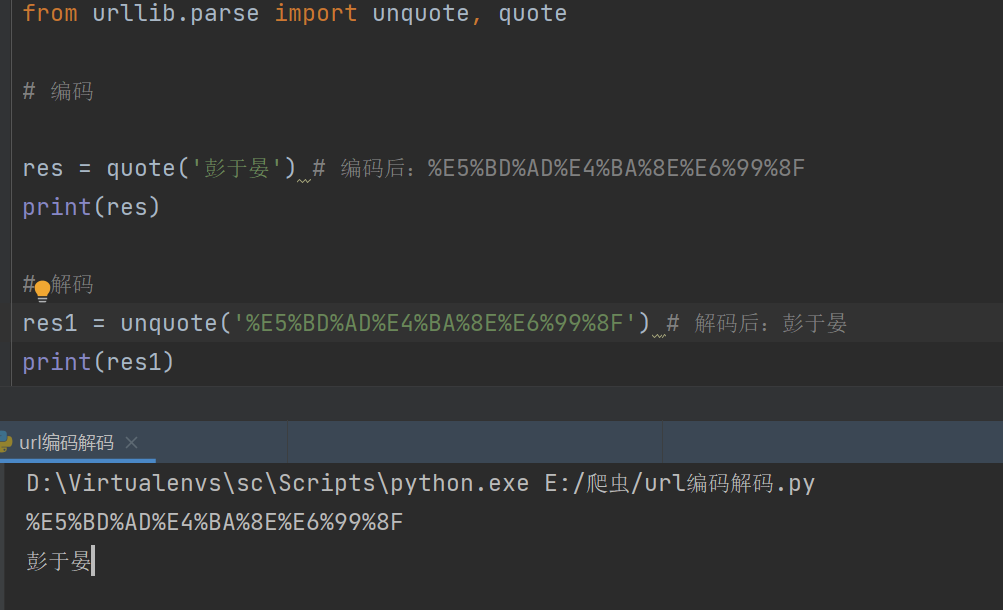
url编码解码
from urllib.parse import unquote, quote
# 编码
res = quote('彭于晏') # 如果是正文,在地址中会做url编码后:%E5%BD%AD%E4%BA%8E%E6%99%8F
print(res)
# 解码
res1 = unquote('%E5%BD%AD%E4%BA%8E%E6%99%8F') # 解码后:彭于晏
print(res1)
携带请求头
反扒措施之一就是请求头
http请求中,请求头中有一个很重要的参数User-Agent表名客户端类型是什么,Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
如果没有带这个请求头,后端就禁止
reuqests发送请求没有携带该参数,所以有的网站就禁止了
http协议版本间的区别
Connection: keep-alive 保存连接,当第一次请求的时候创建好连接后,段时间段内的下一次请求就不会在创建连接了,而是走上传创建好的连接
http协议有版本:
主流1.1(主要加了keep-alive)
0.9(初版协议)
2.x(增加了多路复用)
最新的3.x(可以用一个连接发送多条数据请求)
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/',headers=headers)
print(res.text)
发送post请求,携带数据
import requests
# 携带登录信息,携带cookie
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Cookie': ''
}
# post请求,携带参数
data = {
'linkId': '38063872'
}
res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data)
print(res.text)
jwt认证如果token设置的过期时间很长,被别人拿到了会有风险
解决方案:使用双token认证
自定登录,携带cookie的两种方式
登录功能一般都是post
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
# 响应中会有登录成功的的cookie,
print(res.cookies) # RequestsCookieJar 跟字典一样
# 拿着这个cookie,发请求,就是登录状态
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式 方式一是字符串,方式二是字典或CookieJar对象
# 方式二:放到cookie参数中
res1=requests.get('http://www.aa7a.cn/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
requests.session的使用
为了保持cookie,以后不需要携带cookie
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/')
# 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
post请求携带数据编码格式
data 对应字典,这个写,编码方式是urlencoded
import requests
#data 对应字典,这个写,编码方式是urlencoded
requests.post(url='xxxx',data={'xx':'yy'})
json对应字典,这样写,编码方式是json格式
# json对应字典,这样写,编码方式是json格式
requests.post(url='xxx',json={'xx':'yy'})
终极方案,编码就是json格式
requests.post(url='xxx',json={'xx':'yy'},headers={
'content-type':'application/json'
})
响应Response对象
Response响应对象的属性和方法
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
respone=requests.get('http://www.jianshu.com',headers=headers)
print(response.txt) # 响应体转成了字符串默认以utf-8转
print(response.content) # 响应体的原始二进制内容
print(response.status_code) # http响应状态码
print(response.headers) # 响应头
print(response.cookies) # cookies是在响应头,但是比较重要所以就单独在拿出来做成了属性,拿出来的是RequestsCookieJar跟字典一样
print(response.cookies.get_dict()) # cookieJar对象》转成字典
print(response.cookies.items()) # cookie的键值对
print(response.url) # 请求地址
print(response.history) # 如果网站有重定向,会记录重定向之前的网址
print(response.encoding) # 响应编码格式
编码问题
有的网站,打印
res.text>反向乱码》请求回来的二进制》转成了字符串》默认用utf8转》
我们手动指定编码解决乱码问题
response.encoding='gbk'
在打印res.text他就用gbk转码了
下载图片,视频
下载图片如果很小可以直接一下保存下来
import requests
res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
print(res.content)
with open('美女.jpg','wb') as f:
f.write(res.content)
下载视频,可能会很大所以我们就要做一些处理了
res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
print(res.content)
with open('视频.mp4', 'wb') as f:
for data in res.iter_content(1024):
f.write(data)
练习
爬图片
import requests
import re
import os
from concurrent.futures.thread import ThreadPoolExecutor
url = 'https://www.ivsky.com/bizhi/jingse_t6874/index_%s.html'
patch = '<div class="il_img"><a href=".*?" title=".*?" target="_blank"><img src="(?P<url>.*?)" width=".*?" height=".*?" alt="(?P<name>.*?)"></a></div>'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'referer': 'https://www.ivsky.com/bizhi/',
'cookie': 't=68dba8f2dc20b29468c11f913717fd76; r=8316; Hm_lvt_a0c29956538209f8d51a5eede55c74f9=1678867748; Hm_lpvt_c13cf8e9faf62071ac13fd4eafaf1acf=1678867763; Hm_lpvt_a0c29956538209f8d51a5eede55c74f9=1678867763',
}
pool = ThreadPoolExecutor(10)
class Image:
def __init__(self, urls, count_num, base_path, re_str, headers):
self.urls = urls
self.count_num = count_num # 下载多少页面壁纸
self.base_path = base_path # 下载位置
self.re_str = re_str # 匹配字符串
self.headers = headers # 请求头
def save_img(self, base_path, i_url, img_name):
data = self.get_url(i_url)
with open(os.path.join(base_path, img_name), 'wb') as f:
f.write(data.content)
f.flush()
print('保存文件%s成功' % img_name)
def get_url(self, url):
res = requests.get(url, headers=self.headers)
return res
def get_img_url(self, res):
data = re.findall(patch, res.text)
img_list = []
for item in data:
i = item[0].replace('img', 'img-pre', 1)
i = re.sub('bizhi/.*?/', 'bizhi/pre/', i)
img_list.append(['https:' + i, item[1]])
return img_list
def get(self, url, first_num):
res = self.get_url(url)
img_list = self.get_img_url(res)
for index, i_url in enumerate(img_list, 1):
name = f'{i_url[1]}-{first_num}-{index}.jpg'
base_path = os.path.join(self.base_path, f'第{first_num}页')
if not os.path.exists(base_path):
os.makedirs(base_path, 777)
print(index)
pool.submit(self.save_img, base_path, i_url[0], name)
def start(self):
for num in range(1, self.count_num):
url = self.urls % (num)
self.get(url, num)
base_path = os.path.join(os.path.dirname(__file__), 'img')
if not os.path.exists(base_path):
os.makedirs(base_path, 777)
img_obj = Image(url, 50, base_path, patch, headers)
img_obj.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号