python变量以及数据类型
目录
Python基础
ctrl+s程序员的灵魂

习惯用ctrl+s因为你不知道你的电脑突然会发生什么,导致代码丢失,数据无价
注释语法
什么是注释?
更方便的让别人理解这段代码的含义
注释的四种方法
1.解释说明文字前加井号
# 注释文本 单行注释
print(123) # 单行注释
2.回车键左边哪个键英文输入法下连续按三下
'''多行注释文本
'''
3.shift+回车键左边哪个键英文输入发下按三下
"""
多行注释文本
"""
ps:小技巧快捷键注释
先选中要注释的行然后 ctrl + ?
PEP8规则
'''
pycharm中有很多时候会有各种颜色提示还有波浪线
只要不是红线一般不影响代码运行
'''
1.代码行单行注释时 离代码两个空格# 一个空格后写注释文本
例如:
print(123) # 单行注释
列表的规范
中括号括起来 数据值 逗号 空格 数据值
赋值号左右两边都要空一格
字典的规范
大括号括起来 键名 冒号 空格 数据找 为一对用逗号与另外一对键值对隔开
命名规范
变量名的命名规范
字母,下划线,数字
变量名要见名知意
可以中文命名 但不建议
如 名字 = '张三'
可以拼音命名 但不建议
如 xingming = '张三'
不可以使用数字开头
不可以使用python关键字
正确示范:
name = '张三'
name1 = '李四'
name_age = 18
_name = '张三'
错误示范:
1name = '张三'
print = 123
·······
多单词3种命名方式
1.单词下划线单词 python推荐
name_age_value = 18
2.大驼峰(首字母大写) js推荐
NameAgeValue = 18
3.小驼峰(第一个首字母小写,其他首字母大写)
nameAgeValue = 18
可以借助pycharm的自动格式化反向学习
快捷键为 ctrl + alt + l
变量与常量
变量与常量让计算机具备人记录事物的能力
变量
记录变化(可能经常改变)的十五状态,就如人的,年龄,长相,身高,体重
日常生活中变量的案例
看到张三
姓名张三
性别男
年龄38
代码中记录事物状态
name = '张三'
gender ='male'
age = 38
语法形式:
变量名 赋值 数据值
一旦看到赋值符号 那么首先看右边
底层原理:
首先数据值申请一块内存地址
然后就会把这个数据值绑定给一个变量
以后就可以通过变量名访问到数据
注意事项:
同一个数据值可以绑定多个变量名
同一时刻变量名只能绑定一个数据值
name = '张三'
name = '李四'
到这里,实际name为李四
常量
记录固定(可能不经常改变)的事物状态
如物种,比热容,圆周率等等
在python中没有实际的常量,靠程序员自遵守。
规则:
变量名大写 赋值 数据值
实际形式:
HOST = '127.0.0.1'
ps:除了全大写外,其他与变量一致
数据类型
- 什么是数据类型
- 在日常生活中数据的表现形式多种多样在程序中也是如此
- 为何学习数据类型
- 针对不同的数据采用最佳的数据类型来表示出该数据的价值
- 目前学习数据类型仅仅作为了解
- 只要可以看到数据可以知道他们的名字,以及如何编写即可
- 学前必会
- 查看数据值的数据类型使用
type(数据值)\type(变量名)
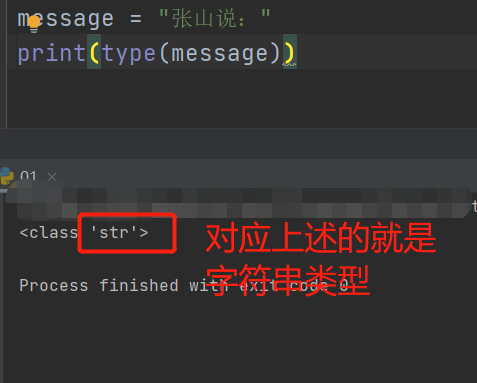
- 查看数据值的数据类型使用
整数型int
整数形的应用场景记录整数数据
年龄 事物的个数 天数
代码实现:
age = 18
day = 10
浮点型float
浮点型的应用场景记录小数数据
身高,体重
代码实现:
weidth = 189.1
height = 180.88
字符串str
字符串的应用场景记录文本数据
姓名 性别 地址
代码实现:
name = '张三'
gender = 'man'
1.定义字符串的4种方式
name1 = '张三'
name2 = "张三"
name3 = '''张三'''
name4 = """张三"""
为什么字符串需要多种方式
-
我们在字符串中编写文本可能会使用到引号,为了避免冲突 有了多种方式
-
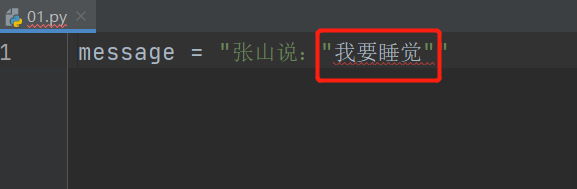
因为在python中字符串定义" "或' '是成对匹配,这样前面的引号与说的话引号匹配,然而那句话没有匹配,这样就导致,解释器不认识这句话从而出错
-
如何区分三引号是字符串还是注释关注左侧是否有赋值符号和变量名,如果有则为字符串 没有则为注释
列表list
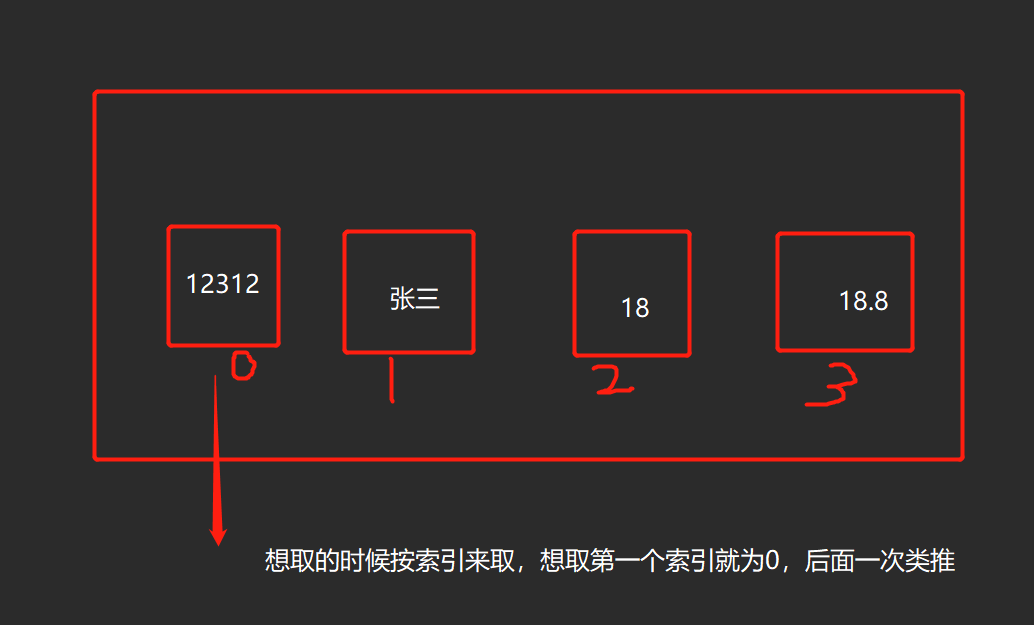
直白说的意思其实就是可以存储多个数据值的类型 并且可以非常方便的取
列表的应用场景用于存储数据值 并且将来可能需要单独去其中一些
代码实现:
name_list = ['张三', '李四', '王五', '老六']
列表文字描述
中括号括起来 内部可以存放多个数据值,数据值与数据值之间逗号隔开 数据值可以是任意数据类型
num = [12, 13 , 111, [13, 3123, 'boy']]
索引取值
起始数字是从0开始
变量名[索引值]
num[1]-->13
字典dict
能够非常精确的存储和表达数据值的含义
字典的应用场景,方便知道这个数据代表的是什么意思,组织形式k:v键值对表示
k就是数据的关键字对v的描述性质的新(解释说明)
v就是真正的数据值可以是任意数据类型
代码实现:
preson_dict={
'name': '张三',
'age': 18,
'salary': 188,
}
按K取值
字典只能按K取值 因为字典是无序的 不能索引
preson_dict['name']-->张三
元组tuple
- 元组创建是形式
name = ('zhangsan', 'lishi', 'wangwu') - 元组不能被修改,也称之为‘不可变列表’
底层原理是在绑定变量时,其实绑定的是索引位置,索引位置是直接与数据值绑定,元组不允许索引与数据值重新绑定
而列表可以重新绑定
例如
元组里面可以嵌套其他元素,而嵌套的元素遵守他原本的规则,不需要遵守父级规则如下 - counts = (1312, 'abc', '张三',['cat','abcd', 111])
counts[2][1] = 666 # 这时(1312, 'abc', '张三',['cat','abcd', 666])就变成这样了
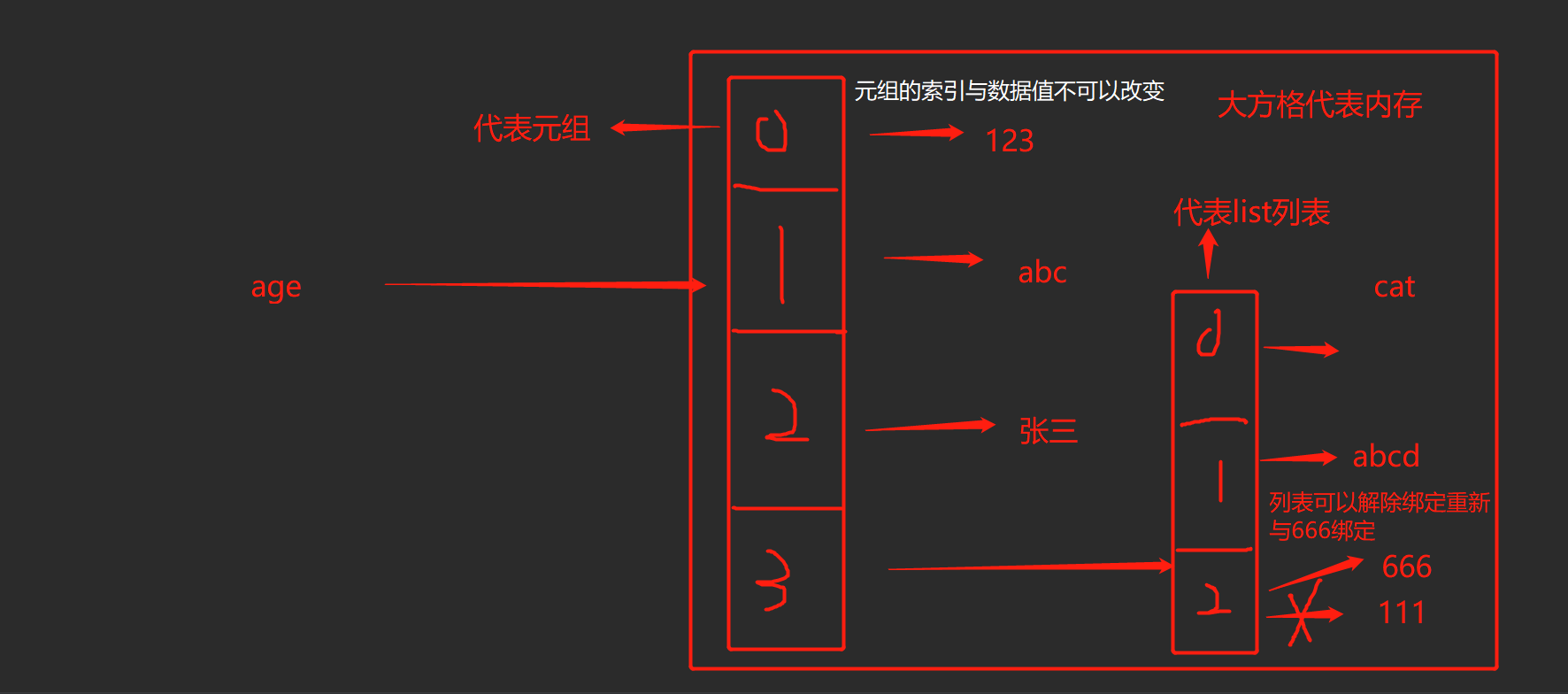
在使用元组时只有一个元素时逗号不能忘
age = (123, )
如果没有写只有单个元素者,表示原本数据类型而不是元组
集合set
用于判断事物的对此,是否可行 只要用于流程控制中
去重,和关系运算
代码形式
nums = {123, 456, 789}
比较特殊,元素只能存固定类型元素即可哈希元素。
{} 默认是空字典
set() 是空集合
创建空集合时用 age = set(s)
不能索引取值
布尔bool
Ture False 两种状态
所有数据类型本身都具有布尔类型
数据类型为False的是,0 ‘’ {} [] 空set () 空tuple None
数据类型为True的是,除了为False的其余都是True
变量的命名一样用is开头如下
is_alive = True
is_delete = False
如果函数返回值也是布尔类型函数名也建议使用is开头的如
def is_login():
pass
return True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号