Android quickstart for tensorflow lite
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
3. 使用模型进行推理
推理(Inference) 是通过模型(model)运行数据(data)以获得预测(predictions)的过程。这个过程需要模型(model)、解释器(interpreter)和输入数据(input data)。
TensorFlow Lite 解释器
TensorFlow Lite 解释器是一个库,该库会接收模型文件,执行它对输入数据定义的运算,并提供对输出的访问。
该解释器(interpreter)适用于多个平台,提供了一个简单的 API,用于从 Java、Swift、Objective-C、C++ 和 Python 运行 TensorFlow Lite 模型。
以下代码展示了从 Java 调用的解释器:
try (Interpreter interpreter = new Interpreter(tensorflow_lite_model_file)) {
interpreter.run(input, output);
}
GPU 加速和委托
有些设备为机器学习运算提供了硬件加速。例如,大多数手机都有 GPU,它们能够比 CPU 更快地执行浮点矩阵运算。
这种速度提升可能会非常可观。例如,当使用 GPU 加速时,MobileNet v1 图像分类模型在 Pixel 3 手机上的运行速度能够提高 5.5 倍。
TensorFlow Lite 解释器可以配置委托,以利用不同设备上的硬件加速。GPU 委托允许解释器在设备的 GPU 上运行适当的运算。
以下代码显示从 Java 使用的 GPU 委托:
GpuDelegate delegate = new GpuDelegate();
Interpreter.Options options = (new Interpreter.Options()).addDelegate(delegate);
Interpreter interpreter = new Interpreter(tensorflow_lite_model_file, options);
try {
interpreter.run(input, output);
}
要添加对新硬件加速器的支持,您可以定义自己的委托。
摘自 https://tensorflow.google.cn/lite/guide/android
o get started with TensorFlow Lite on Android, we recommend exploring the following example.
Android image classification example
Read TensorFlow Lite Android image classification for an explanation of the source code.
This example app uses image classification to continuously classify whatever it sees from the device's rear-facing camera. The application can run either on device or emulator.
Inference is performed using the TensorFlow Lite Java API and the TensorFlow Lite Android Support Library. The demo app classifies frames in real-time, displaying the top most probable classifications. It allows the user to choose between a floating point or quantized model, select the thread count, and decide whether to run on CPU, GPU, or via NNAPI.
Build in Android Studio
To build the example in Android Studio, follow the instructions in README.md.
Create your own Android app
To get started quickly writing your own Android code, we recommend using our Android image classification example as a starting point.
The following sections contain some useful information for working with TensorFlow Lite on Android.
Use Android Studio ML Model Binding
To import a TensorFlow Lite (TFLite) model:
-
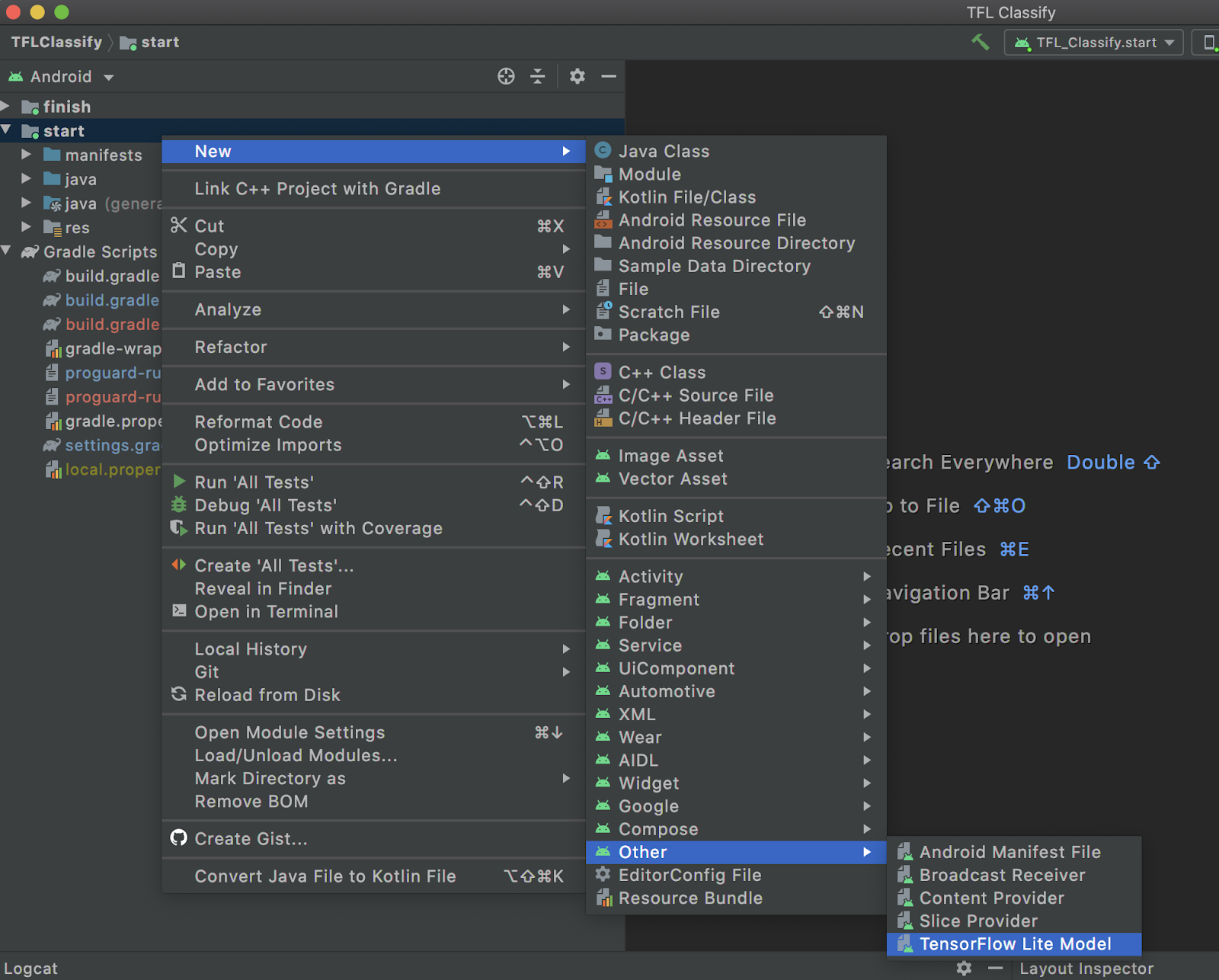
Right-click on the module you would like to use the TFLite model or click on
File, thenNew>Other>TensorFlow Lite Model![]()
-
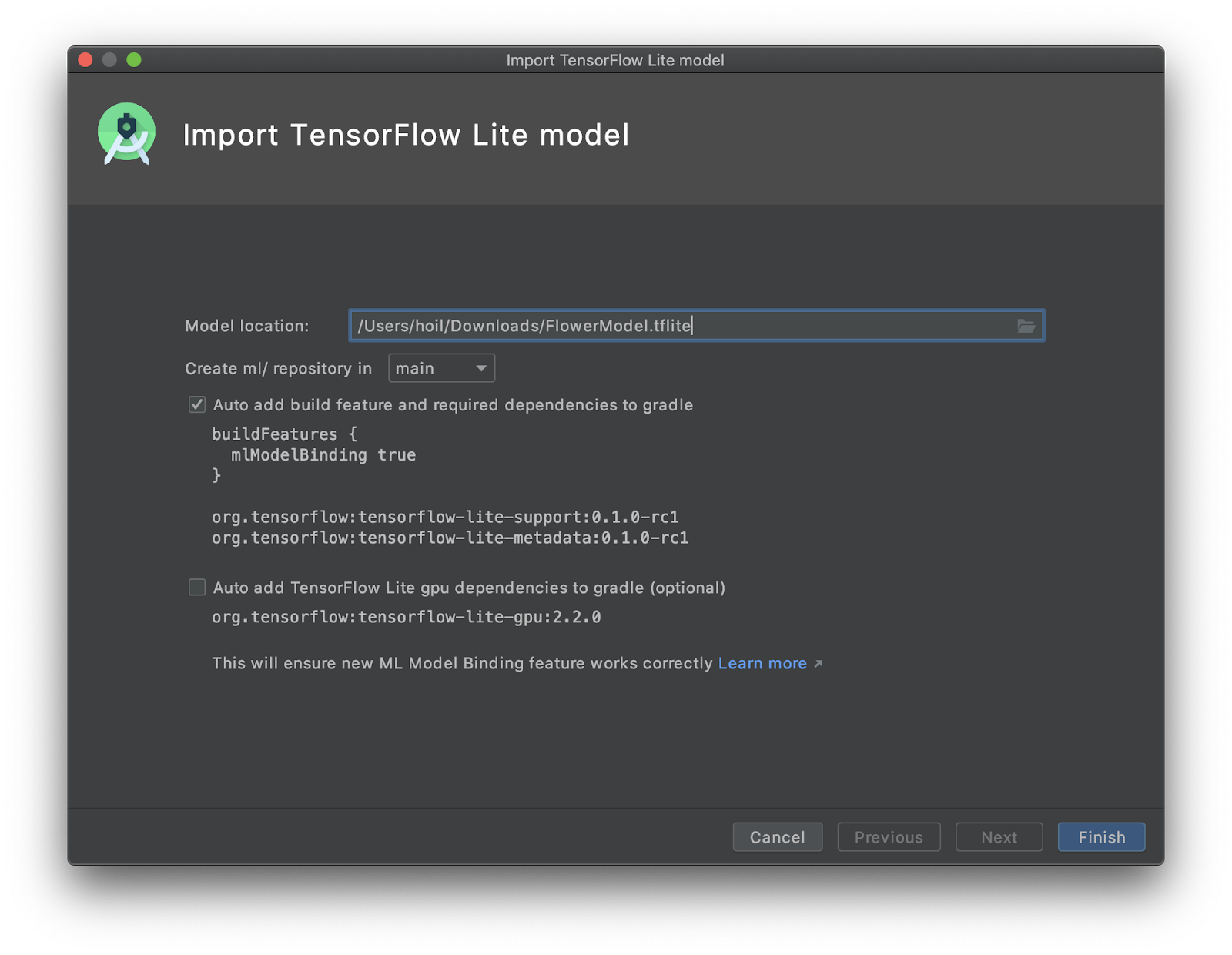
Select the location of your TFLite file. Note that the tooling will configure the module's dependency on your behalf with ML Model binding and all dependencies automatically inserted into your Android module's
build.gradlefile.Optional: Select the second checkbox for importing TensorFlow GPU if you want to use GPU acceleration.
![]()
-
Click
Finish. -
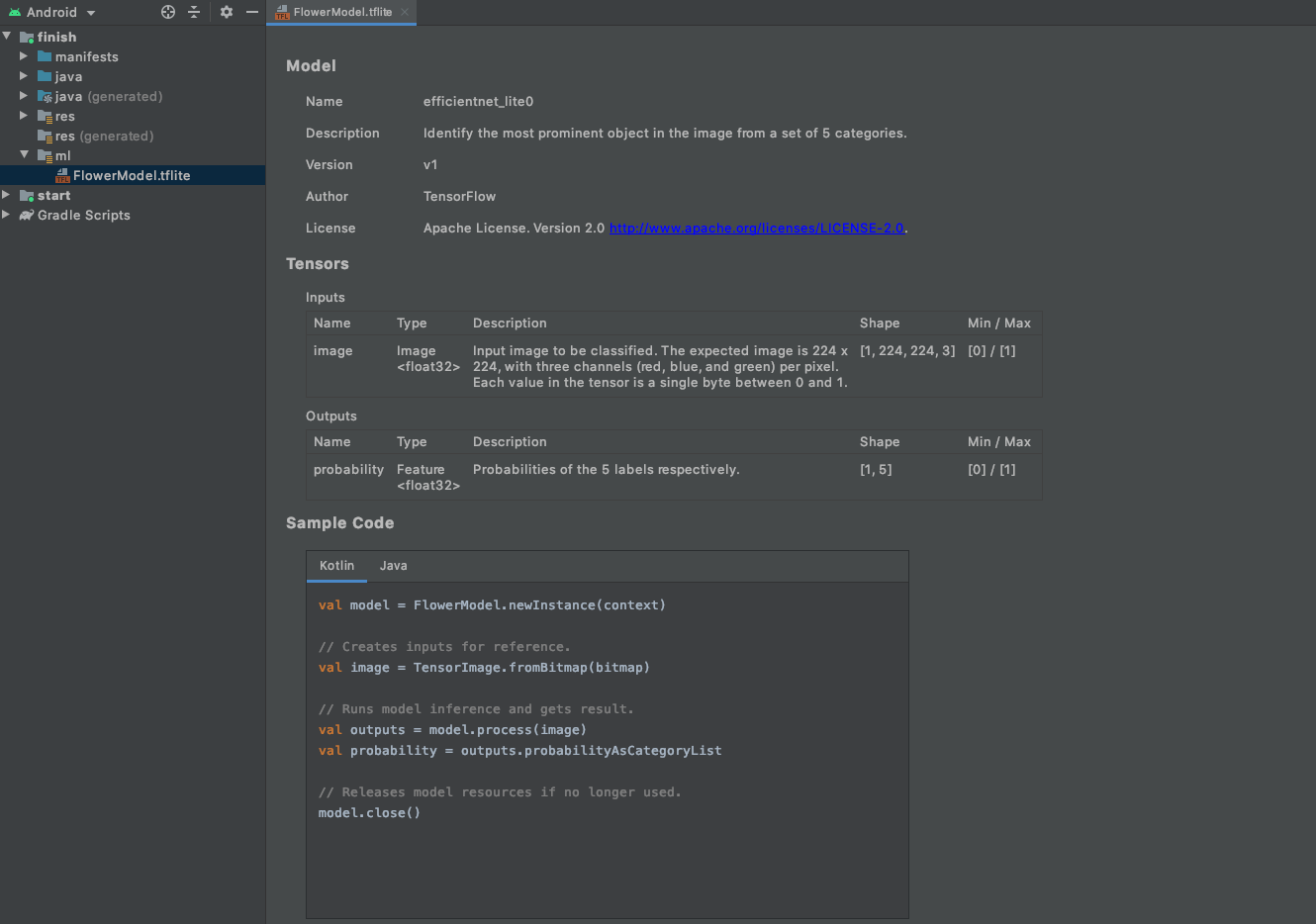
The following screen will appear after the import is successful. To start using the model, select Kotlin or Java, copy and paste the code under the
Sample Codesection. You can get back to this screen by double clicking the TFLite model under themldirectory in Android Studio.![]()
Use the TensorFlow Lite Task Library
TensorFlow Lite Task Library contains a set of powerful and easy-to-use task-specific libraries for app developers to create ML experiences with TFLite. It provides optimized out-of-box model interfaces for popular machine learning tasks, such as image classification, question and answer, etc. The model interfaces are specifically designed for each task to achieve the best performance and usability. Task Library works cross-platform and is supported on Java, C++, and Swift (coming soon).
To use the Support Library in your Android app, we recommend using the AAR hosted at MavenCentral for Task Vision library and Task Text library , respectively.
You can specify this in your build.gradle dependencies as follows:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-task-vision:0.1.0'
implementation 'org.tensorflow:tensorflow-lite-task-text:0.1.0'
}
To use nightly snapshots, make sure that you have added Sonatype snapshot repository.
See the introduction in the TensorFlow Lite Task Library overview for more details.
Use the TensorFlow Lite Android Support Library
The TensorFlow Lite Android Support Library makes it easier to integrate models into your application. It provides high-level APIs that help transform raw input data into the form required by the model, and interpret the model's output, reducing the amount of boilerplate code required.
It supports common data formats for inputs and outputs, including images and arrays. It also provides pre- and post-processing units that perform tasks such as image resizing and cropping.
To use the Support Library in your Android app, we recommend using the TensorFlow Lite Support Library AAR hosted at MavenCentral.
You can specify this in your build.gradle dependencies as follows:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-support:0.1.0'
}
To use nightly snapshots, make sure that you have added Sonatype snapshot repository.
To get started, follow the instructions in the TensorFlow Lite Android Support Library.
Use the TensorFlow Lite AAR from MavenCentral
To use TensorFlow Lite in your Android app, we recommend using the TensorFlow Lite AAR hosted at MavenCentral.
You can specify this in your build.gradle dependencies as follows:
dependencies {
implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly-SNAPSHOT'
}
To use nightly snapshots, make sure that you have added Sonatype snapshot repository.
This AAR includes binaries for all of the Android ABIs. You can reduce the size of your application's binary by only including the ABIs you need to support.
We recommend most developers omit the x86, x86_64, and arm32 ABIs. This can be achieved with the following Gradle configuration, which specifically includes only armeabi-v7a and arm64-v8a, which should cover most modern Android devices.
android {
defaultConfig {
ndk {
abiFilters 'armeabi-v7a', 'arm64-v8a'
}
}
}
To learn more about abiFilters, see NdkOptions in the Android Gradle documentation.
Load and run a model in Java
Platform: Android
The Java API for running an inference with TensorFlow Lite is primarily designed for use with Android, so it's available as an Android library dependency: org.tensorflow:tensorflow-lite.
In Java, you'll use the Interpreter class to load a model and drive model inference. In many cases, this may be the only API you need.
You can initialize an Interpreter using a .tflite file:
public Interpreter(@NotNull File modelFile);
Or with a MappedByteBuffer:
public Interpreter(@NotNull MappedByteBuffer mappedByteBuffer);
In both cases, you must provide a valid TensorFlow Lite model or the API throws IllegalArgumentException. If you use MappedByteBuffer to initialize an Interpreter, it must remain unchanged for the whole lifetime of the Interpreter.
The preferred way to run inference on a model is to use signatures - Available for models converted starting Tensorflow 2.5
try (Interpreter interpreter = new Interpreter(file_of_tensorflowlite_model)) {
Map<String, Object> inputs = new HashMap<>();
inputs.put("input_1", input1);
inputs.put("input_2", input2);
Map<String, Object> outputs = new HashMap<>();
outputs.put("output_1", output1);
interpreter.runSignature(inputs, outputs, "mySignature");
}
The runSignature method takes three arguments:
-
Inputs : map for inputs from input name in the signature to an input object.
-
Outputs : map for output mapping from output name in signature to output data.
-
Signature Name [optional]: Signature name (Can be left empty if the model has single signature).
Another way to run an inference when the model doesn't have a defined signatures. Simply call Interpreter.run(). For example:
try (Interpreter interpreter = new Interpreter(file_of_a_tensorflowlite_model)) {
interpreter.run(input, output);
}
The run() method takes only one input and returns only one output. So if your model has multiple inputs or multiple outputs, instead use:
interpreter.runForMultipleInputsOutputs(inputs, map_of_indices_to_outputs);
In this case, each entry in inputs corresponds to an input tensor and map_of_indices_to_outputs maps indices of output tensors to the corresponding output data.
In both cases, the tensor indices should correspond to the values you gave to the TensorFlow Lite Converter when you created the model. Be aware that the order of tensors in input must match the order given to the TensorFlow Lite Converter.
The Interpreter class also provides convenient functions for you to get the index of any model input or output using an operation name:
public int getInputIndex(String opName);
public int getOutputIndex(String opName);
If opName is not a valid operation in the model, it throws an IllegalArgumentException.
Also beware that Interpreter owns resources. To avoid memory leak, the resources must be released after use by:
interpreter.close();
For an example project with Java, see the Android image classification sample.
Supported data types (in Java)
To use TensorFlow Lite, the data types of the input and output tensors must be one of the following primitive types:
floatintlongbyte
String types are also supported, but they are encoded differently than the primitive types. In particular, the shape of a string Tensor dictates the number and arrangement of strings in the Tensor, with each element itself being a variable length string. In this sense, the (byte) size of the Tensor cannot be computed from the shape and type alone, and consequently strings cannot be provided as a single, flat ByteBuffer argument.
If other data types, including boxed types like Integer and Float, are used, an IllegalArgumentException will be thrown.
Inputs
Each input should be an array or multi-dimensional array of the supported primitive types, or a raw ByteBuffer of the appropriate size. If the input is an array or multi-dimensional array, the associated input tensor will be implicitly resized to the array's dimensions at inference time. If the input is a ByteBuffer, the caller should first manually resize the associated input tensor (via Interpreter.resizeInput()) before running inference.
When using ByteBuffer, prefer using direct byte buffers, as this allows the Interpreter to avoid unnecessary copies. If the ByteBuffer is a direct byte buffer, its order must be ByteOrder.nativeOrder(). After it is used for a model inference, it must remain unchanged until the model inference is finished.
Outputs
Each output should be an array or multi-dimensional array of the supported primitive types, or a ByteBuffer of the appropriate size. Note that some models have dynamic outputs, where the shape of output tensors can vary depending on the input. There's no straightforward way of handling this with the existing Java inference API, but planned extensions will make this possible.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号