sql的简单操作
mysql
一、mysql简介和安装


MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
总结:mysql就是一个基于socket编写的C/S架构的软件
1.安装: 添加系统环境变量D:\mysql-5.7.23-winx64\bin 2.初始化: mysqld --initialize-insecure 3. 安装windows服务:mysqd --install 4..单独用cmd杀死服务进程 查看进程号:tasklist |findstr mysql 杀死服务端的进程:taskkill /F /PID 进程号 5. 开启服务:net start mysql 关闭服务: net stop mysql 6. 登录:mysql -uroot -p Update mysql.user set authentication_string =password('123') where User='root'; //修改密码 flush privileges;//刷新权限
二、密码破解和配置
- 先把原来mysql服务端关闭 - 管理员身份运行执行:mysqld --skip-grant-tables - 客户端连接服务端 此时修改密码,注意修改密码之后一定要刷新权限
同一字符串编码(配置my.ini文件)
my.ini// mysql 文件夹下边统一使用(有的需要在路径上加转义符!)
[mysqld] # 设置为自己MYSQL的安装目录 basedir=E:\sql #basedir=E:\\sql # 设置为MYSQL的数据目录 datadir=E:\sql\data\ #datadir=E:\\sql\data\ port=3306 character_set_server=utf8 sql_mode=NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY #开启查询缓存 explicit_defaults_for_timestamp=true #skip-grant-tables [client] port=3306 #默认端口号 default-character-set=utf8 #编码格式是utf8
注:一定要重启MySQl服务器
三、用户创建
# 指定ip:192.118.1.1的name用户登录 create user 'name'@'192.118.1.1' identified by '123'; # 指定ip:192.118.1.开头的name用户登录 create user 'name'@'192.%.%.%' identified by '123'; # 指定任何ip的name用户登录 create user 'name'@'%' identified by '123'; select distinct user from mysql.user; //查看当前所有的管理员 delete from mysql.user where user='mjj'; //删除mjj 这个账户 delete from mysql.user where user=''; //删除没有名字的空账户 进入mysql客户端,执行\s //查看当前显示配置信息
四、常用的sql语句
show databases; 查看所有的数据库 创建数据库 create database db1; 使用数据库 use db1; 创建表 create table s1(id int,name char(20)); 插入数据 nsert into s1 values(1,'娜扎'),(2,'alex'); desc s1;
五、给账户权限:
#授权 mjj用户仅对db1.t1文件有查询、插入和更新的操作 grant select on db1.s1 to "mjj"@'%'; # 表示有所有的权限,除了grant这个命令,这个命令是root才有的。mjj用户对db1下的t1文件有任意操作 grant all privileges on db1.t1 to "mjj"@'%'; #mjj用户对db1数据库中的文件执行任何操作 grant all privileges on db1.* to "mjj"@'%'; #mjj用户对所有数据库中文件有任何操作 grant all privileges on *.* to "mjj"@'%'; #查看所有用户的所有信息 select * from mysql.user; select host,user from mysql.user where user=’账户名字’ #取消授权 revoke select on db1.s1 from "mjj"@'%'; #登录 mysql -umjj -h 192.168.12.74 -p //账号 123 //密码
数据驱动视图:所谓的数据驱动就是当数据发生变化的时候,用户界面发生相应的变化,开发者不需要手动的去修改dom。
查看所有的属性字段类型语句:select * from information_schema.columns where table_name='表名';
六、数据类型
数值类型:储存引擎&约束(符号:正负)
默认是有符号(-128,127)
create table t1(id int)engine=innodb;#//存储引擎 支持事务(默认)
create table t2(id int)engine=myisam;#//存储引擎 不支持事务
create table t3(id int)engine=memory;#//内存存储引擎
create table t4(id int)engine=blackhole; #//黑洞存储引擎
无符号的 (0,255)
unsigned:给当前的字段设置约束
create table t2(x tinyint unsigned);
浮点型:
Float:只能精确到6位(以小数点左边开始计算)
Double:在位数比较长的情况下不精准(对比float精确点)
decimal:(如果用小数,则用推荐使用decimal)
--精准(内部原理是以字符串形式去存储)
时间:
Year
YYYY(1901/2155)
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS('-838:59:59'/'838:59:59')
DATETIME :(时间 常用3) ***
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59)
--create table time_table(time datetime);
插入时间可以调用sql自身函数:now()//获得现在的时间。
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
字符:
char 定长 存储速度快,但是浪费空间 //名字啥的简单的用这个
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
两个小命令:length():查看字节数,char_length():查看字符数
varchar 变长 存储速度慢,节省空间 // 文章啥的用这个
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
enum:单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
Set:多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
create table 学生信息(
id int unsigned,
name char(20),
sex enum('男','女') not null default '男',
hobby set('抽烟','喝酒','烫头')
);
insert into consumer(id,name,sex,fav) values (1,name,'男','抽烟,烫头');
#insert into consumer(id,name,sex) values (2,'name2','男');
七 、表的约束
作用:保证数据的完整性和一致
- not null 和default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
create table tb2(
# 如果插入空值,默认是2
nid int not null default 2, //nid 数字 不能为空, 默认为2
num int not null //num 数字 非空
);
desc 表单名; //查看表单属性
insert into tb1(nid) values(3); //调单tb1里边写入3 //报错 因为 num不能为空
- unique
不同的唯一的,
单列唯一
只有一列是唯一
create table department(
id int,
name char(10) unique
);
insert into department values(1,'it'),(2,'it2');
//第二例如果 it2改成it 重复后就直接报错
多列唯一
每个字段都设置unique
create table department2(
id int unique,
name char(10) unique
);
或
create table department2(
id int,
name char(10),
unique(id),
unique(name)
);
# 每个字段插入的值都是不同的才能插入
insert into department2 values(1,'it'),(2,'it2');
组合唯一
create table department3(
id int,
name char(10),
unique(id,name)
);
insert into department3 values(1,'it'),(2,'it');
只要有一个字段不一样,都可以插入
primary key:主键 在现在sql版本中 只允许 表中有一个主键,通常主键是id
not null + unique //性质一样
create table t2(
id int primary key,
name char(10) not null
);
create table t3(
id int not null unique,
name char(10) not null
);
auto_increment :自增长
create table student(
id int primary key auto_increment,
name char(20) not null
);
insert into student(name) values('nazha');
八、外键
(1)创建被关联表(主表)
create table dep(
id int primary key auto_increment,
name varchar(20) not null,
descripe char(40) not null
);
create table test(
id int primary key auto_increment,
name varchar(20) not null,
descripe char(40) not null
);
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
age int not null,
dep_id int,
test_id int,
constraint fk_dep foreign key(dep_id) references dep(id)
on delete cascade
on update cascade,
#可能还有其他表在相互联系,删除会有各种关联
constraint fk_dep foreign key(test_id) references test(id)
on delete cascade
on update cascade
);

2.外键的变种
假设两个表:先找关系
#1、先站在左表的角度去找
-是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找
-是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#多对一&(一对多):

如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
#一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
书和出版社(多对一&一对多)
create table press(
id int primary key auto_increment,
name varchar(20)
);
create table book(
id int primary key auto_increment,
name varchar(20),
press_id int not null,
constraint fk_book_press foreign key(press_id) references press(id)
on delete cascade
on update cascade
);
insert into press(name) values
('北京工业地雷出版社'),
('人民音乐不好听出版社'),
('知识产权没有用出版社')
;
insert into book(name) values
('九阳神功',1),
('九阴真经',2),
('九阴白骨爪’,2),
('独孤九剑',3),
('降龙十巴掌',2),
('葵花宝典,3');
多对多:作者(讲师)和书(课程)的关系
create table author(
id int primary key auto_increment,
name varchar(20)
);
#这张表就存放了author表和book表的关系,即查询二者的关系查这表就可以了
create table author2book(
id int not null unique auto_increment,
author_id int not null,
book_id int not null,
constraint fk_author foreign key(author_id) references author(id)
on delete cascade
on update cascade,
constraint fk_book foreign key(book_id) references book(id)
on delete cascade
on update cascade,
primary key(author_id,book_id)
分析:
上下表格的关
- Egon:python全栈,爬虫
- Alex:python全栈,爬虫
- Wusir:linux高级,爬虫 web
- Yuanhao:爬虫,web
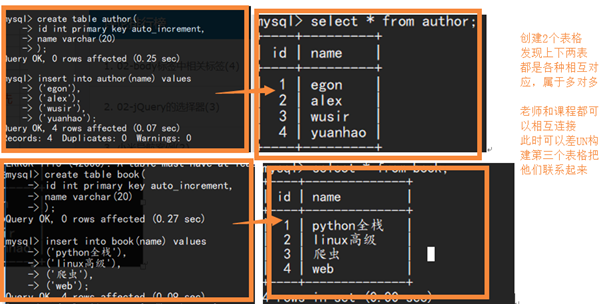
根据id分析出教师 和 课程的id对应 通过第三表对应起来
另行处理
|
Id |
Author_id |
Book_id |
|
1 |
1 |
1 |
|
2 |
1 |
3 |
|
3 |
2 |
1 |
|
4 |
2 |
3 |
|
5 |
3 |
2 |
|
6 |
3 |
3 |
|
7 |
3 |
4 |
|
8 |
4 |
3 |
|
9 |
4 |
4 |

此时把逻辑表格 插入到sql的第三关联表格即可
Insert into author2book(author_id,book_id) values
(1,1),
(1,3),
(2,1),
(2,3),
(3,2),
(3,3),
(3,4),
(4,3),
(4,4);

一对一:一个本一个mac关系
九、单表查询
重点中的重点:关键字的执行优先级
按照条件查找筛选
1. 找到表:form
From //来自于那个表
2.拿着where指定的约束条件,去文件/表中取出一条条记录
Where //满足条件
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
group by //分组
4.将分组的结果进行having过滤
having //再次满足条件
5.执行select
select //查找
6.去重
distinct //去重
7.将结果按条件排序:order by
order by //排序
8.限制结果的显示条数
limit //限制几个
# group by
select A.c from (select post,max(salary)as c from employee group by post) as A;
使用分组;
先设置sql_mode='ONLY_FULL_GROUP_BY' #配置my.ini即可。
分组之后只能查询分组的字段,如果想查询组内的其它字段的信息,必须要借助聚合函数
max()
min()
avg()
sum()
count()
#按照计算符查找
where子句中可以使用
1.比较运算符:>、<、>=、<=、<>、!=
2.between 80 and 100 :值在80到100之间
3.in(80,90,100)值是10或20或30
4.like 'xiaomagepattern': pattern可以是%或者_。%小时任意多字符,_表示一个字符
5.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
查询表结构:desc 表名字
创建一个员工表:
create table employee(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28, #unsigned:无符号的(没有负数的)
hire_date date not null, #入职时间:时间:不能为空
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,#一个部门一个屋
depart_id int
);
#写入信息
insert into employee(name ,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('xiaomage','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#简单的查询
select post,group_concat(name) from employee group by post;

select post,group_concat(name),count(1) from employee group by post having count(1)< 2;

select post,avg(salary) from employee group by post having avg(salary) > 10000;

select sex,avg(salary) from employee group by sex having avg(salary) > 10000;
select post,avg(salary) as A from employee group by post having A > 10000 order by A desc;
select * from employee order by age asc,id desc;
#按照计算符查找
where子句中可以使用
1.比较运算符:>、<、>=、<=、<>、!=
2.between 80 and 100 :值在80到100之间
3.in(80,90,100)值是10或20或30
4.like 'xiaomagepattern': pattern可以是%或者_。%小时任意多字符,_表示一个字符
5.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
十、多表查询
1 内连接-相等连接
相等连接又叫等值连接,在连接条件这使用等号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
示例:
SELECT [dbo].[Category].* , [dbo].[Product].* FROM [dbo].[Category] INNER JOIN [dbo].[Product] ON [dbo].[Category].[CategoryID] = [dbo].[Product].[CategoryID]

SELECT p.[ProductCode], p.[ProductName], c.[CategoryName], d.[Quantity], d.[Subtotal]
FROM [dbo].[Product] p
INNER JOIN [dbo].[Category] c
ON p.[CategoryID] = c.[CategoryID]
INNER JOIN [dbo].[OrderDetails] d
ON p.[ProductID] = d.[ProductID]
2 带选择条件的连接
带选择条件的连接查询是在连接查询的过程中,通过添加过滤条件限制查询的结果,使查询的结果更加准确。
示例:
SELECT [dbo].[Category].* , [dbo].[Product].* FROM [dbo].[Category] INNER JOIN [dbo].[Product] ON [dbo].[Category].[CategoryID] = [dbo].[Product].[CategoryID] AND [dbo].[Category].[CategoryID] = 1
3 自连接
如果在一个连接查询中,涉及到的两个表都是同一个表,这种查询称为自连接查询。自连接是一种特殊的内连接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。
示例:
SELECT c1.CategoryID, c1.CategoryName FROM [dbo].[Category] c1 INNER JOIN [dbo].[Category] c2 ON c1.[CategoryID] = c2.[ParentID]
4 外连接
连接查询将查询多个表中相关联的行,内连接时,返回查询结果集合中的仅是符号查询条件和连接条件的行,但有时需要包含没有关联的行中数据,即返回查询结果集合中的不仅包含符合连接条件的行,还需要包括左表(左外连接或左连接)、右表(右外连接或右连接)或者两个边接表(全外连接)中的所有数据行。外连接分为左外连接和右外连接。
◊ LEFT JOIN(左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
◊ RIGHT JOIN(右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
4.1 左外连接
左连接的结果包括LEFT OUTER JOIN关键字左边连接的表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集中右表的所有选择字段均为NULL。
示例:
SELECT [dbo].[Category].* , [dbo].[Product].* FROM [dbo].[Category] LEFT OUTER JOIN [dbo].[Product] ON [dbo].[Category].[CategoryID] = [dbo].[Product].[CategoryID]
4.2 右外连接
右连接将返回RIGHT OUTER JOIN关键字右边的表中的所有行。如果右表的某行在左表中没有匹配行,左表将返回NULL。
示例:
SELECT [dbo].[Category].* , [dbo].[Product].* FROM [dbo].[Category] RIGHT OUTER JOIN [dbo].[Product] ON [dbo].[Category].[CategoryID] = [dbo].[Product].[CategoryID]
4.3 全外连接
全外连接又称为完全外连接,该连接查询方式返回两个连接中所有的记录数据。根据匹配条件,如果满足匹配条件时,则返回数据;如果不满足匹配条件时,同样返回数据,但在相应的列中填入NULL,全外连接返回的结果集中包含了两个完全表的所有数据。全外连接关键字FULL OUTER JOIN。
示例:
SELECT [dbo].[Category].* , [dbo].[Product].* FROM [dbo].[Category] FULL OUTER JOIN [dbo].[Product] ON [dbo].[Category].[CategoryID] = [dbo].[Product].[CategoryID]
练习
表一 emp

表二 dept

表三 salgrade;
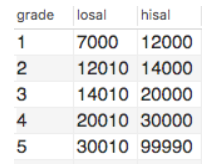
表四 年度利润表

二、习题 1. 查出至少有一个员工的部门。显示部门编号、部门名称、部门位置、部门人数。 2. 列出所有员工的姓名及其直接上级的姓名。 3. 列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。 4. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。 5. 列出最低薪金大于15000的各种工作及从事此工作的员工人数。 6. 列出在销售部工作的员工的姓名,假定不知道销售部的部门编号。 7. 列出薪金高于公司平均薪金的所有员工信息,所在部门名称,上级领导,工资等级。 8.列出与庞统从事相同工作的所有员工及部门名称。 9.列出薪金高于在部门30工作的所有员工的薪金 的员工姓名和薪金、部门名称。 10.查出年份、利润、年度增长比。 三、习题解析 /* 1. 查出至少有一个员工的部门。显示部门编号、部门名称、部门位置、部门人数。 列:d.deptno, d.dname, d.loc, 部门人数 表:dept d, emp e 条件:e.deptno=d.deptno */ SELECT d.*, z1.cnt FROM dept d, (SELECT deptno, COUNT(*) cnt FROM emp GROUP BY deptno) z1 WHERE d.deptno = z1.deptno /* 2. 列出所有员工的姓名及其直接上级的姓名。 列:员工姓名、上级姓名 表:emp e, emp m 条件:员工的mgr = 上级的empno */ SELECT * FROM emp e, emp m WHERE e.mgr=m.empno SELECT e.ename, IFNULL(m.ename, 'BOSS') 领导 FROM emp e LEFT OUTER JOIN emp m ON e.mgr=m.empno /* 3. 列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。 列:e.empno, e.ename, d.dname 表:emp e, emp m, dept d 条件:e.hiredate<m.hiredate 思路: 1. 先不查部门名称,只查部门编号! 列:e.empno, e.ename, e.deptno 表:emp e, emp m 条件:e.mgr=m.empno, e.hiredate<m.hireadate */ SELECT e.empno, e.ename, e.deptno FROM emp e, emp m WHERE e.mgr=m.empno AND e.hiredate<m.hiredate SELECT e.empno, e.ename, d.dname FROM emp e, emp m, dept d WHERE e.mgr=m.empno AND e.hiredate<m.hiredate AND e.deptno=d.deptno /* 4. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。 列:* 表:emp e, dept d 条件:e.deptno=d.deptno */ SELECT * FROM emp e RIGHT OUTER JOIN dept d ON e.deptno=d.deptno /* 5. 列出最低薪金大于15000的各种工作及从事此工作的员工人数。 列:job, count(*) 表:emp e 条件:min(sal) > 15000 分组:job */ SELECT job, COUNT(*) FROM emp e GROUP BY job HAVING MIN(sal) > 15000 /* 6. 列出在销售部工作的员工的姓名,假定不知道销售部的部门编号。 列:e.ename 表:emp 条件:e.deptno=(select deptno from dept where dname='销售部') */ SELECT * FROM emp e WHERE e.deptno=(SELECT deptno FROM dept WHERE dname='销售部') /* 7. 列出薪金高于公司平均薪金的所有员工信息,所在部门名称,上级领导,工资等级。 列:* 表:emp e 条件:sal>(查询出公司的平均工资) */ SELECT e.*, d.dname, m.ename, s.grade FROM emp e, dept d, emp m, salgrade s WHERE e.sal>(SELECT AVG(sal) FROM emp) AND e.deptno=d.deptno AND e.mgr=m.empno AND e.sal BETWEEN s.losal AND s.hisal --------------- SELECT e.*, d.dname, m.ename, s.grade FROM emp e LEFT OUTER JOIN dept d ON e.deptno=d.deptno LEFT OUTER JOIN emp m ON e.mgr=m.empno LEFT OUTER JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal WHERE e.sal>(SELECT AVG(sal) FROM emp) SELECT * FROM emp; SELECT * FROM dept; SELECT * FROM salgrade; /* 8.列出与庞统从事相同工作的所有员工及部门名称。 列:e.*, d.dname 表:emp e, dept d 条件:job=(查询出庞统的工作) */ SELECT e.*, d.dname FROM emp e, dept d WHERE e.deptno=d.deptno AND job=(SELECT job FROM emp WHERE ename='庞统') /* 9.列出薪金高于在部门30工作的所有员工的薪金 的员工姓名和薪金、部门名称。 列:e.ename, e.sal, d.dname 表:emp e, dept d 条件;sal>all (30部门薪金) */ SELECT e.ename, e.sal, d.dname FROM emp e, dept d WHERE e.deptno=d.deptno AND sal > ALL (SELECT sal FROM emp WHERE deptno=30) /* 10.查出年份、利润、年度增长比 */ SELECT y1.*, IFNULL(CONCAT((y1.zz-y2.zz)/y2.zz*100, '%'), '0%') 增长比 FROM tb_year y1 LEFT OUTER JOIN tb_year y2 ON y1.year=y2.year+1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号