


Optimize Triangle Mesh Vertex
仅供个人学习使用,请勿转载,勿用于任何商业用途。
对同一个triangle mesh,用TriangleList还是TriangleStrip渲染比较快,快在哪里?大部分人都会不加思索的认为strip比较快,原因在于strip有更好的缓存。这样的回答其实是完全错误的。对以相同方式排列的mesh来说,strip唯一的优点只在于需要的索引比较少,对n个三角形只需要n+2个索引,而list需要n*3个。虽然较少的数据意味着更低的带宽占用,但实际情况下,却对渲染影响不大,无论list和strip,索引本身的数据量就不大(与vertex相比),因此微小的优势几乎很难察觉出来。
那么对同一个mesh,不同的渲染方法会不会有差别,如果有,差别在哪里呢?答案显然是肯定的,否则就不会有这篇文章的存在。真正决定一个mesh渲染效率的是其索引排列方式或者说三角形排列顺序,优秀的排列方式可以明显减少顶点和像素处理的操作。
这就要从硬件的构架上说起了,显卡上除了众所周知的显存外,在GPU芯片上还有一块非常快的缓存,根据资源类型的不同,这块缓存又分为纹理缓存,顶点缓存等等。这里我们主要关心顶点缓存。下图是nvidia G80构架之前的GPU流水线:
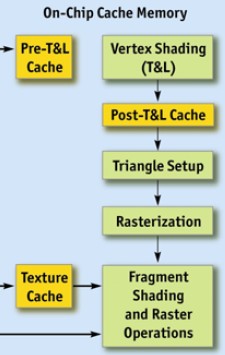
可以看到顶点缓存有两块(vCache),一块称为pre-T&L cache另一块称为Post-T&L Cache。Pre-cache中储存了待处理的顶点,post cache中保存了经过变换(也就是Vertex shader之后)的顶点。正是由于这两块缓存的存在,才让优化成为了可能。两块cache都是FIFO的队列,假设要渲染如下图所示的三角形mesh:

顶点索引为:
1,2,15|15,2,16|2,3,16|16,3,17 ………… 15,16,29|29,16,30………………..
vcache的状态如下:
1,2,15 ---> 1,2,15,16 ---> 1,2,15,16,3----> 1,2,15,16,3,17 ---> …………--->xx,xx,xx,15,16,29 ----> xx,xx,15,16,29,30--->…………….
同一个顶点只会在vcache中出现一次,当渲染第二个三角形时,顶点15和2已经在pre-cache中, GPU不需要对他们做进一步查找,只需请求把顶点16加载到pre-cache中,降低了带宽需求,减小了vertex fetch的延迟。这还不是最重要的,更大的加速在于当GPU准备处理顶点15和2时,发现这2个顶点已经存在于post-cache中,于是它会完全跳过vertex shader的计算,直接使用post-cache中的结果!通过对封闭mesh的分析可以发现通常一个顶点会被5~6个三角形共享(比如图中的顶点16),这意味着在最理想的索引方式下,这个顶点只会被处理一次,当然最糟的情况则是6次,两者之间有巨大的差别。由于vcache容量的限制,可以看到当渲染第二排三角形时,顶点15,16已经被弹出了缓冲,因此GPU将进行重复计算。
我们已经知道了vcache的原理,如何充分利用他计算出最优的三角形索引顺序呢?以上面的规则三角形网格为例,理想的索引应该是这样的:
1,2,3|4,5,6|7,8,9|10,11,12|13,14,14| + |1,2,15|15,2,16|2,3,16|………………………
为了方便讨论,我把索引写成了2段。如果你细心的话就会发现第一段实际上是一系列退化三角形,他们并不会产生任何图形,但恰好把第一排的顶点全部放入了缓冲中。当渲染实际三角形时,每一排的顶点将依次加载到vcache中:
vcache state after degenerate triangle:1,2,3,4,5,6,7,8,9,10,11,12,13,14;
vcache state after first line of triangle:1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23……….29;
vcache state after second line:15,16,17,18,19,20,21……….29,30,31,32……..44
显然,这就是最理想的索引顺序,所有顶点都被完全复用。不过实际情况要复杂的多,显然,这里假设vcache至少能容纳28个顶点,此外这个算法严重依赖于vcache大小,最后,这个算法只对规则mesh比较有效(非常适合于地形J)。对于第一个问题,在dx9上可以通过IDirect3DQuery9查询VCACHE获得实际vcache的大小,不过ati的卡从来不支持这个查询。对于dx10来说,在beta的时候有一个类似查询函数,可惜在后面的版本中删除了。不过我们可以确定的是对于nvidia Geforce 4~7系列的显卡,vcache大小至少为24,8系列至少为32。而对于ati来说,除dx10级别的卡以外,大部分的vcache只有14:( 。显然,对于vcache只有24的情况来说,上面网格的索引计算就变得有些复杂了,一种可行的方法是把网格分为两个子列来渲染,对于复杂模型来说,前人们已经发明了很多优秀的算法Hoppe的研究成果产生了dx中optimizeMesh这样的函数,Forsyth还发明出了一种不依赖于vcache大小的算法。最后由于triangle list索引本身的灵活性,更容易排列出最优的三角形顺序。
上面只讨论了mesh优化的一方面,称为顶点级优化,还有一种近年来伴随early-z出现的像素级优化。不过由于这种算法本身比较复杂,这里只介绍基本原理。对于同一个mesh来说,假设有a,b两个朝向相同,但是相互遮挡的面,假设a挡住b,那么在渲染时,如果先渲染a,就可以让b所产生的像素被early-z剔除,避免无用的pixel shader计算。
顶点优化的作用和意义是明显的,可以在基本不修改现有程序的情况下,得到显著性能提升。那么我们应该如果优化呢?幸运的是已经有这样的优化工具了,前面提到的OptimizeMesh以及nvidia的NvTriStrip工具都实现了顶点级的优化,而ati的Tootle工具不但实现了顶点优化,还采用了一些更先进的算法进行模型遮挡优化。
最后需要说明的是上面的讨论大部分基于dx9级别的硬件构架,对于dx10级别的显卡来说,由于统一构架带来的优点,硬件本身有更好的缓存机制,但无论如何,在模型预处理过程中,优化顶点都是非常值得的。回到开头的问题,其实无论list还是strip,索引储存方式本身并不会带来很大区别,而索引本身的组织方式才是关键,由于list更容易优化,所以对现代硬件来说,优化之后的list通常更快。

