深入了解Kafka【二】工作流程及文件存储机制

1、Kafka工作流程
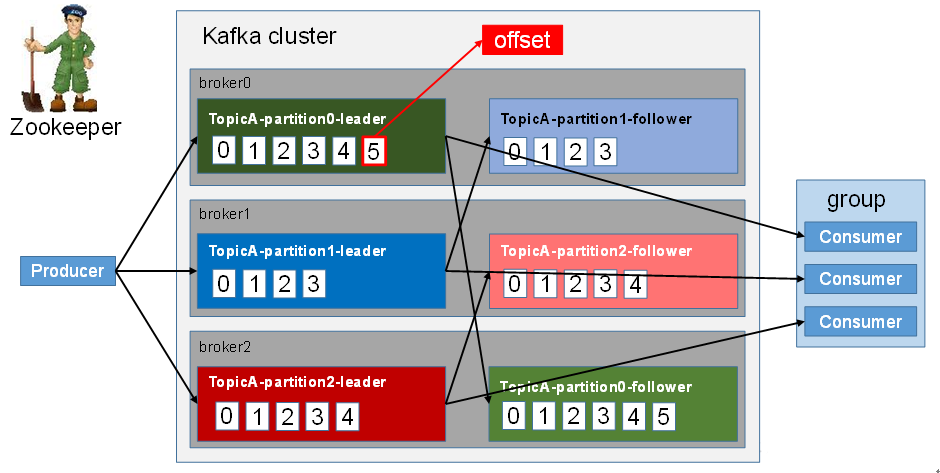
Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据。
Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个Segment,每个Segment对应两个文件,一个索引文件,一个日志文件。Producer生产的数据会被不断的追加到日志文件的末端,且每条数据都有自己的offset。消费组中的每个Consumer都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
2、文件存储机制
由于Producer产生的消息会不断的追加到日志文件的末尾,这样将对消息文件的维护以及以消费的消息的清理带来严重的影响,因此,Kafka引入的分片和索引的设计。每个Partition对应一个文件夹;“topic名称 分区序号”。每个Partition分为多个Segment,Segment分为两类文件:“.index”索引文件与“.log”数据文件,其中索引文件和数据文件都在Partition对应的文件夹中。
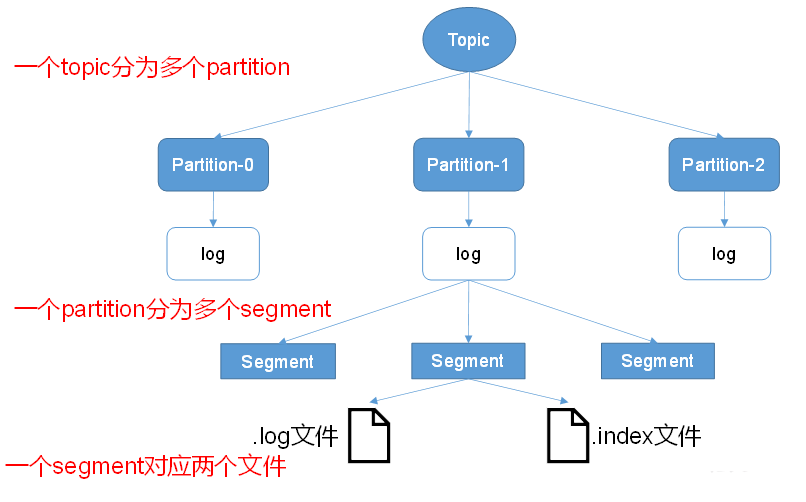
假设test-topic有3个分区,则对应的文件夹名称为:test-topic-0、test-topic-1、test-topic-2。
partition文件夹下文件形如:
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
可以看到有索引文件与数据文件,有3个Segment。
这两个文件的命令规则为:Partition全局的第一个Segment从0开始,后续每个Segment文件名为上一个Segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充。
以Segment文件的详细内容:
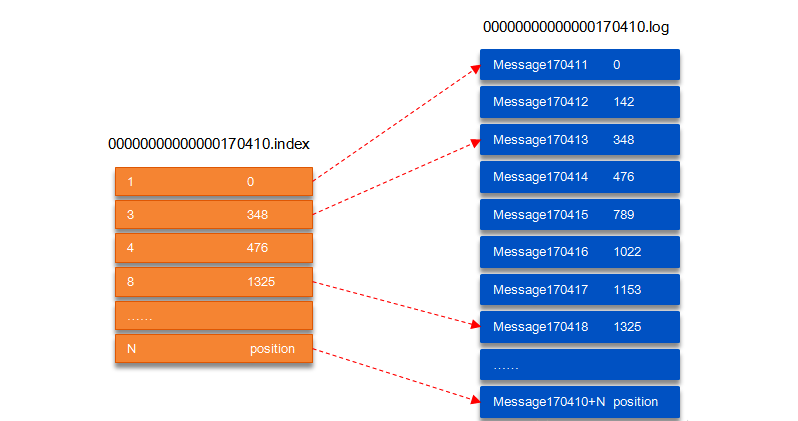
图中,索引文件存储的元数据指向数据文件中的message的物理偏移地址。
3、从partition中通过offset查找message
以上图为例,读取offset=170418的消息,首先查找segment文件,其中00000000000000000000.index 为最开始的文件,第二个文件为 00000000000000170410.index(起始偏移为 170410 1=170411),而第三个文件为 00000000000000239430.index(起始偏移为 239430 1=239431),所以这个 offset=170418 就落到了第二个文件之中。其它后续文件可以依次类推,以其偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次根据 00000000000000170410.index 文件中的 [8,1325] 定位到 00000000000000170410.log 文件中的 1325 的位置进行读取。要是读取 offset=170418 的消息,从 00000000000000170410.log 文件中的 1325的位置进行读取,那么,如何确定何时读完本条消息呢?
这个问题由消息的物理结构解决,消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。
参考
深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列


 浙公网安备 33010602011771号
浙公网安备 33010602011771号