分布式ID生成方案汇总

1、目标
1.1、全局唯一
不能出现重复的ID,全局唯一是最基本的要求。
1.2、趋势有序
业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件。
而且Mysql InnoDB存储引擎主键使用聚集索引,主键有序则写入性能更高。
1.3、高可用
ID是一条数据的唯一标识,如果ID生成失败,则影响很大,业务执行不下去。所以好的ID方案需要有高可用。
1.4、信息安全
ID虽然趋势有序,但是不可以被看出规则,免得被爬取信息。
了解到一个有意思的事情:基于MAC地址生成UUID的算法造成的MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
2、常见方案介绍
2.1、UUID
UUID(Universally Unique Identifier)是最简单的生成方案了:
UUID.randomUUID().toString()
生成形如:e811b49b-9ac1-47dc-8ab9-98fa7dd861d0的8-4-4-4-12的字符串。
优点
- 简单
- 性能好
- 全球唯一
缺点
- 无序
- 不能标识出此ID的含义,不可读。
- 字符串太长且无序,作为MySQL主键,影响性能。
2.2、snowflake方案
snowflake是twitter开源的分布式ID生成算法,核心思想是:一个Long类型的ID,其中41bit作为毫秒数,10bit作为机器码,12bit作为毫秒内序列号。
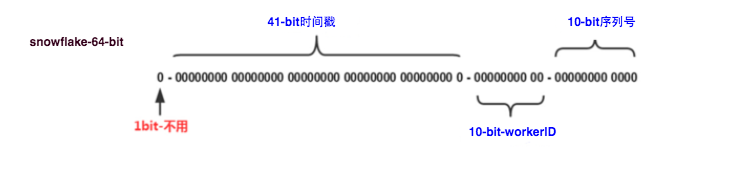
优点
- 毫秒数在高位,自增序列在低位,ID趋势递增。
- 以服务方式部署,可以做高可用。
- 根据业务分配bit位,灵活。
缺点
- 每台机器的时钟不同,当时钟回拨可能会发生重复ID。
- 当数据量大时,需要对ID取模分库分表,在跨毫秒时,序列号总是归0,会发生取模后分布不均衡。
2.3、基于数据库Flickr方案
这个方案的思路时采用了MySQL自增长ID的机制(auto_increment auto_increment_offset)。
通过使用以下SQL获取不同的ID:
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
在分布式系统中,多部署几台Mysql,每台机器的初始值不同,步数与机器数量相等。
假设部署N台机器,步数为N,每台机器初始值依次为:0、1、2...N-1,架构如下:
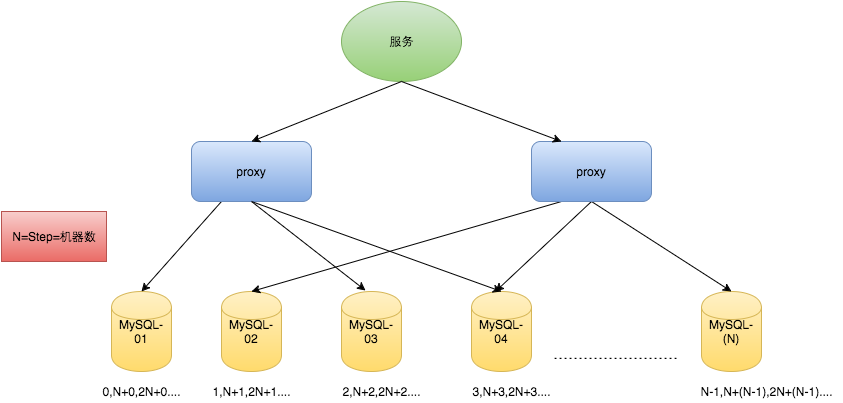
优点
- 简单,利用现有数据库架构。
- ID自增
缺点
- 依赖DB,配置主从复制可以增加可用性,但是当主从切换时可能会导致ID重复。
- 水平扩展困难,因为步数与机器数相同。
- 每次获取ID都需要读写数据库。
2.4、基于Redis生成
基于redis的lua也可以做Flickr方案,生成的ID为64位:
- 41bit存放时间(毫秒)
- 12bit存放逻辑分片ID
- 10bit存放自增长ID.
最终ID:((second * 1000 microSecond / 1000) << (12 10)) (shardId << 10) seq;
也可以直接使用INCR或者HINCRBY来做ID生成方案,因为Redis的单线程原子性,性能也很不错。
优点
- ID递增
- 性能好
缺点
- 需要依赖Redis。
- 需要考虑Reids宕机等问题。
3、开源产品
3.1、百度uid-generator
uid-generator是基于Twitter开源的snowflake算法实现,需要依赖Mysql。
Github: baidu/uid-generator
具体文档参考Github。
3.2、美团Leaf
Leaf——美团点评分布式ID生成系统
Github: Meituan-Dianping/Leaf
支持号段模式与snowflake模式。
3.3、小米chronos
Github: XiaoMi/chronos
Chronos依赖ZooKeeper,ChronosServer运行时会启动一个Thrift服务器。
参考
【分布式全局ID】细聊分布式ID生成方法
ID生成器,Twitter的雪花算法(Java)
Leaf——美团点评分布式ID生成系统
万亿级调用系统:微信序列号生成器架构设计及演变
使用Redis实现高并发分布式序列号生成服务
分布式ID方案有哪些以及各自的优劣势,我们当如何选择
分布式ID生成器解决方案
分布式全局序列ID方案之Redis优化方案
[分布式唯一ID极简教程](http://baijiahao.baidu.com/s?id=1584913615817222458

 浙公网安备 33010602011771号
浙公网安备 33010602011771号