
OO第一单元总结
第一单元总结
第一次作业
ULM
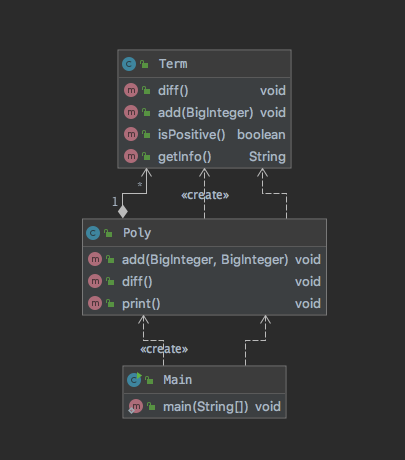
设计分析
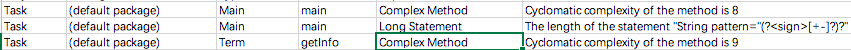
在这里我们可以看到有两个复杂方法和一个长表达式。
长表达式对应着一个正则表达式,我们可以通过将其划分成小表达式再拼接来将其简化。
在Main中的复杂表达式是对的正则表达式提取出的结果进行解析,而Term的toString函数也是要包含所有情况,所以目前还没有想到化简的方法。
功能实现
在主类中利用正则表达式对输入进行解析,将输入内容转换成Term类对象存入一个Poly对象之中。再利用Poly对象的diff()方法对存入Poly的各个Term对象逐一调用Term类的diff()方法得到求导后的结果。最后将结果转化成字符串进行输出。
bugs与发现bugs
第一次并没有找到别人程序中的bug,很失败。我认为我没能成功找出别人的bug在于过分依赖基于随机生成自动化测试程序。如果可以阅读以下别人的代码,或是多测试一些边界条件,效果应该会好很多。
心得体会
由于第一次作业的复杂性不高,所以我除了主函数以外只建立了两个类。并没有建立继承关系,也没有实现接口的设计,所以在第二次作业在此基础上要进行相应的扩充。其次由于对正则表达式的解析是在主类里面进行的,所以导致主类很长。对于输入可以放在一个单独的parse类中进行集中处理,是的主类更简洁。
第二次作业
UML

从UML中我们可以看到,这一次我建立了一个Poly接口来统一管理各种项。事实上,我们可以把Power、Const、Triangle、Mult、Add进行进一步的划分。其中Power、Const、Triangle属于单项式,Mult和Add属于多项式。我这次并没有再建两个类或者接口来进行分别管理的原因是感觉没有必要。由于第二次作业中表达式的层次较浅,所以在我的实现中Add对象管理的只可能是Mult对象,而各个Mult对象下管理的则一定是Power、Const和Triangle对象。即使Mult里面只存放了一个Const对象,这种结构也是不会改变的。在我的程序的其他地方也不会就是否是单项式还是多项式进行判读,所以就没有再对这些类进行划分。但从可扩展性和层次的抽象方面,对Poly进行进一步的抽象是更好的设计。
设计分析

从分析报告中我们可以看到有一个Cyclic dependency,因为我在Triangle求导的时候返回的是一个Mult类对象;一个Scattered Functionality是因为我没有对Mult和Add进行更进一步的抽象。
而且我们可以看到method相比较上次增加了非常多,从10个直接增加到了75个,代码量也从100多增加到了825。但其实功能上并没有变得非常复杂,这些代码和方法的增加主要是因为设计结构的改变,为了减少耦合度、层次的抽象还有底层相似的类增多而导致的。
功能实现
在第二次作业中利用了树来存储多项式,由于这次表达式层次较浅,所以并没有很明显的优势。并且在本次作业中对于输入的处理单独放置在了Parser类中,并且利用了工厂模式来创建对象,使得程序各个模块之间耦合度更低。
一种可能的化简算法
在本次作业中对于三角函数的化简是优化输出的主要方式。由于到最后也没有解决优化类中的bug,所以在程序中并没有实装。所以在这里对我的优化算法进行一个简单的说明,以 满足口嗨的欲望 弥补遗憾。
算法的主要依据是虽然三角函数的变化很多,但是一个三角函数的变换公式在化为齐次式后形式是唯一确定的,所以想以此为突破口进行化简。对于倍角公式也可以尝试进行相似的操作进行化简。
为简化过程,我们仅对三角函数组成的多项式进行讨论。对于第二次作业中的表达式化简,主要依靠的是(sin^2 + cos2)n = 1 这个式子。
我们记为C(n) = (sin^2 + cos2)n。对于这个式子的应用可以分为如下两种情况:被化简式为齐次、被化简式为非齐次。
对于齐次的式子U,我们先提取公因式,得到其中非公因式部分F。对于非公因式部分进行化简,设sin次数 + cos次数 = n。我们令D = F - k*C(n) + k (k为一常数)。若D的项数小于等于U的项数,我们便将公因式合并回来进行字符串长短的判断,再进行下一轮化简。再下一轮化简中我们可以舍弃上次化简中遗留的最高次部分,因为这部分已经不可能再进行简化了。所以每轮化简后,待处理的项一定是减少的。
对于非齐次的式子U‘,对U中系数小于最高项系数的项乘以相应的C(m)使其次数等于最高项次数,最终使U‘变为齐次式。
当然我们并不能确定哪些项组合进行化简是最好的,这时我们就需要利用DFS确定项的组合。
这种方法的一个优点是不用担心DFS爆栈的问题,但是对于非齐次式变齐次式我们需要限制m的大小,DFS搜索的时间复杂度也很高,需要进行一定的剪枝。当然,我并没有实装这个算法,所以若有错误,望大家指正。
bugs与发现bug
本次作业中我成功的找到了三个人的bug。这次能找到bug其中一个是依赖自动测试跑出来的,运气比较好。另外两个是我在阅读了别人的代码后,发现了他们在处理前导零的时候有问题,才成功的找到了他们的bug。
心得体会
在第二次作业中,我运用了树状结构管理表达式,实现了Poly接口,利用了多态特性。并且应用了工厂模式创建对象,感觉是这几次作业中结构写的比较好的一次。但是还是有很多不足的地方,比方说表达式的进一步抽象和表达式的优化。
第三次作业
UML

设计分析
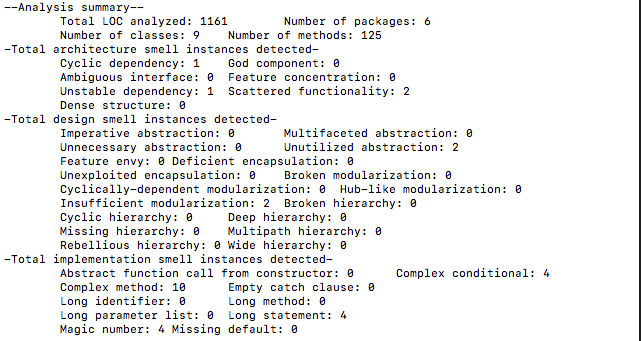
我们可以看到,代码中还是有一些问题。这次方法量增加了50个,代码量却没有增加太多。这是因为这次基本上沿用了上次的架构,只是在上次的基础上,在类中增加了很多小方法,有的方法甚至只有三四行,所以代码量倒是没有增加很多。
功能实现
由于这次的架构没有改变太多,所以实现方法与第二次基本相同,只是增加了一些递归式的调用。最主要的改变在于,这次无法利用大的正则表达式来完整输入的解析。我的方法是将输入的字符串进行递归划分,最终找到单一的一项再利用正则表达式提取信息。
bugs与发现bug
这次我只发现了别人一个bug,依旧是依靠自动测试得出的。我发现依赖随机的自动测试是一个很差的习惯。如果下次作业有时间的话,我应该尝试建立一个树状结构来进行测试样例的手动构造或是自动构造,这样就可以有效避免随机测试测不一些边界情况的发生。
这次我的程序中也出现了两个bug,一个是对于(1我的程序会抛出异常,另一个是合并同类项的问题。前者发生的原因,一是我的测试不够,二是我在写代码的时候更多的是考虑正确的情况下会是什么情况,而没有考虑如果出现非法输入的时候我的程序还能否顺利运行下去。后者的发生是因为我没有考虑清楚边界情况的发生。
事实上我发现,非常非常多的bug都是发生在一种单一的或者说是极端的情况下的。而随机测试生成这种测试样例几乎是不可能的。所以我认为在设计复杂程序的时候,随机测试是在浪费时间,应该彻底摒弃。
借鉴他人代码
在hack环节有幸阅读了大佬的代码,发现大佬使用了异常和try catch来进行wrongformat的判断。感觉这是一种非常好的设计。因为在我的代码中,我并没使用异常,这就导致了我的Factory只能作为parse的一个方法,而不能作为一个单独的类存在。下次我也要抛异常!
心得体会
在第三次作业中,由于沿用了前一次作业的大量代码,且前一次代码的可扩展性很差,所以修改了很多细节,这种修改是比较耗费精力的。说实话我宁肯重新写一遍代码,因为重写的时候会在脑海中复现整个处理的过程,对于程序的理解和把握都要比扩展上次代码来的高。但我想我们训练的目的肯定不是单纯的快速完成大量代码。提高程序的可扩展性和降低模块间的耦合度是很重要的一部分训练。所以在下一单元的练习中我需要从第一次作业开始就对程序的结构有一个很合理的划分,尽量多划分层次多拆分,让一块程序尽量完成一个简单的任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号