java实现哈希表
java实现哈希表
哈希表是一种数据结构,它可以快速的进行插入、查找、删除操作,无论数据量有多大,它都能把插入、查找和删除操作的时间复杂度降为O(1)级别。
哈希表是基于数组+链表进行实现的,数组创建后难以拓展,所以当哈希表中存储的数据过多时,会有很严重的性能下降。此时,我们可以通过扩展哈希表数组的长度来解决问题,但是扩展哈希表的长度是一个费时的过程。因此哈希表的设计人员必须根据实际的数据量来定义合适的哈希表数组的长度。
哈希表算法
如果我们知道一个数组的元素的索引,那么我们就可以通过索引在O(1)时间内获得元素。因此,如果我们能够将key对象与索引建立起一一对应的关系,那么我们就可以通过key对应的索引快速找到value值了,这个key对象转化为索引的算法就是哈希算法,这个索引叫做哈希码(散列码)。
基本数据类型的key值
- 当key为int,short,byte,char类型时,可以简单的将它们转化为int类型。
- 当key为long类型时,long型数据有64位,正好是int类型的两倍,我们可以执行异或操作将两部分结合,结果作为哈希码。这个过程称为折叠。
int hashCode = (int)(key^(key>>32));
//^是按位异或操作符,例如11110000^00000011得到11110011
- 当key为float类型时,使用Float.floatToIntBits(key)的返回值作为哈希码,floatToIntBits()函数返回一个int值,该int值的二进制数与float数据的二进制表示相同。
- 当key为double类型时,使用Double.doubleToLongBits方法转化为long值,然后再执行折叠操作,结果作为哈希码。
long bits = Double.doubleToLongBits(key);
int hashCode = (int)(bits^(bits>>32));
字符串类型的key值
当key位字符串类型时,我们有两种方法进行处理:
第一种方法比较直观,我们可以将所有字符串的Unicode码求和作为字符串的哈希码。(Unicode,也叫统一码、万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。)该方案只考虑了key的各个字母的个数,并没有考虑到字母的顺序。因此遇到具有相同字母的key值,将产生很多冲突,例如eat和ate。
因此产生了第二种方法,来将字母的顺序考虑在内。具体的方法为:
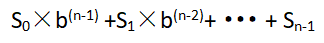
这里的S0为s.charAt(i)。这个表达式被称为多项式哈希码。使用针对多项式求值的Horner规则,可以如下高效的计算该多项式:
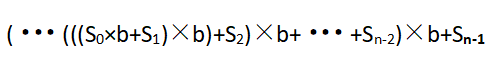
这个计算对于较长的字符串来说会导致溢出,但是Java会忽略算术溢出。应该选择一个合适的b值来最小化哈希冲突。查阅资料可以知道,b的较好取值为31,33,37,39,41,String类中,hashCode()被重写为采用b=31的多项式哈希码。
压缩哈希码
我们通过哈希算法计算出来的哈希码可能是一个很大的整数,超出了哈希表数组索引的范围,所以我们需要将它缩小到合适的范围。假设哈希表的数组长度为N。将一个整数缩小到0~N-1的方法通常是:
index = hashCode % N;
理论情况下,为了保证索引均匀展开,应该为N选择一个素数。然而,选择一个大的素数将很耗时。Java API中java.util.HashMap的实现,N采用16作为初始值,每次reHash将N扩大一倍。这样做具有合理性。当N为2的整数幂时,可以通过&运算来压缩哈希码,位运算比乘、除、取余操作要快很多,可以提高哈希表的性能,如下所示:
index = hashCode & (N-1);
&是一个按位AND操作符,如果两个二进制数的相同位都为1,那么结果中的对应位也为1。例如,假如N=4,hashCode = 7,那么index = hashCode & (N-1) = 0111 & 0011 = 0011 转换成十进制就是3,结果和7%4是一样的。
为了保证哈希表中的元素是均匀分布的,java.util.HashMap中为主哈希函数增加了一个补充的哈希函数,该函数定义为:
private static void supplementalHash(int h){
h ^= (h>>>20)^(h>>>12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
所以完整的哈希函数如下定义:
h(hashCode) = supplementalHash(hashCode) & (N-1);
补充的哈希函数避免了两个低位相同的数之间的冲突,比如10101000 & 00001111 和 11111000 & 00001111所得到的结果都是1000。使用补充的哈希函数将减少这种冲突。
自定义一个简单的哈希表
我们使用int类型作为key值,String类型作为value值,来实现<k,v>对的插入、查找和删除操作,以及reHash(哈希表的拓展)操作。
- step1:完成MyHashMap数据结构
我们在src源文件下新建一个包,命名为dataStructure,然后新建类MyHashMap,写入以下代码:
package dataStructure;
public class MyHashMap {
Node[] memo ;
int count ; //哈希表中元素个数;
/*
* 无参构造方法
* 此处将MyHashMap默认的初始容量为4,并没有设置最大容量,所以当遇到整数溢出/内存不够时,会出错。
*/
public MyHashMap() {
count = 0;
memo = new Node[4];
}
/*
* 添加一个新的<k,v>对,到哈希表中。
* int类型的数据通过哈希函数还是它本身,所以就直接用int值作为哈希码。
* 这里压缩哈希码使用了取模运算,此算法并不高效。当哈希表长度为2的整数次幂时,可以使用 哈希值 &(数组长度-1)来压缩哈希码。
* 当多个key值算出的索引相同时,使用链表来处理哈希冲突,将新插入的节点作为链表的头节点。
*/
public void put(int k , String v) {
int index = k % memo.length;
Node node = new Node(k,v);
node.next = memo[index];
memo[index ] = node;
count++;
//当元素数目为哈希表大小的2倍时,增大哈希表的大小。
if(count>memo.length*2) {
reHash();
}
}
/*
* 返回索引为k的value值
*
*/
public String get(int k) {
int index = k % memo.length;
Node node = memo[index];
while(node!=null) {
if(node.data.k == k) {
return node.data.v;
}
node = node.next;
}
return null;
}
/*
* reHash方法:将哈希表的数组长度扩展为原来的2倍
* 新建一个长度为原来2倍的新数组,遍历老数组,将老数组中的所有节点逐个插入到新数组中。
*/
private void reHash() {
Node[] newMemo = new Node[memo.length*2];
for (int i = 0; i < memo.length; i++) {
Node node = memo[i];
while(node!=null) {
int index = node.data.k % newMemo.length;
Node tNode = new Node(node.data);
tNode.next = newMemo[index];
newMemo[index ] = tNode;
node = node.next;
}
}
memo = newMemo;
}
//返回哈希表中元素的个数
public int size() {
return count;
}
/*
* remove方法,将key=k的元素移出哈希表
* 计算出索引,遍历索引处的链表,逐个比对key值,找到相同的值时返回value值
*/
public boolean remove(int k) {
int index = k % memo.length;
Node node = memo[index];
if(node.data.k==k) { //头节点为要移除的节点
if(memo[index].next!=null) {
memo[index] = memo[index].next;
}else {
memo[index] = null;
}
count--;
return true;
}
Node preNode = node;
node = node.next;
while(node!=null) {
if(node.data.k == k) {
preNode.next = node.next;
count--;
return true;
}
node = node.next;
}
return false;
}
//返回哈希表中数组的长度
public int getLength() {
return memo.length;
}
}
class Node{
Data data;
Node next;
public Node(Data data) {
this.data = data;
}
public Node(int k , String v) {
Data data = new Data(k, v);
this.data=data;
}
public Data getData() {
return data;
}
}
/**
* key值为int类型
* value为String
*/
class Data{
int k;
String v;
public Data(int k,String v) {
this.k = k ;
this.v = v;
}
}
- step2:测试MyHashMap
在src下新建package,命名为testHash,再新建类TsetMyHash,写入以下代码:
package test;
import dataStructure.MyHashMap;
public class TsetMyHash {
public static void main(String[] args) {
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1,"value1");
myHashMap.put(2,"value2");
myHashMap.put(3,"value3");
myHashMap.put(4,"value4");
myHashMap.put(5,"value5");
myHashMap.put(6,"value6");
myHashMap.put(7,"value7");
myHashMap.put(8,"value8");
myHashMap.put(9,"value9");
myHashMap.put(10,"value10");
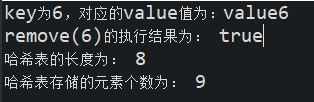
System.out.println("key为6,对应的value值为:"+ myHashMap.get(6));
boolean flag = myHashMap.remove(6);
System.out.println("remove(6)的执行结果为: "+flag );
System.out.println("哈希表的长度为: " + myHashMap.getLength());
System.out.println("哈希表存储的元素个数为: " + myHashMap.size());
}
}
执行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号